(Очень интригующее испытание) GraphSAGE: запрос на добавление функции | Инструкция по использованию функции: изучение возможности реализации асимметричного разделения функций узла
В настоящее время я работаю над реализацией GraphSage с DGL для приложения классификации промышленных узлов. Вот краткое описание моего сценария:
В моем приложении с каждым узлом графа связана около 21 функция. Однако не все эти функции можно использовать напрямую из-за возможности возникновения проблемы утечки функций. Поэтому мне нужно тщательно выбирать функции, которые будут использоваться в моей реализации.
Проще говоря, спрос следующий:
Для каждого узла при объединении его функции с соседним нам нужны только 3 собственных функции (выбранных из 21 функции) и все 21 функция для его соседа, чтобы сформировать обновленное вложение.
На первый взгляд все кажется довольно простым, не так ли? Все, что вам нужно сделать, это нарезать (замаскировать) такие функции, как: Изменить исходный код ниже: Из исходного кода:
def forward(self, graph, feat, is_first_layer: bool = False):
with graph.local_scope():
if isinstance(feat, tuple):
feat_src = self.feat_drop(feat[0])
feat_dst = self.feat_drop(feat[1])
else:
feat_src = feat_dst = self.feat_drop(feat)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
msg_fn = fn.copy_u("h", "m")
h_self = feat_dst
lin_before_mp = self._in_src_feats > self._out_feats
# Message Passing
if self._aggre_type == "mean":
graph.srcdata["h"] = (
self.fc_neigh(feat_src) if lin_before_mp else feat_src
)
graph.update_all(msg_fn, fn.mean("m", "neigh"))
h_neigh = graph.dstdata["neigh"]
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
self_feature_after_linear = self.fc_self(h_self)
rst = self_feature_after_linear + h_neigh
return self.activation(rst) if self.activation else rst
моему собственномуMaskedSAGEConv:
def sliced_rst(self, origin_tensor, feature_index_list) -> torch.Tensor:
...
# returns the sliced features
def forward(self, graph, feat, is_first_layer: bool = False):
with graph.local_scope():
if isinstance(feat, tuple):
feat_src = self.feat_drop(feat[0])
feat_dst = self.feat_drop(feat[1])
else:
feat_src = feat_dst = self.feat_drop(feat)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
msg_fn = fn.copy_u("h", "m")
h_self = feat_dst
lin_before_mp = self._in_src_feats > self._out_feats
# Message Passing
if self._aggre_type == "mean":
graph.srcdata["h"] = (
self.fc_neigh(feat_src) if lin_before_mp else feat_src
)
graph.update_all(msg_fn, fn.mean("m", "neigh"))
h_neigh = graph.dstdata["neigh"]
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
if is_first_layer == False:
self_feature_after_linear = self.fc_self(h_self)
rst = self_feature_after_linear + h_neigh
return self.activation(rst) if self.activation else rst
# if first layer, slice the feature(which is totally wrong!)
sliced_features = self.sliced_rst(
h_self, self.feature_index_list)
self_feature_after_linear = self.fc_self_fl(sliced_features)
self_feature_after_linear)
sliced_rst = self_feature_after_linear + h_neigh
return self.activation(sliced_rst) if self.activation else sliced_rst
Однако этот подразумевает неправильное понимание GraphSage. Поскольку изначально я думал, что все, что мне нужно сделать, это выбрать (нарезать) «собственный признак» при агрегировании в «первом слое» (раньше я думал, что процесс агрегирования должен быть входным->выходящим, но на самом деле это выходной->входящий ), но это совершенно неправильно. И позвольте мне сейчас прояснить проблему с моим пониманием GraphSage и DGL.
На самом деле, SAGECONV следует шаблону «Сначала выборка, затем агрегирование» , например: (цитата изображения с https://zhuanlan.zhihu.com/p/415905997)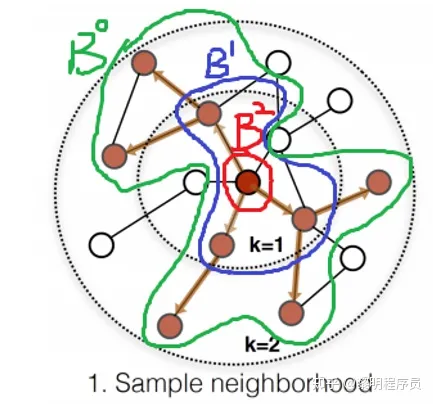
представленные на изображении, B2 — это узлы в нашей «выборочной партии», а затем мы отбираем их соседи B1 с 1 прыжком и B0 с 2 прыжками, мы используем:
sampler = NeighborSampler(
[10, 10, 10], # fanout for [layer-0, layer-1, layer-2]
prefetch_node_feats=["feat"],
prefetch_labels=["label"],
)
g = dataset.graph
train_dataloader = dgl.dataloading.DataLoader(
g,
train_nid,
sampler,
batch_size=1024,
shuffle=True,
drop_last=False,
num_workers=4,
)
...
