Azure ML PipelineData с DataTransferStep возвращает файл размером 0 байт.
Я создаю конвейер машинного обучения Azure с помощью пакета SDK для Python azureml. Конвейер вызывает PythonScriptStep, который хранит данные в хранилище блобов рабочей области рабочей области AML.
Я хотел бы расширить конвейер для экспорта данных конвейера в озеро данных Azure (Gen 1). Насколько я понимаю, подключение вывода PythonScriptStep напрямую к Azure Data Lake (Gen 1) не поддерживается в Azure ML. Поэтому я добавил в конвейер дополнительный DataTransferStep, который принимает выходные данные PythonScriptStep в качестве входных данных непосредственно в DataTransferStep. Согласно документации Microsoft это должно быть возможно.
Пока я создал это решение, только в результате получается файл размером 0 байт в озере данных 1-го поколения. Я думаю, что output_export_blob PipelineData неправильно ссылается на test.csv, и поэтому DataTransferStep не может найти ввод. Как я могу правильно соединить DataTransferStep с выходом PipelineData из PythonScriptStep?
Пример, которому я следовал:https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/machine-learning-pipelines/intro-to-pipelines/aml-pipelines-with-data-dependency-steps.ipynb
pipeline.py
input_dataset = delimited_dataset(
datastore=prdadls_datastore,
folderpath=FOLDER_PATH_INPUT,
filepath=INPUT_PATH
)
output_export_blob = PipelineData(
'export_blob',
datastore=workspaceblobstore_datastore,
)
test_step = PythonScriptStep(
script_name="test_upload_stackru.py",
arguments=[
"--output_extract", output_export_blob,
],
inputs=[
input_dataset.as_named_input('input'),
],
outputs=[output_export_blob],
compute_target=aml_compute,
source_directory="."
)
output_export_adls = DataReference(
datastore=prdadls_datastore,
path_on_datastore=os.path.join(FOLDER_PATH_OUTPUT, 'test.csv'),
data_reference_name='export_adls'
)
export_to_adls = DataTransferStep(
name='export_output_to_adls',
source_data_reference=output_export_blob,
source_reference_type='file',
destination_data_reference=output_export_adls,
compute_target=adf_compute
)
pipeline = Pipeline(
workspace=aml_workspace,
steps=[
test_step,
export_to_adls
]
)
test_upload_stackru.py
import os
import pathlib
from azureml.core import Datastore, Run
parser = argparse.ArgumentParser("train")
parser.add_argument("--output_extract", type=str)
args = parser.parse_args()
run = Run.get_context()
df_data_all = (
run
.input_datasets["input"]
.to_pandas_dataframe()
)
os.makedirs(args.output_extract, exist_ok=True)
df_data_all.to_csv(
os.path.join(args.output_extract, "test.csv"),
index=False
)
1 ответ
Пример кода очень полезен. Спасибо за это. Вы правы, может сбивать с толкуPythonScriptStep -> PipelineData. Работает изначально даже безDataTransferStep.
Я не знаю на 100%, что происходит, но подумал, что выложу несколько идей:
- Ваш
PipelineData,export_blob, содержать файл "test.csv"? Я бы проверил это перед устранением неполадокDataTransferStep. Вы можете проверить это с помощью SDK или, что проще, с помощью пользовательского интерфейса.- Перейдите на страницу PipelineRun, щелкните значок
PythonScriptStepобсуждаемый. - На странице "Выходы + журналы" есть раздел "Выходы данных" (который изначально загружается медленно).
- Откройте его, и вы увидите выходные данные PipelineDatas, затем нажмите "View Output".
- Перейдите по указанному пути на портале Azure или в обозревателе хранилищ Azure.
