Панды Слияния 101
- Как выполнить (
LEFT|RIGHT|FULL) (INNER|OUTER) присоединиться к пандам? - Как добавить NaN для пропущенных строк после слияния?
- Как избавиться от NaNs после слияния?
- Можно ли слить по индексу?
- Как объединить несколько фреймов данных?
merge?join?concat?update? Кто? Какие? Зачем?!
... и больше. Я видел эти повторяющиеся вопросы о различных аспектах функциональности слияния панд. Большая часть информации о слиянии и ее различных вариантах использования сегодня фрагментирована по десяткам плохо сформулированных, неисследуемых сообщений. Цель здесь - собрать некоторые из наиболее важных моментов для потомков.
Предполагается, что эта QnA станет следующей статьей в серии полезных руководств по распространенным идиомам панд (см. Этот пост о поворотах и этот пост о конкатенации, о котором я расскажу позже).
Пожалуйста, обратите внимание, что этот пост не предназначен для замены документации, поэтому, пожалуйста, прочитайте это! Некоторые из примеров взяты оттуда.
8 ответов
Цель этого поста - дать читателям представление о слиянии SQL-кода с пандами, о том, как его использовать и когда его не использовать.
В частности, вот что пройдет этот пост:
Основы - типы соединений (ВЛЕВО, ВПРАВО, ВНЕШНИЙ, ВНУТРЕННИЙ)
- объединение с разными именами столбцов
- избегая дублирования столбца ключа слияния в выводе
- Слияние с индексом в разных условиях
- эффективно используя ваш именованный индекс
- объединить ключ как индекс одного и столбца другого
- Многостороннее слияние по столбцам и индексам (уникальное и неуникальное)
- Известные альтернативы
mergeа такжеjoin
Чему этот пост не пройдёт:
- Обсуждения и время, связанные с производительностью (на данный момент). Наиболее заметные упоминания о лучших альтернативах, где это уместно.
- Обработка суффиксов, удаление лишних столбцов, переименование выходных данных и другие конкретные случаи использования. Есть другие (читай: лучше) посты, которые касаются этого, так что разберись!
Заметка
В большинстве примеров по умолчанию используются операции INNER JOIN при демонстрации различных функций, если не указано иное.Кроме того, все DataFrames здесь могут быть скопированы и реплицированы, так что вы можете играть с ними. Также смотрите этот пост о том, как читать DataFrames из вашего буфера обмена.
Наконец, все визуальное представление операций JOIN заимствовано из статьи https://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins.
Достаточно Talk, просто покажи мне, как использовать merge!
Настроить
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.494079
1 B -0.205158
2 C 0.313068
3 D -0.854096
right
key value
0 B -2.552990
1 D 0.653619
2 E 0.864436
3 F -0.742165
Для простоты ключевой столбец имеет то же имя (пока).
ВНУТРЕННЕЕ СОЕДИНЕНИЕ представлено
Заметка
Aздесь относится к ключам из столбца соединения вleftDataFrame,Bотносится к ключам из столбца соединения вrightDataFrame, а пересечение представляет ключи, общие для обоихleftа такжеright, Затененная область представляет ключи, присутствующие в результате JOIN. Эта конвенция будет соблюдаться повсюду. Имейте в виду, что диаграммы Венна не являются на 100% точным представлением операций JOIN, поэтому принимайте их с небольшим количеством соли.
Чтобы выполнить ВНУТРЕННЕЕ СОЕДИНЕНИЕ, позвоните pd.merge указав левый DataFrame, правый DataFrame и ключ соединения.
pd.merge(left, right, on='key')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
Это возвращает только строки из left а также right которые разделяют общий ключ (в этом примере "B" и "D").
В более поздних версиях панд (v0.21 или около того), merge теперь функция первого порядка, так что вы можете вызвать DataFrame.merge,
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
LEFT OUTER JOIN или LEFT JOIN представлены
Это можно выполнить, указав how='left',
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
Внимательно обратите внимание на размещение NaNs здесь. Если вы укажете how='left' тогда только ключи от left используются и отсутствуют данные из right заменяется на NaN.
