Сокращение использования LUT в проекте Vivado HLS (криптосистема RSA с использованием умножения Монтгомери)
Вопрос / проблема для всех, кто имел опыт работы с Xilinx Vivado HLS и FPGA:
Мне нужна помощь в уменьшении числа использованных проектов в пределах HLS (то есть я не могу просто переделать проект в HDL). Я нацеливаюсь на Zedboard (Zynq 7020).
Я пытаюсь реализовать 2048-битный RSA в HLS, используя алгоритм умножения Монтгомери на множество слов Tenca-koc, показанный ниже (подробнее об алгоритме здесь):

Я написал этот алгоритм в HLS, и он работает в симуляции и C/RTL cosim. Мой алгоритм здесь:
#define MWR2MM_m 2048 // Bit-length of operands
#define MWR2MM_w 8 // word size
#define MWR2MM_e 257 // number of words per operand
// Type definitions
typedef ap_uint<1> bit_t; // 1-bit scan
typedef ap_uint< MWR2MM_w > word_t; // 8-bit words
typedef ap_uint< MWR2MM_m > rsaSize_t; // m-bit operand size
/*
* Multiple-word radix 2 montgomery multiplication using carry-propagate adder
*/
void mwr2mm_cpa(rsaSize_t X, rsaSize_t Yin, rsaSize_t Min, rsaSize_t* out)
{
// extend operands to 2 extra words of 0
ap_uint<MWR2MM_m + 2*MWR2MM_w> Y = Yin;
ap_uint<MWR2MM_m + 2*MWR2MM_w> M = Min;
ap_uint<MWR2MM_m + 2*MWR2MM_w> S = 0;
ap_uint<2> C = 0; // two carry bits
bit_t qi = 0; // an intermediate result bit
// Store concatenations in a temporary variable to eliminate HLS compiler warnings about shift count
ap_uint<MWR2MM_w> temp_concat=0;
// scan X bit-by bit
for (int i=0; i<MWR2MM_m; i++)
{
qi = (X[i]*Y[0]) xor S[0];
// C gets top two bits of temp_concat, j'th word of S gets bottom 8 bits of temp_concat
temp_concat = X[i]*Y.range(MWR2MM_w-1,0) + qi*M.range(MWR2MM_w-1,0) + S.range(MWR2MM_w-1,0);
C = temp_concat.range(9,8);
S.range(MWR2MM_w-1,0) = temp_concat.range(7,0);
