Построение отдельных кривых по данным в R
У меня есть график, где для каждого значения х есть 2 значения Y. Данные также нелинейны. Сюжет выглядит так:
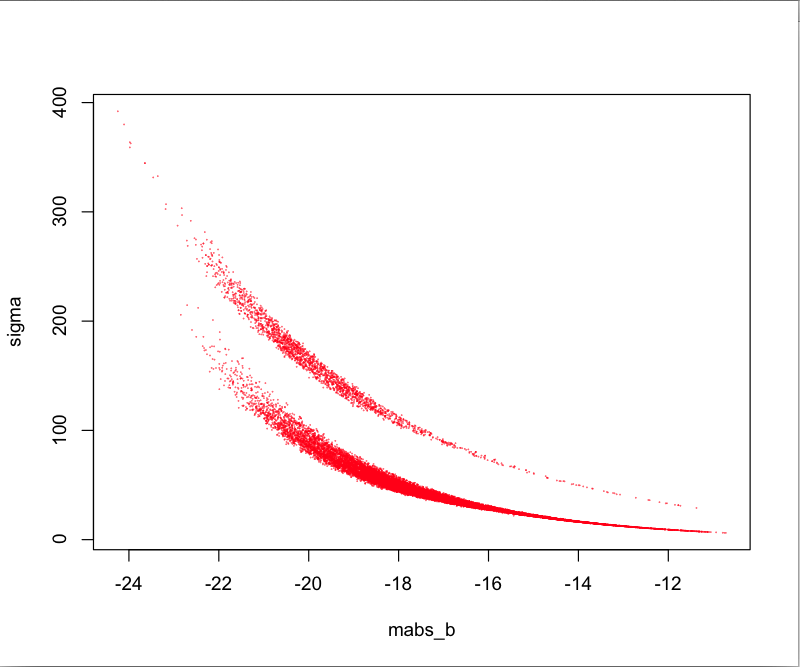
Теперь мой вопрос: я хочу подогнать кривые регрессии отдельно к двум из этих кривых (верхняя и нижняя). Я знаю, что это не ясный вопрос, поскольку у меня нет единой схемы идентификации, но я знаю, что система ответа может вести себя двумя разными способами для одного и того же входа (или почти одного и того же входа) случайным образом.
Файл данных можно найти здесь, здесь используются заголовки 'sigma' и 'mabs_b'
Резюме полного набора данных:
summary(data)
# id sigma L_gal M_gal flux
# Min. : 1 Min. : 6.214 Min. :1.481e+06 Min. :1.541e+08 Min. : 10.4
# 1st Qu.: 5118 1st Qu.: 28.438 1st Qu.:1.814e+08 1st Qu.:1.290e+10 1st Qu.: 196.7
# Median :10236 Median : 41.542 Median :6.725e+08 Median :3.684e+10 Median : 388.0
# Mean :10236 Mean : 56.599 Mean :3.151e+09 Mean :3.663e+11 Mean : 2551.5
# 3rd Qu.:15354 3rd Qu.: 65.445 3rd Qu.:2.467e+09 3rd Qu.:1.410e+11 3rd Qu.: 1227.3
# Max. :20471 Max. :391.988 Max. :3.810e+11 Max. :2.960e+13 Max. :733660.0
# fluxmax mabs_b flag cstar
# Min. : 1.191 Min. :-24.25 Min. : 0.000 Min. :0.0001578
# 1st Qu.: 5.801 1st Qu.:-18.77 1st Qu.: 0.000 1st Qu.:3.0000000
# Median : 10.111 Median :-17.36 Median : 0.000 Median :3.0000000
# Mean : 39.649 Mean :-17.33 Mean : 1.217 Mean :2.5267219
# 3rd Qu.: 26.313 3rd Qu.:-15.94 3rd Qu.: 3.000 3rd Qu.:3.0000000
# Max. :6600.280 Max. :-10.72 Max. :51.000 Max. :3.0000000
Выход из head(data,20):
subset_data = structure(list(id = 1:20, sigma = c(391.988, 379.985, 363.682,
358.969, 362.63, 344.544, 344.544, 331.482, 332.665, 302.539,
306.977, 287.416, 205.793, 303.279, 297.047, 273.719, 214.59,
268.891, 291.834, 191.926), L_gal = c(3.81e+11, 3.35e+11, 2.98e+11,
2.98e+11, 2.93e+11, 2.19e+11, 2.19e+11, 1.84e+11, 1.68e+11, 1.43e+11,
1.42e+11, 1.12e+11, 1.05e+11, 1.03e+11, 1.02e+11, 9.27e+10, 92017300000,
91078100000, 85536700000, 83359400000), M_gal = c(2.96e+13, 2.68e+13,
2.23e+13, 2.05e+13, 2.21e+13, 1.99e+13, 1.99e+13, 1.78e+13, 1.94e+13,
1.21e+13, 1.34e+13, 1.06e+13, 4.01e+12, 1.56e+13, 1.38e+13, 8.95e+12,
5.16e+12, 8.12e+12, 1.4e+13, 3.28e+12), flux = c(156286, 129987,
67801.2, 50110.3, 73118.6, 80827.2, 80827.2, 68568, 142348, 21194.6,
31081.9, 17414.4, 12121.3, 167441, 81709.3, 13920.7, 51775.8,
8185.93, 159998, 17393.7), fluxmax = c(6508.29, 4956.37, 2381.87,
2200.22, 2986.29, 2396.81, 2396.81, 2278.94, 4875.65, 854.856,
1264.36, 750.337, 19.7162, 6082.21, 724.639, 204.966, 281.601,
214.372, 6304.41, 182.002), mabs_b = c(-24.2475, -24.1079, -23.9807,
