ValueError: ожидайте, что x будет непустым массивом или набором данных (создатель модели Tensor Flow lite на Collab)
Я следую этому руководству по созданию пользовательской модели с помощью TensorFlow lite Model Maker в Collab.
import pathlib
path = pathlib.Path('/content/employee_pics')
count = len(list(path.glob('*/*.jpg')))
count
data = ImageClassifierDataLoader.from_folder(path)
train_data, test_data = data.split(0.5)
У меня проблема с шагом 2:
model = image_classifier.create(train_data)
Я получаю сообщение об ошибке: ValueError: Ожидайте, что x будет непустым массивом или набором данных.
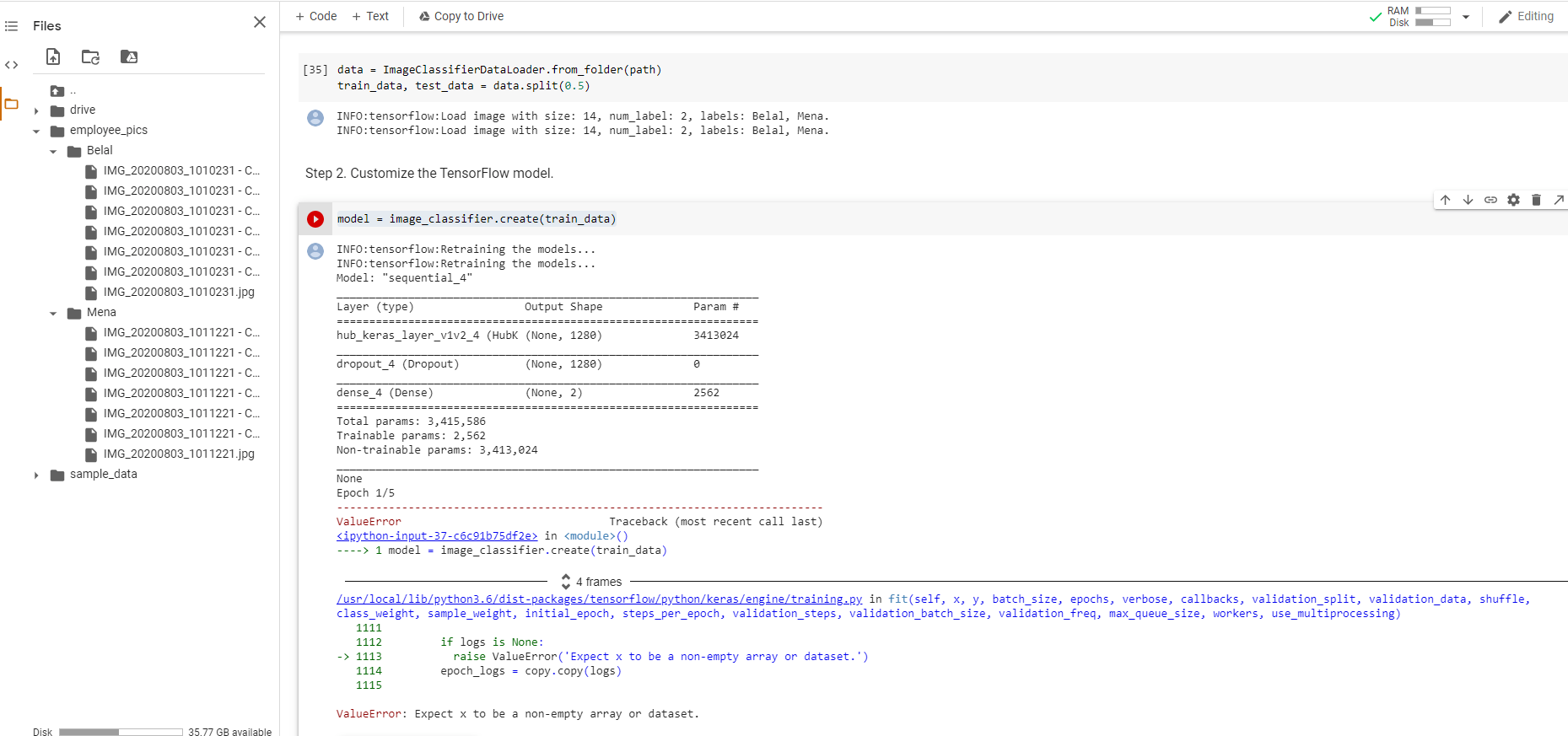
Я делаю что-то неправильно? Однако набор данных, представленный в примере, работает нормально. Почему?