И точно так же для ПРАВИЛЬНОГО ВНЕШНЕГО СОЕДИНЕНИЯ или ПРАВИЛЬНОГО СОЕДИНЕНИЯ
...уточнить how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
Здесь ключи от right используются и отсутствуют данные из left заменяется на NaN.
Наконец, для полного внешнего соединения, заданного
уточнить how='outer',
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
При этом используются ключи из обоих кадров, а NaN вставляются для пропущенных строк в обоих.
Документация суммирует эти различные слияния:
Другие СОЕДИНЕНИЯ - ЛЕВЫЙ, ПРАВИЛЬНЫЙ, И ПОЛНЫЙ, исключающий / АНТИ-СОЕДИНЕНИЯ
Если вам нужны ЛЕВЫЕ исключающие СОЕДИНЕНИЯ и ПРАВИЛЬНЫЕ СОЕДИНЕНИЯ в два этапа.
Для LEFT-исключая JOIN, представленный как
Начните с выполнения LEFT OUTER JOIN, а затем отфильтруйте (исключая!) Строки из left только,
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
Куда,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothИ аналогично, для ПРАВА, исключающего СОЕДИНЕНИЕ,
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357Наконец, если вам необходимо выполнить слияние, при котором ключи сохраняются только слева или справа, но не одновременно (IOW, выполняя ANTI-JOIN),
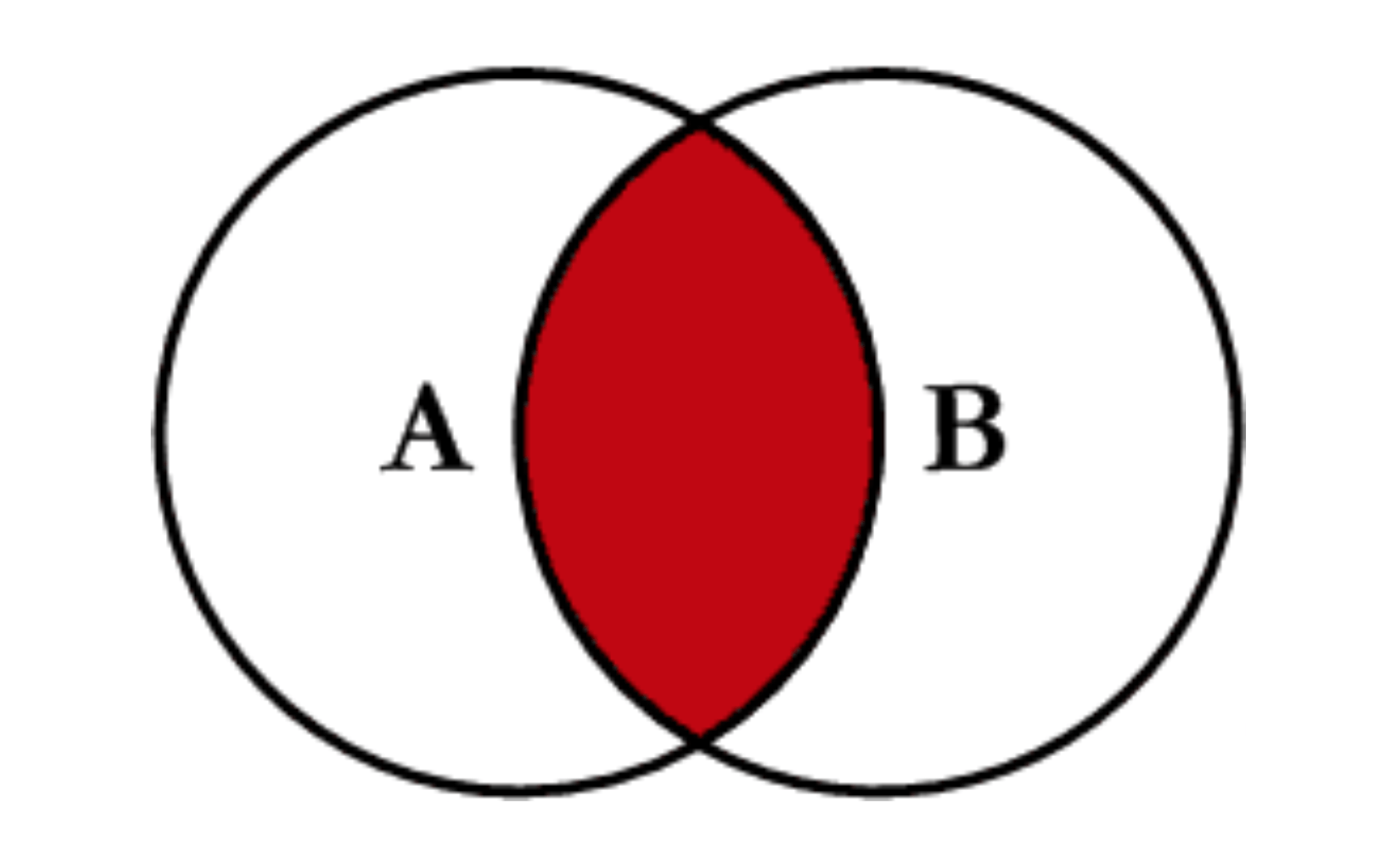
Вы можете сделать это подобным образом -
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
Разные имена для ключевых столбцов
Если ключевые столбцы названы по-разному, например, left имеет keyLeft, а также right имеет keyRight вместо key - тогда вам придется уточнить left_on а также right_on в качестве аргументов вместо on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 0.706573
1 B 0.010500
2 C 1.785870
3 D 0.126912
right2
keyRight value
0 B 0.401989
1 D 1.883151
2 E -1.347759
3 F -1.270485
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.010500 B 0.401989
1 D 0.126912 D 1.883151
Как избежать дублирования ключевого столбца в выводе
При слиянии keyLeft от left а также keyRight от right, если вы хотите только один из keyLeft или же keyRight (но не оба) в выводе, вы можете начать с установки индекса в качестве предварительного шага.
