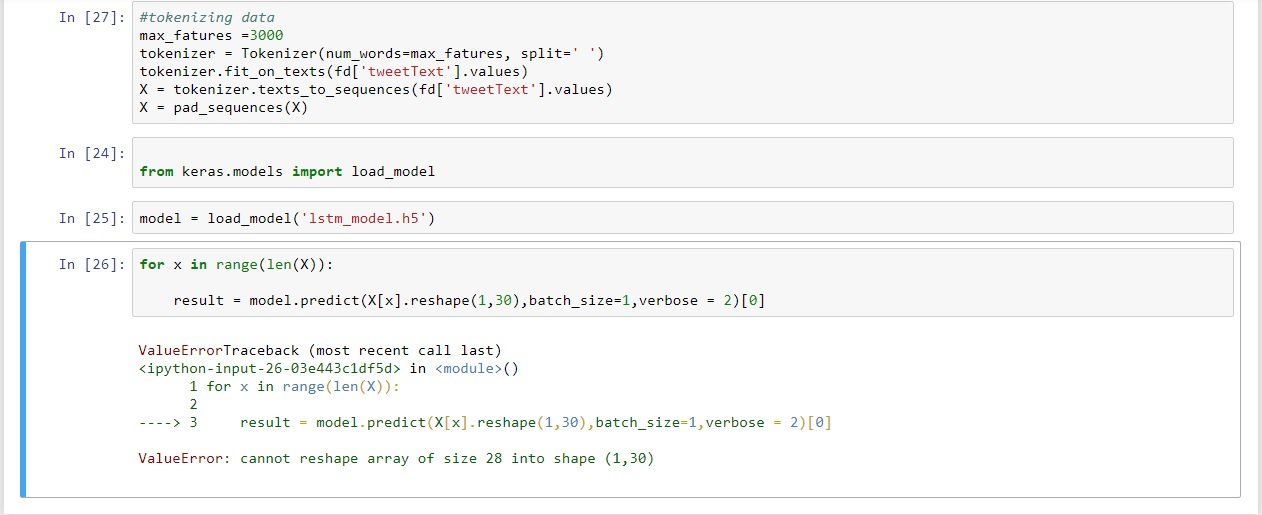
Ошибка при преобразовании входного токенизированного текста, предсказывающая настроения в течение последнего времени.
Я новичок в нейронной сети и изучаю его применение в области анализа текста, поэтому я использовал lstm rnn для приложения на python.
После обучения модели на наборе данных размером 20 000*1 (2000- это текст, а 1- настроение текста), я получил хорошую точность 99%, после чего я проверил модель, которая работала нормально (используя функция model.predict()).
Теперь, чтобы протестировать свою модель, я пытался дать случайные текстовые входные данные либо из кадра данных, либо из переменных, содержащих некоторый текст, но я всегда получаю ошибку с ошибкой изменения формы массива, где требуется, чтобы входные данные для модели rnn были размерность (1,30).
Но когда я повторно вводил данные обучения в модель для прогнозирования, модель работает абсолютно нормально, почему это происходит?