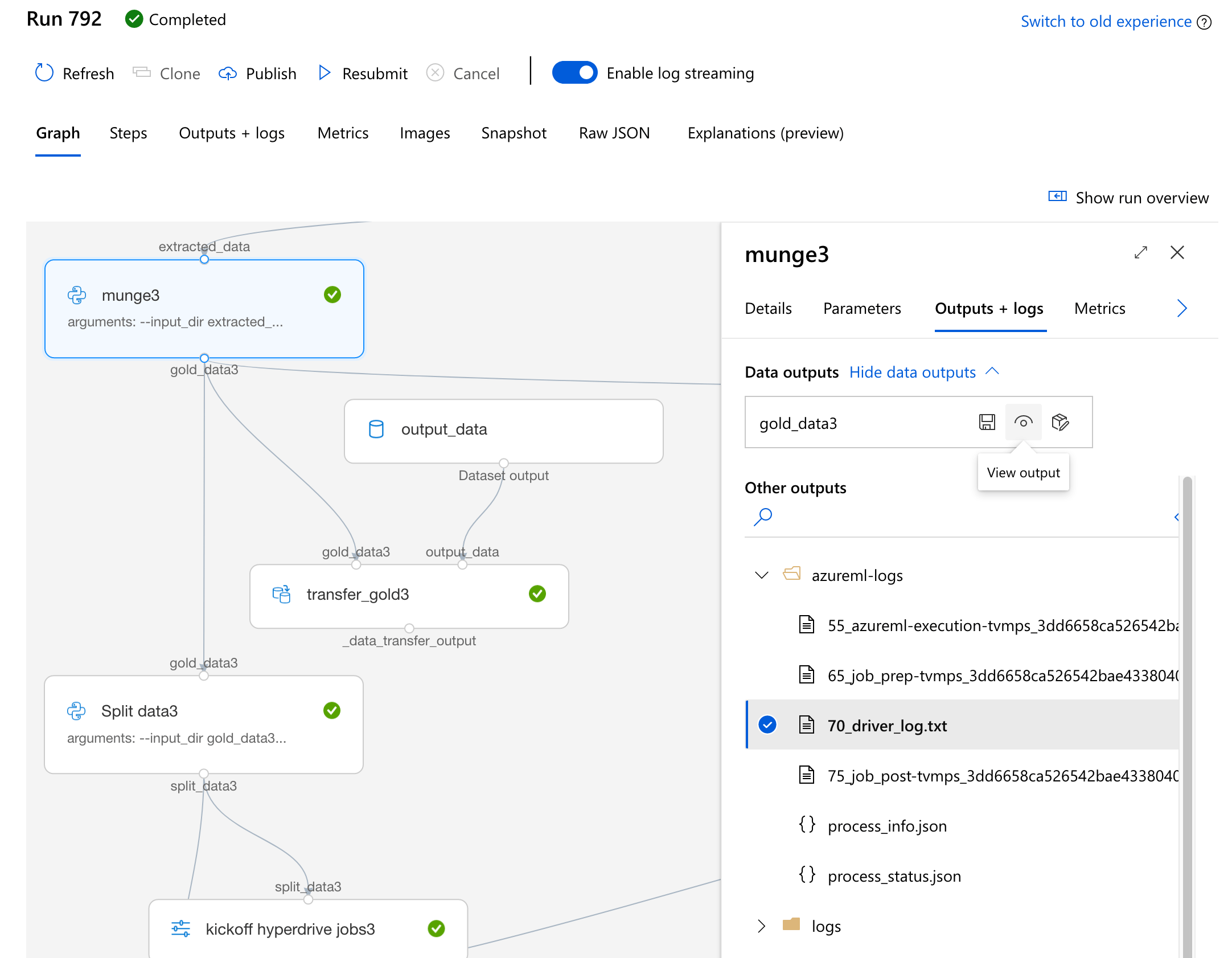
- Перейдите на страницу PipelineRun, щелкните значок
- В
test_upload_stackru.pyвы лечитеPipelineDataкак справочник при звонке.to_csv()в отличие от файла, который вы просто вызываетеdf_data_all.to_csv(args.output_extract, index=False). Возможно, попробуйте определитьPipelineDataсis_directory=True. Не уверен, что это необходимо.