вычисление оценок внимания в внимании Bahdanau в тензорном потоке с использованием скрытого состояния декодера и вывода кодировщика
Этот вопрос относится к нейронному машинному переводу, показанному здесь: Neural Machine Translation.
self.W1 и
self.W2 инициализируются плотными нейронными слоями по 10 единиц каждый в строках 4 и 5 в
__init__ функция
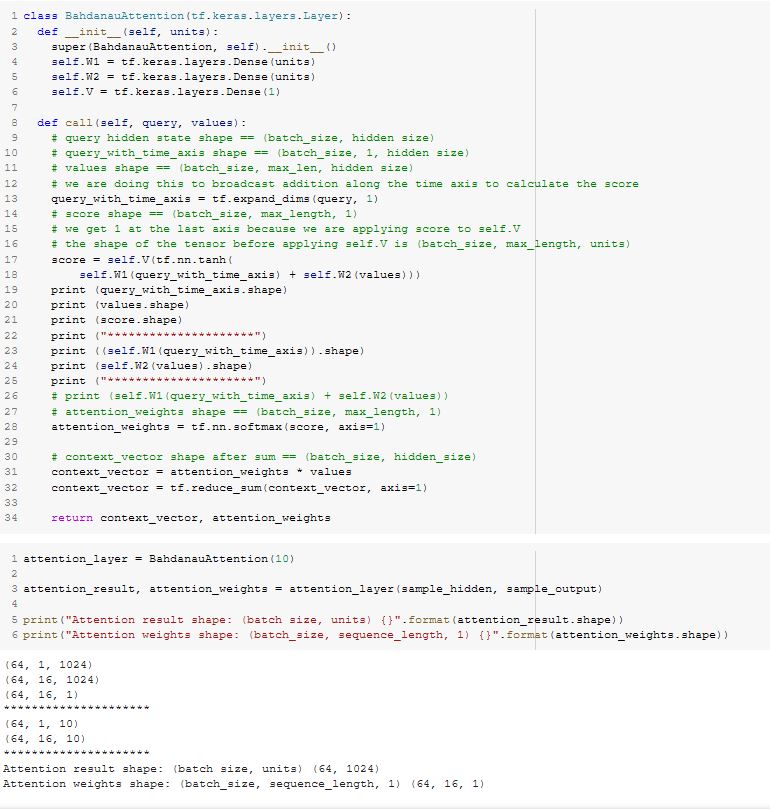
class BahdanauAttention
В прилагаемом изображении кода я не уверен, что понимаю нейронную сеть прямой связи, настроенную в строке 17 и строке 18. Итак, я разбил эту формулу на части. См. Строку 23 и строку 24.
query_with_time_axis входной тензор для
self.W1 и
values вводится в
self.W2. И каждый вычисляет функцию
Z = WX + b, и Z складываются вместе. Размеры суммированных тензоров равны
(64, 1, 10) и
(64, 16, 10). Я предполагаю случайную инициализацию веса для обоих
self.W1 и
self.W2 обрабатывается
Keras за кулисами.
Вопрос:
После сложения Z вместе возникает нелинейность (tanh) применяется для создания активации, и эта результирующая активация вводится на следующий уровень.
self.V, который представляет собой слой только с одним выходом и дает нам
score.
На этом последнем шаге мы не применяем функцию активации (tanh и т. Д.) К результату
self.V(tf.nn.tanh(self.W1(query_with_time_axis) + self.W2(values))), чтобы получить единственный вывод из этого последнего слоя нейронной сети.
Есть ли причина, по которой функция активации не использовалась на этом последнем шаге?
1 ответ
Вывод внимания формирует так называемые энергии внимания, то есть один скаляр для каждого вывода кодера. Эти числа складываются в вектор, и этот вектор нормализуется с помощью softmax, что дает распределение внимания.
Фактически, на следующем шаге применяется нелинейность - softmax. Если вы использовали функцию активации до softmax, вы только уменьшили бы пространство распределений, которое может выполнять softmax.