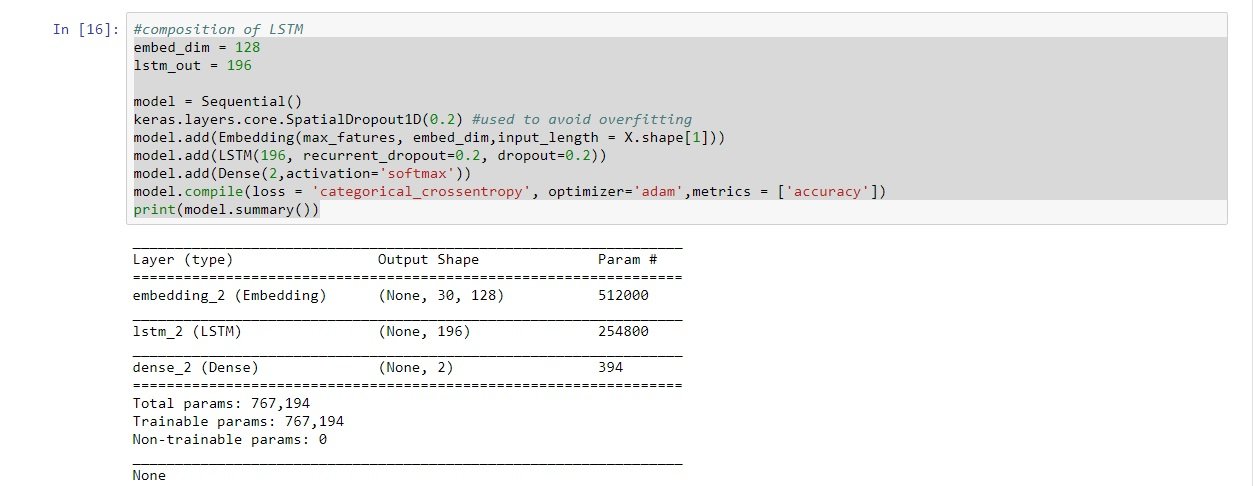
ссылка на изображение модели резюме
Я просто застрял здесь, и любые предложения помогут мне узнать больше о rnn, я прилагаю ошибку и код модели rnn с этим запросом.
Благодарю вас
С уважением
Тушар Упадхяй
import numpy as np
import pandas as pd
import keras
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM
from sklearn.model_selection import train_test_split
from keras.utils.np_utils import to_categorical
import re
data=pd.read_csv('..../twitter_tushar_data.csv')
max_fatures = 4000
tokenizer = Tokenizer(num_words=max_fatures, split=' ')
tokenizer.fit_on_texts(data['tweetText'].values)
X = tokenizer.texts_to_sequences(data['tweetText'].values)
X = pad_sequences(X)
embed_dim = 128
lstm_out = 196
model = Sequential()
keras.layers.core.SpatialDropout1D(0.2) #used to avoid overfitting
model.add(Embedding(max_fatures, embed_dim,input_length = X.shape[1]))
model.add(LSTM(196, recurrent_dropout=0.2, dropout=0.2))
model.add(Dense(2,activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam',metrics
= ['accuracy'])
print(model.summary())
#splitting data in training and testing parts
Y = pd.get_dummies(data['SA']).values
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size =
0.30, random_state = 42)
print(X_train.shape,Y_train.shape)
print(X_test.shape,Y_test.shape)
batch_size = 128
model.fit(X_train, Y_train, epochs = 7, batch_size=batch_size, verbose =
2)
validation_size = 3500
X_validate = X_test[-validation_size:]
Y_validate = Y_test[-validation_size:]
X_test = X_test[:-validation_size]
Y_test = Y_test[:-validation_size]
score,acc = model.evaluate(X_test, Y_test, verbose = 2, batch_size = 128)
print("score: %.2f" % (score))
print("acc: %.2f" % (acc))
pos_cnt, neg_cnt, pos_correct, neg_correct = 0, 0, 0, 0
for x in range(len(X_validate)):
result =
model.predict(X_validate[x].reshape(1,X_test.shape[1]),batch_size=1,verbose
= 2)[0]
if np.argmax(result) == np.argmax(Y_validate[x]):
if np.argmax(Y_validate[x]) == 0:
neg_correct += 1
else:
pos_correct += 1
if np.argmax(Y_validate[x]) == 0:
neg_cnt += 1
else:
pos_cnt += 1
print("pos_acc", pos_correct/pos_cnt*100, "%")
print("neg_acc", neg_correct/neg_cnt*100, "%")
1 ответ
Я получил решение моего вопроса, это был просто вопрос правильного ввода данных, спасибо! Код ниже для прогнозирования различных пользовательских вводов.
text=np.array(['you are a pathetic awful movie'])
print(text.shape)
tk=Tokenizer(num_words=4000,lower=True,split=" ")
tk.fit_on_texts(text)
prediction=model.predict(sequence.pad_sequences(tk.texts_to_sequences(text),
maxlen=max_review_length))
print(prediction)
print(np.argmax(prediction))