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.010500 B 0.401989
1 0.126912 D 1.883151
Сравните это с выводом команды непосредственно перед (это вывод left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), вы заметите keyLeft пропал, отсутствует. Вы можете выяснить, какой столбец хранить, основываясь на том, какой индекс фрейма установлен в качестве ключа. Это может иметь значение, например, при выполнении какой-либо операции OUTER JOIN.
Слияние только одного столбца из одного из DataFrames
Например, рассмотрим
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
Если вам необходимо объединить только "new_val" (без каких-либо других столбцов), вы обычно можете просто подмножество столбцов перед объединением:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
Если вы делаете LEFT OUTER JOIN, более эффективное решение будет включать map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Как уже упоминалось, это похоже на, но быстрее, чем
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Слияние на нескольких столбцах
Чтобы присоединиться к более чем одному столбцу, укажите список для on (или же left_on а также right_on при необходимости).
left.merge(right, on=['key1', 'key2'] ...)
Или, если имена разные,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
Другое полезное merge* операции и функции
- Слияние DataFrame с Series в индексе: см. Этот ответ.
Кроме того
merge,DataFrame.updateа такжеDataFrame.combine_firstтакже используются в некоторых случаях для обновления одного DataFrame другим.pd.merge_orderedполезная функция для упорядоченных соединений.pd.merge_asof(читай: merge_asOf) полезно для приблизительных соединений.
Этот раздел охватывает только самые основы и предназначен только для разжигания аппетита. Дополнительные примеры и примеры см. В документации по merge , join , а также concat а также ссылки на спецификации функций.
