Смесь до не работает в JAGS, только если включен термин вероятности
Код внизу будет повторять проблему, просто скопируйте и вставьте ее в R.
Я хочу, чтобы среднее значение и точность составляли (-100, 100) в 30% случаев и (200, 1000) в 70% случаев. Думайте об этом как о выстроенных в a, b и p.
Таким образом, "выбор" должен составлять 1 30% времени и 2 70% времени.
На самом деле происходит то, что на каждой итерации pick равен 2 (или 1, если первый элемент p больше). Вы можете увидеть это в сводке, где квантили для 'pick', 'testa' и 'testb' остаются неизменными на протяжении всего времени. Самое странное, что если вы удалите петлю вероятности, выборка будет работать точно так, как задумано.
Я надеюсь, что это объясняет проблему, если нет, дайте мне знать. Это мой первый пост, поэтому я все испортил.
library(rjags)
n = 10
y <- rnorm(n, 5, 10)
a = c(-100, 200)
b = c(100, 1000)
p = c(0.3, 0.7)
## Model
mod_str = "model{
# Likelihood
for (i in 1:n){
y[i] ~ dnorm(mu, 10)
}
# ISSUE HERE: MIXTURE PRIOR
mu ~ dnorm(a[pick], b[pick])
pick ~ dcat(p[1:2])
testa = a[pick]
testb = b[pick]
}"
model = jags.model(textConnection(mod_str), data = list(y = y, n=n, a=a, b=b, p=p), n.chains=1)
update(model, 10000)
res = coda.samples(model, variable.names = c('pick', 'testa', 'testb', 'mu'), n.iter = 10000)
summary(res)
1 ответ
Я думаю, что у вас проблемы по нескольким причинам. Во-первых, данные, которые вы предоставили для модели (т.е. y) не является смесью нормальных распределений. В результате сама модель не нуждается в смешивании. Я бы вместо этого сгенерировал данные примерно так:
set.seed(320)
# number of samples
n <- 10
# Because it is a mixture of 2 we can just use an indicator variable.
# here, pick (in the long run), would be '1' 30% of the time.
pick <- rbinom(n, 1, p[1])
# generate the data. b is in terms of precision so we are converting this
# to standard deviations (which is what R wants).
y_det <- pick * rnorm(n, a[1], sqrt(1/b[1])) + (1 - pick) * rnorm(n, a[2], sqrt(1/b[2]))
# add a small amount of noise, can change to be more as necessary.
y <- rnorm(n, y_det, 1)
Эти данные больше похожи на то, что вы хотели бы предоставить для смешанной модели.
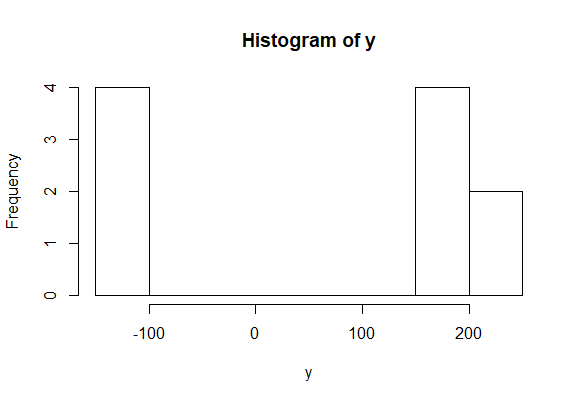
После этого я закодировал бы модель таким же образом, как я делал процесс генерации данных. Я хочу, чтобы какая-то индикаторная переменная прыгала между двумя нормальными распределениями. Таким образом, mu может измениться для каждого скаляра в y,
mod_str = "model{
# Likelihood
for (i in 1:n){
y[i] ~ dnorm(mu[i], 10)
mu[i] <- mu_ind[i] * a_mu + (1 - mu_ind[i]) * b_mu
mu_ind[i] ~ dbern(p[1])
}
a_mu ~ dnorm(a[1], b[1])
b_mu ~ dnorm(a[2], b[2])
}"
model = jags.model(textConnection(mod_str), data = list(y = y, n=n, a=a, b=b, p=p), n.chains=1)
update(model, 10000)
res = coda.samples(model, variable.names = c('mu_ind', 'a_mu', 'b_mu'), n.iter = 10000)
summary(res)
2.5% 25% 50% 75% 97.5%
a_mu -100.4 -100.3 -100.2 -100.1 -100
b_mu 199.9 200.0 200.0 200.0 200
mu_ind[1] 0.0 0.0 0.0 0.0 0
mu_ind[2] 1.0 1.0 1.0 1.0 1
mu_ind[3] 0.0 0.0 0.0 0.0 0
mu_ind[4] 1.0 1.0 1.0 1.0 1
mu_ind[5] 0.0 0.0 0.0 0.0 0
mu_ind[6] 0.0 0.0 0.0 0.0 0
mu_ind[7] 1.0 1.0 1.0 1.0 1
mu_ind[8] 0.0 0.0 0.0 0.0 0
mu_ind[9] 0.0 0.0 0.0 0.0 0
mu_ind[10] 1.0 1.0 1.0 1.0 1
Если бы вы предоставили больше данных, вы бы (в долгосрочной перспективе) имели переменную индикатора mu_ind принять значение 1 30% времени. Если бы у вас было более 2 дистрибутивов, вы могли бы использовать вместо dcat, Таким образом, альтернативный и более обобщенный способ сделать это будет ( и я заимствую из этого поста Джона Крушке):
mod_str = "model {
# Likelihood:
for( i in 1 : n ) {
y[i] ~ dnorm( mu[i] , 10 )
mu[i] <- muOfpick[ pick[i] ]
pick[i] ~ dcat( p[1:2] )
}
# Prior:
for ( i in 1:2 ) {
muOfpick[i] ~ dnorm( a[i] , b[i] )
}
}"
model = jags.model(textConnection(mod_str), data = list(y = y, n=n, a=a, b=b, p=p), n.chains=1)
update(model, 10000)
res = coda.samples(model, variable.names = c('pick', 'muOfpick'), n.iter = 10000)
summary(res)
2.5% 25% 50% 75% 97.5%
muOfpick[1] -100.4 -100.3 -100.2 -100.1 -100
muOfpick[2] 199.9 200.0 200.0 200.0 200
pick[1] 2.0 2.0 2.0 2.0 2
pick[2] 1.0 1.0 1.0 1.0 1
pick[3] 2.0 2.0 2.0 2.0 2
pick[4] 1.0 1.0 1.0 1.0 1
pick[5] 2.0 2.0 2.0 2.0 2
pick[6] 2.0 2.0 2.0 2.0 2
pick[7] 1.0 1.0 1.0 1.0 1
pick[8] 2.0 2.0 2.0 2.0 2
pick[9] 2.0 2.0 2.0 2.0 2
pick[10] 1.0 1.0 1.0 1.0 1
Ссылка выше включает еще больше априоров (например, Dirichlet перед вероятностями, включенными в Категориальное распределение).