with tqdm.tqdm(train_loader) as tq:
for step, (input_nodes, output_nodes, blocks) in enumerate(tq):
inputs = blocks[0].srcdata['feat'].to(self.device)
labels = blocks[-1].dstdata['label'].to(self.device)
#
# for block in blocks:
# print("block.srcdata[feat]", block.srcdata['feat'])
logits = self.model(blocks, inputs)
и мы можем наблюдать, что выбранные блоки:
blocks [Block(num_src_nodes=1819, num_dst_nodes=1797, num_edges=824), Block(num_src_nodes=1797, num_dst_nodes=1688, num_edges=790), Block(num_src_nodes=1688, num_dst_nodes=1024, num_edges=664)]
block.shape 3
So from the outter to the inner, we have:
Src 1819 -- B2
Dest 1797 -- B2 -> B1
----------------------
Src 1797 -- B1
Dest 1688 -- B1->B0
----------------------
Src 1688 -- B0
Dest 1024 -- B0 and this is what we call batch size
После выборки мы соответственно выполняем процесс Conv:
self.n_layers = n_layers
self.n_hidden = n_hidden
self.n_classes = n_classes
self.layers = nn.ModuleList()
self._feature_index_list = feature_index_list
# input layer
self.layers.append(MaskedSAGEConv(
in_feats * self.embeddings_dim,
n_hidden,
"mean",
feature_index_list=self._feature_index_list,
))
# hidden layers
for i in range(1, n_layers - 1):
self.layers.append(MaskedSAGEConv(
n_hidden,
n_hidden,
"mean",
feature_index_list=self._feature_index_list
))
# output layer
self.layers.append(MaskedSAGEConv(
n_hidden,
n_classes,
"mean",
feature_index_list=self._feature_index_list
))
...
def forward(self, blocks, in_feats):
h = self.embedding_all(in_feats)
h = h.double()
for i, (layer, block) in enumerate(zip(self.layers, blocks)):
if i == 0: # this is the wrong implementation!!!!!
h = layer(block, h, is_first_layer=True)
else:
h = layer(block, h)
# last layer does not need activation and dropout
if i != self.n_layers - 1:
h = self.activation(h)
h = self.dropout(h)
return h
вы можете просто рассматривать приведенный выше цикл for как:
h = MaskedSAGEConv(block[0],h)
h = MaskedSAGEConv(block[1],h)
h = MaskedSAGEConv(block[2],h)
мы возвращаемся к неправильному внедрению MaskedSAGEConv
def sliced_rst(self, origin_tensor, feature_index_list) -> torch.Tensor:
...
# returns the sliced features
def forward(self, graph, feat, is_first_layer: bool = False):
with graph.local_scope():
if isinstance(feat, tuple):
feat_src = self.feat_drop(feat[0])
feat_dst = self.feat_drop(feat[1])
else:
feat_src = feat_dst = self.feat_drop(feat)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
msg_fn = fn.copy_u("h", "m")
h_self = feat_dst
lin_before_mp = self._in_src_feats > self._out_feats
# Message Passing
if self._aggre_type == "mean":
graph.srcdata["h"] = (
self.fc_neigh(feat_src) if lin_before_mp else feat_src
)
graph.update_all(msg_fn, fn.mean("m", "neigh"))
h_neigh = graph.dstdata["neigh"]
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
if is_first_layer == False:
self_feature_after_linear = self.fc_self(h_self)
rst = self_feature_after_linear + h_neigh
return self.activation(rst) if self.activation else rst
# if first layer, slice the feature(which is totally wrong!)
sliced_features = self.sliced_rst(
h_self, self.feature_index_list)
self_feature_after_linear = self.fc_self_fl(sliced_features)
self_feature_after_linear)
sliced_rst = self_feature_after_linear + h_neigh
return self.activation(sliced_rst) if self.activation else sliced_rst
Вот ключевой момент
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
мы проверяем feat_dst и feat_src для каждого слоя, у нас будет
feat_src shape: torch.Size([1819, 168]) # 168 since 21feature each with 8 dim of embeddings
feat_dst shape: torch.Size([1797, 168])
h_self shape: torch.Size([1797, 168])
h_neigh shape: torch.Size([1797, 16]) # 16 is the hidden layer size in linear
sliced_features shape: torch.Size([1797, 24]) # which is wrong since I should not slice the 2-hop's node features, and 24 is because 3 features with 8 dims, returned by my impl of sliced_rst
self.fc_self_fl(sliced_features) shape: torch.Size([1797, 16]) # 16 since the
и для следующих двух слоев: он также будет "конвертироваться" так:
(1797,16)->(1688,16)->(1024,2) # 1024 for batch size and 2 for binary classifications
Итак, здесь вы можете увидеть проблему: мое требование => Для каждого узла используйте только 3 выбранные функции вместо всех 21 функции. И использовать все 21 функцию своего соседа, чтобы сформировать обновленное встраивание.
И дело в том, что я неправильно нарезал узел, поскольку правильное понимание таково: первый слой — это узлы из 2-х скачкового соседства, второй слой — это узлы из 1-х шагового соседства, а последний слой — это узлы из отобранная партия.
Однако, разобравшись с этим, я обнаружил, что чрезвычайно сложно замаскировать (нарезать) функции для каждого узла, поскольку
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
# combo with the linear layer
self.fc_self_fl(sliced_features) shape: torch.Size([1797, 16])
поскольку в самом внутреннем слое размер уже не 21*8, а 16, что является размером скрытого слоя в линейном слое, и невозможно разрезать объекты для каждого узла.
Кто-нибудь может мне с этим помочь? Или у dgl есть лучший способ получить доступ к функциям для каждого узла в выборочном пакете вместо этого типа внешнего-> внутреннего преобразования?