На основе индекса *-JOIN (+ индекс-столбец merge s)
Настроить
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A 2.269755
B -1.454366
C 0.045759
D -0.187184
right
value
idxkey
B 1.532779
D 1.469359
E 0.154947
F 0.378163
Как правило, слияние по индексу будет выглядеть так:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B 0.410599 0.761038
D 1.454274 0.121675
Поддержка имен индексов
Если ваш индекс назван, то пользователи v0.23 также могут указать имя уровня для on (или же left_on а также right_on как необходимо).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B 0.410599 0.761038
D 1.454274 0.121675
Слияние по индексу одного, столбцу (столбцам) другого
Можно (и довольно просто) использовать индекс одного и столбец другого для выполнения слияния. Например,
left.merge(right, left_on='key1', right_index=True)
Или наоборот (right_on=... а также left_index=True).
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 1.222445
1 D 0.208275
2 E 0.976639
3 F 0.356366
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -1.070753 B 1.222445
1 -0.403177 D 0.208275
В этом особом случае индекс для left имя, так что вы также можете использовать имя индекса с left_on, как это:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -1.070753 B 1.222445
1 -0.403177 D 0.208275
DataFrame.join
Помимо этого, есть еще один лаконичный вариант. Ты можешь использовать DataFrame.join который по умолчанию присоединяется к индексу. DataFrame.join делает LEFT OUTER JOIN по умолчанию, так how='inner' здесь необходимо
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B 0.410599 0.761038
D 1.454274 0.121675
Обратите внимание, что мне нужно было указать lsuffix а также rsuffix аргументы с join в противном случае выдается ошибка:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
Так как имена столбцов совпадают. Это не было бы проблемой, если бы они назывались по-другому.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -1.454366 1.532779
D -0.187184 1.469359
pd.concat
Наконец, в качестве альтернативы индексным соединениям вы можете использовать pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -1.980796 1.230291
D 0.156349 1.202380
не указывать join='inner' если вам нужно FULL OUTER JOIN (по умолчанию):
pd.concat([left, right], axis=1, sort=False)
value value
A -0.887786 NaN
B -1.980796 1.230291
C -0.347912 NaN
D 0.156349 1.202380
E NaN -0.387327
F NaN -0.302303
Для получения дополнительной информации см. Этот канонический пост на pd.concat @piRSquared.
Обобщая: merge использование нескольких фреймов данных
Настроить
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
Часто возникает ситуация, когда несколько DataFrames должны быть объединены вместе. Наивно это можно сделать цепочкой merge звонки:
A.merge(B, on='key').merge(C, on='key')
key valueA valueB valueC
0 D 0.922207 -1.099401 1.0
Тем не менее, это быстро выходит из-под контроля для многих DataFrames. Кроме того, может потребоваться обобщение для неизвестного числа фреймов данных. Для этого часто используется простой трюк с functools.reduce, и вы можете использовать его для достижения внутреннего соединения, например, так:
from functools import reduce
reduce(pd.merge, dfs)
key valueA valueB valueC
0 D 0.465662 1.488252 1.0
Обратите внимание, что каждый столбец, кроме столбца "ключ", должен иметь разные имена, чтобы он работал "из коробки". В противном случае вам может понадобиться lambda,
Для полного внешнего соединения, вы можете карри pd.merge с помощью functools.partial:
from functools import partial
outer_merge = partial(pd.merge, how='outer')
reduce(outer_merge, dfs)
key valueA valueB valueC
0 A 0.056165 NaN NaN
1 B -1.165150 -1.536244 NaN
2 C 0.900826 NaN 1.0
3 D 0.465662 1.488252 1.0
4 E NaN 1.895889 1.0
5 F NaN 1.178780 NaN
6 J NaN NaN 1.0
Как вы могли заметить, это довольно мощный инструмент - вы также можете использовать его для управления именами столбцов во время слияния. Просто добавьте больше аргументов ключевых слов по мере необходимости:
partial(pd.merge, how='outer', left_index=True, right_on=...)