// scan Y and M word-by word, for each bit of X
for (int j=1; j<=MWR2MM_e; j++)
{
temp_concat = C + X[i]*Y.range(MWR2MM_w*j+(MWR2MM_w-1), MWR2MM_w*j) + qi*M.range(MWR2MM_w*j+(MWR2MM_w-1), MWR2MM_w*j) + S.range(MWR2MM_w*j+(MWR2MM_w-1), MWR2MM_w*j);
C = temp_concat.range(9,8);
S.range(MWR2MM_w*j+(MWR2MM_w-1), MWR2MM_w*j) = temp_concat.range(7,0);
S.range(MWR2MM_w*(j-1)+(MWR2MM_w-1), MWR2MM_w*(j-1)) = (S.bit(MWR2MM_w*j), S.range( MWR2MM_w*(j-1)+(MWR2MM_w-1), MWR2MM_w*(j-1)+1));
}
S.range(S.length()-1, S.length()-MWR2MM_w) = 0;
C=0;
}
// if final partial sum is greater than the modulus, bring it back to proper range
if (S >= M)
S -= M;
*out = S;
}
К сожалению, использование LUT огромно. 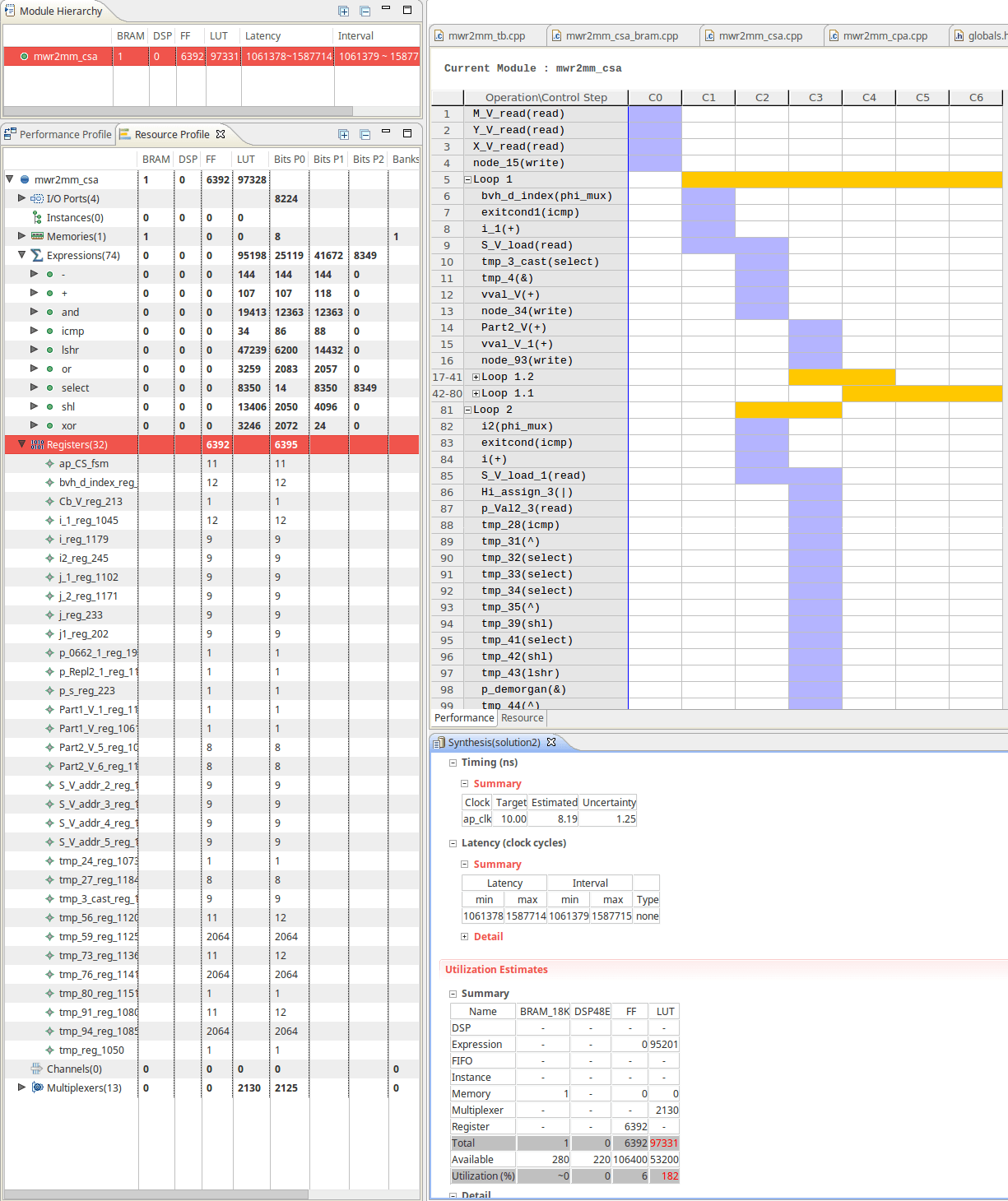
Это проблематично, потому что я должен быть в состоянии установить несколько из этих блоков на аппаратном уровне как подчиненные устройства Axi4.
Может ли кто-нибудь дать несколько советов относительно того, как я могу уменьшить использование LUT В КОНФИННАХ HLS?
Я уже пробовал следующее:
- Экспериментируя с разной длиной слова
- переключение входов верхнего уровня на массивы, чтобы они были BRAM (т.е. не использовали ap_uint<2048>, а вместо этого ap_uint foo[MWR2MM_e])
- Эксперименты со всеми видами директив: разделение на несколько встроенных функций, архитектура потока данных, ограничения ресурсов на lshr и т. Д.
Тем не менее, ничто не может существенно снизить использование LUT. Есть ли явно очевидный способ уменьшить использование, который очевиден для всех?
В частности, я видел статьи о реализации алгоритма mwr2mm, который ( использует только один блок DSP и один BRAM). Стоит ли пытаться реализовать это с помощью HLS? Или нет никакого способа, которым я мог бы фактически управлять ресурсами, на которые отображается алгоритм, не описывая его в HDL?
Спасибо за помощь.