Получить 3D-координаты из пикселя 2D-изображения, если известны внешние и внутренние параметры
Я делаю калибровку камеры от Цай Алго. Я получил внутреннюю и внешнюю матрицу, но как я могу восстановить трехмерные координаты из этой информации?
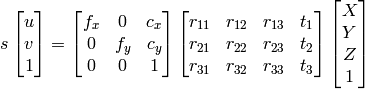
1) Я могу использовать исключение Гаусса для поиска X,Y,Z,W, и тогда точки будут X/W, Y/W, Z/W как однородная система.
2) Я могу использовать подход документации OpenCV: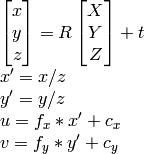
насколько я знаю u, v, R, t Я могу вычислить X,Y,Z,
Однако оба метода приводят к разным результатам, которые не являются правильными.
Что я делаю не так?
1 ответ
Если у вас есть внешние параметры, тогда у вас есть все. Это означает, что вы можете получить гомографию от сторонних разработчиков (также называемую CameraPose). Поза - это матрица 3х4, гомография - это матрица 3х3, H определяется как
H = K*[r1, r2, t], //eqn 8.1, Hartley and Zisserman
где K - собственная матрица камеры, r1 и r2 - первые два столбца матрицы вращения, R; т - вектор перевода.
Затем нормализуем деление всего на t3.
Что происходит с колонкой r3, разве мы не используем ее? Нет, потому что это избыточно, поскольку является перекрестным произведением двух первых столбцов позы.
Теперь, когда у вас есть гомография, спроектируйте точки. Ваши 2d баллы x, y. Добавьте их a z=1, чтобы они стали 3d. Спроектируйте их следующим образом:
p = [x y 1];
projection = H * p; //project
projnorm = projection / p(z); //normalize
Надеюсь это поможет.
Как хорошо сказано в комментариях выше, проецирование координат 2D-изображения в 3D "пространство камеры" по сути требует составления z-координат, так как эта информация полностью теряется в изображении. Одно из решений - присвоить фиктивное значение (z = 1) каждой из точек пространства 2D-изображения перед проецированием, как ответил Jav_Rock.
p = [x y 1];
projection = H * p; //project
projnorm = projection / p(z); //normalize
Одна интересная альтернатива этому фиктивному решению - обучить модель предсказывать глубину каждой точки перед перепроецированием в трехмерное пространство камеры. Я попробовал этот метод и добился большого успеха, используя Pytorch CNN, обученный трехмерным ограничивающим рамкам из набора данных KITTI. Был бы рад предоставить код, но его размещение здесь будет немного длинным.