-23.9799, -23.9618, -23.6449, -23.6449, -23.4586, -23.3587, -23.1847,
-23.1745, -22.9178, -22.8463, -22.826, -22.8183, -22.7122, -22.7042,
-22.693, -22.6249, -22.5969), flag = c(35L, 0L, 0L, 0L, 3L, 2L,
2L, 2L, 3L, 2L, 0L, 2L, 35L, 2L, 3L, 35L, 2L, 2L, 0L, 2L), cstar = c(0.989659,
0.989581, 0.988048, 0.993796, 0.986398, 0.990529, 0.990529, 0.997505,
0.995231, 0.990121, 0.986176, 0.984495, 0.0007165, 0.987469,
0.0287568, 0.379966, 0.028632, 0.898742, 0.999391, 0.0286844)), .Names = c("id",
"sigma", "L_gal", "M_gal", "flux", "fluxmax", "mabs_b", "flag",
"cstar"), row.names = c(NA, 20L), class = "data.frame")
1 ответ
Есть две группы точек с промежутком между ними. Данные не содержат индикатор. Я предполагаю, что вы хотите определить априори, что точки, лежащие выше разрыва, должны быть в одной группе, а точки, лежащие ниже разрыва, должны быть в другой группе.
В таком случае, я боюсь, что обойти это невозможно без создания индикаторной переменной для двух групп самостоятельно.
К счастью, это можно сделать с помощью функции locator(). В этом случае функция работает, потому что между двумя группами существует явный разрыв. Осталось использовать locator(), чтобы проследить линию через пробел и проверить, какие значения сигмы лежат выше и ниже этой отслеживаемой линии.
Если у вас есть этот индикатор, вы можете использовать любой подходящий метод... но это вопрос другого поста (возможно, перекрестной проверки).
library('ggplot2')
d<-read.csv("SIS_TFFJ_all_sorted_R.csv")
uniq_sigma<-unique(d$sigma)
gap<-locator()
Вот содержимое пробела из моего следа:
> gap
$x
[1] -24.66446 -24.45990 -24.15305 -23.74391 -23.48820 -22.82336 -22.46536 -22.12442 -21.74938 -21.40843 -21.06749 -20.70950 -20.52198 -19.89123 -20.07875 -19.31162 -18.66382 -18.25469 -17.82851
[20] -17.07842 -16.39653 -15.64645 -15.08389 -14.24858 -13.44735 -12.40747 -11.19711
$y
[1] 346.67767 331.34710 315.20967 294.23100 277.28669 249.85305 229.68126 213.54382 194.17890 173.20024 159.48342 145.76660 136.08413 120.75357 123.98106 107.84362 92.51306 87.67183 79.60311
[20] 67.50003 58.62444 49.74885 44.10075 38.45265 30.38393 23.92896 17.47398
Теперь, когда у меня есть оценка линии, разделяющей две группы, я могу просто проверить, какие точки находятся выше и ниже линии.
d$x_pos<-cut(d$mabs_b, gap$x)
names(gap$y)<-unique(d$x_pos)
d$y_pos<-gap$y[d$x_pos]
d$cohort<-ifelse(d$sigma>d$y_pos,'upper','lower')
Наконец, построение графика с подгонкой модели с помощью geom_smooth(). Опять же, какую модель вы хотите подогнать, это совершенно другой вопрос... тот, который больше подходит для Cross Validated.
ggplot(data=d, aes(x=mabs_b, y=sigma, col=cohort, group=cohort))+geom_point()+geom_smooth(col='black')
