Проблемы с масштабированными прогнозами inverse_transform и y_test в многошаговом многовариантном LSTM
Я построил многоступенчатую многовариантную модель LSTM, чтобы предсказать целевую переменную на 5 дней вперед с 5-дневным ретроспективным анализом. Модель работает гладко (даже несмотря на то, что она нуждается в дальнейшем улучшении), но я не могу правильно инвертировать примененное преобразование, как только получу свои прогнозы. Я видел в Интернете, что существует множество способов предварительной обработки и преобразования данных. Я решил выполнить следующие шаги:
- Получение и очистка данных
df = yfinance.download(['^GSPC', '^GDAXI', 'CL=F', 'AAPL'], period='5y', interval='1d')['Adj Close'];
df.dropna(axis=0, inplace=True)
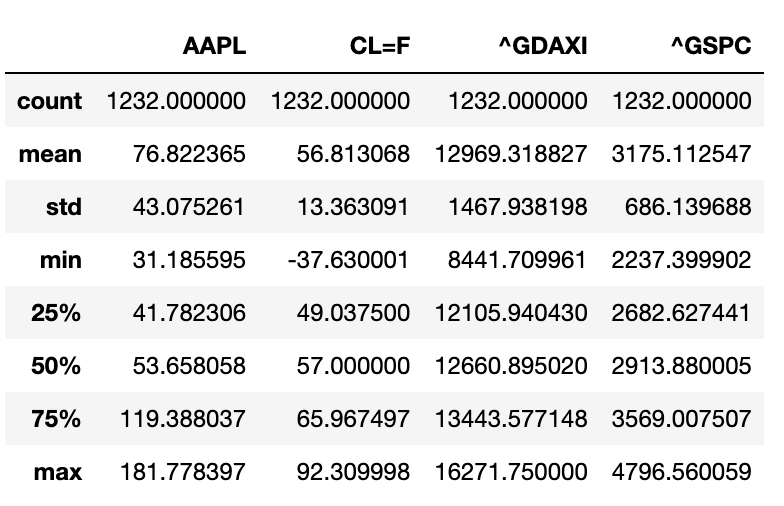
df.describe()
Таблица набора данных
- Разделите набор данных на поезд и тест
size = int(len(df) * 0.80)
df_train = df.iloc[:size]
df_test = df.iloc[size:]
- Масштабирование обучающих и тестовых наборов отдельно с помощью MinMaxScaler()
scaler = MinMaxScaler(feature_range=(0,1))
df_train_sc = scaler.fit_transform(df_train)
df_test_sc = scaler.transform(df_test)
- Создание 3D-временных рядов X и y, совместимых с моделью LSTM.
Я позаимствовал следующую функцию из этой статьи
def create_X_Y(ts: np.array, lag=1, n_ahead=1, target_index=0) -> tuple:
"""
A method to create X and Y matrix from a time series array for the training of
deep learning models
"""
# Extracting the number of features that are passed from the array
n_features = ts.shape[1]
# Creating placeholder lists
X, Y = [], []
if len(ts) - lag <= 0:
X.append(ts)
else:
for i in range(len(ts) - lag - n_ahead):
Y.append(ts[(i + lag):(i + lag + n_ahead), target_index])
X.append(ts[i:(i + lag)])
X, Y = np.array(X), np.array(Y)
# Reshaping the X array to an RNN input shape
X = np.reshape(X, (X.shape[0], lag, n_features))
return X, Y
#In this example let's assume that the first column (AAPL) is the target variable.
trainX,trainY = create_X_Y(df_train_sc,lag=5, n_ahead=5, target_index=0)
testX,testY = create_X_Y(df_test_sc,lag=5, n_ahead=5, target_index=0)
- Создание модели
def build_model(optimizer):
grid_model = Sequential()
grid_model.add(LSTM(64,activation='tanh', return_sequences=True,input_shape=(trainX.shape[1],trainX.shape[2])))
grid_model.add(LSTM(64,activation='tanh', return_sequences=True))
grid_model.add(LSTM(64,activation='tanh'))
grid_model.add(Dropout(0.2))
grid_model.add(Dense(trainY.shape[1]))
grid_model.compile(loss = 'mse',optimizer = optimizer)
return grid_model
grid_model = KerasRegressor(build_fn=build_model,verbose=1,validation_data=(testX,testY))
parameters = {'batch_size' : [12,24],
'epochs' : [8,30],
'optimizer' : ['adam','Adadelta'] }
grid_search = GridSearchCV(estimator = grid_model,
param_grid = parameters,
cv = 3)
grid_search = grid_search.fit(trainX,trainY)
grid_search.best_params_
my_model = grid_search.best_estimator_.model
- Получить прогнозы
yhat = my_model.predict(testX)
- Инвертировать преобразование прогнозов и фактических значений
Здесь начинаются мои проблемы, потому что я не уверен, куда идти. Я прочитал много руководств, но кажется, что эти авторы предпочитают применять MinMaxScaler() ко всему набору данных, прежде чем разбивать данные на обучение и тестирование. Я не согласен с этим, потому что в противном случае обучающие данные будут неправильно масштабированы с информацией, которую мы не должны использовать (т.е. с тестовым набором). Итак, я следовал своему подходу, но я застрял здесь.
Я нашел это возможное решение в другом сообщении, но оно не работает для меня:
# invert scaling for forecast
pred_scaler = MinMaxScaler(feature_range=(0, 1)).fit(df_test.values[:,0].reshape(-1, 1))
inv_yhat = pred_scaler.inverse_transform(yhat)
# invert scaling for actual
inv_y = pred_scaler.inverse_transform(testY)
На самом деле, когда я дважды проверяю последние значения цели из моего исходного набора данных, они не совпадают с инвертированной масштабированной версией testY.
Может кто-нибудь, пожалуйста, помогите мне в этом? Заранее большое спасибо за вашу поддержку!
1 ответ
Здесь можно было бы упомянуть две вещи. Во-первых, вы не можете произвести обратное преобразование того, чего не видели. Это происходит из-за того, что вы используете два разных масштабатора. NN будет прогнозировать значения в диапазоне Scaler 1, где не сказано, что это находится в диапазоне Scaler 2 (масштабируется на тестовых данных). Во-вторых, лучше всего поместить свой скейлер в тренировочный набор и использовать тот же скейлер (только преобразование) для тестовых данных. Теперь вы должны иметь возможность обратно преобразовать результаты теста. В-третьих, если масштабирование не работает, потому что тестовый набор имеет совершенно другие значения - например, это происходит с данными потоковой передачи в реальном времени, вам решать, как с этим справиться, например, мин-макс скалер будет давать значения> 1,0.