3 ответа
Я только что сделал несколько ручных тестов. Не знаю точно, почему, но для этого двоичного классификатора, когда я увеличиваю объем данных, чтобы убедиться, что для обучения используются как минимум 16 изображений на метку, он начинает работать.
В вашем случае, поскольку вы разделяете поезд / тест с коэффициентом 0,5, вам нужно 32 изображения на этикетку. Не могли бы вы попробовать решить вашу проблему?
Эта ошибка вызвана тем, что размер обучающих данных меньше, чем batch_size что не допускается.
По умолчанию batch_size - 32, что означает, что количество обучающих изображений должно быть не менее 32. Нет необходимости подсчитывать количество изображений на этикетку, просто нужно убедиться, что общее количество обучающих изображений должно быть не менее 32.
Вам нужно выбрать одно из следующих решений, чтобы решить эту проблему.
- Задавать
batch_sizeменьше, чем размер обучающих данных, например:
image_classifier.create(train_data, batch_size=4)
- Увеличьте размер обучающих данных, добавив больше данных.
Была такая же ошибка:
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py", line 1110, in fit
raise ValueError('Expect x to be a non-empty array or dataset.')
ValueError: Expect x to be a non-empty array or dataset.
Сначала попробовал уменьшить размер партии. Если размер пакета больше, чем набор обучающих данных, то входной набор данных не создается и, следовательно, остается пустым. Но в моем случае это было не так.
Затем я попытался увидеть, где мой набор данных становится пустым. Моя первая эпоха прошла хорошо, а другая - нет. Кажется, мой набор данных был преобразован в процессе пакетной обработки.
classes = len(y.unique())
model = Sequential()
model.add(Dense(10, activation='relu',
activity_regularizer=tf.keras.regularizers.l1(0.00001)))
model.add(Dense(classes, activation='softmax', name='y_pred'))
opt = Adam(lr=0.0005, beta_1=0.9, beta_2=0.999)
BATCH_SIZE = 12
train_dataset, validation_dataset =set_batch_size(BATCH_SIZE,train_dataset,validation_dataset)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics['accuracy'])
model.fit(_train_dataset, epochs=10,validation_data=_validation_dataset,verbose=2, callbacks=callbacks)
Решение для этого случая: обновлено избыточное обновление набора данных поезда и проверки, разделив его на пакет, присвоив другое имя.
До:
train_dataset, validation_dataset = set_batch_size(BATCH_SIZE, train_dataset, validation_dataset)
После:
_train_dataset, _validation_dataset = set_batch_size(BATCH_SIZE, train_dataset, validation_dataset)
classes = len(y.unique())
model = Sequential()
model.add(Dense(10, activation='relu',activity_regularizer=tf.keras.regularizers.l1(0.00001)))
model.add(Dense(classes, activation='softmax', name='y_pred'))
opt = Адам (lr = 0,0005, beta_1 = 0,9, beta_2 = 0,999)
BATCH_SIZE = 12
_train_dataset, _validation_dataset =set_batch_size(BATCH_SIZE, train_dataset, validation_dataset)model.compile(loss='ategorical_crossentropy', optimizer = opt, metrics = ['
precision '])model.fit(_train_podatase = [' точность »])model.fit (_train_podatation = 2, обратные вызовы = обратные вызовы)
Полезные ссылки: https://code.ihub.org.cn/projects/124/repository/commit_diff?changeset=1fb8f4988d69237879aac4d9e3f268f837dc0221