Альтернатива: pd.concat
Если значения вашего столбца уникальны, то имеет смысл использовать pd.concat это быстрее, чем двухстороннее слияние.
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 0.465662 1.488252 1.0
Многостороннее слияние по уникальным индексам
Если вы объединяете несколько фреймов данных в уникальные индексы, вам следует еще раз pd.concat для лучшей производительности.
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 0.922207 -1.099401 1.0
Как всегда, опустить join='inner' для полного внешнего соединения.
Многостороннее слияние по индексам с дубликатами
concat быстрый, но имеет свои недостатки. Он не может обрабатывать дубликаты.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
В этой ситуации, join это лучший вариант, так как он может обрабатывать неуникальные индексы (join звонки merge под капотом).
# For inner join. For left join, pass `pd.DataFrame.join` directly to `reduce`.
inner_join = partial(pd.DataFrame.join, how='inner')
reduce(inner_join, [A3.set_index('key'), B2, C2])
valueA valueB valueC
key
D -0.674333 -1.099401 1.0
D 0.031831 -1.099401 1.0
Дополнительный визуальный взгляд на pd.concat([df0, df1], kwargs), Я сделал это из-за axis=0 а также axis=1 в этом не так интуитивно, как df.mean() или же df.apply(foo)
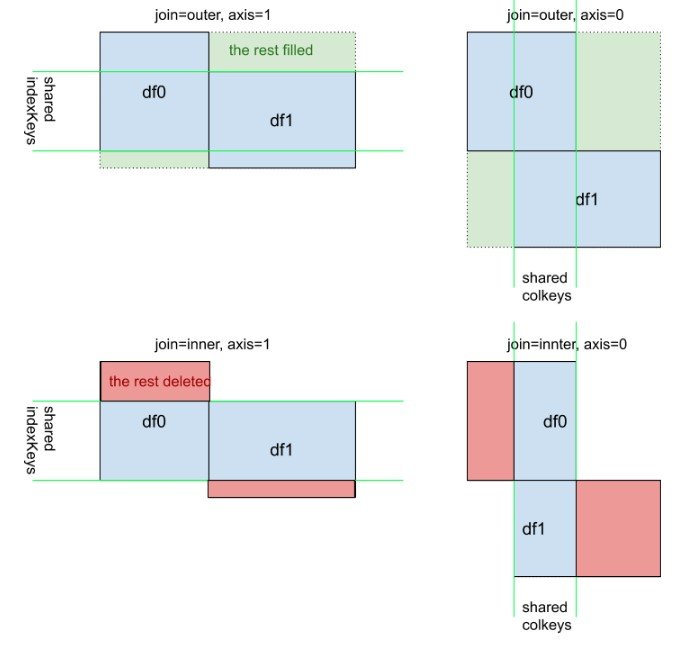
Присоединяется к 101
Эти анимации, возможно, лучше объяснят вам визуально. Кредиты: [Репо Garrick Aden-Buie tidyexplain (https://github.com/gadenbuie/tidyexplain)
Внутреннее соединение

Внешнее соединение или полное соединение

Правое соединение

Левое соединение
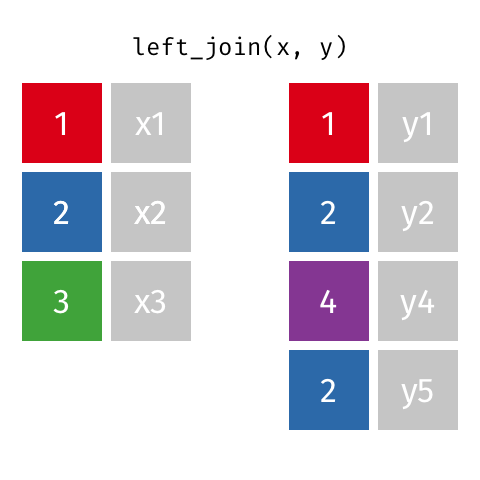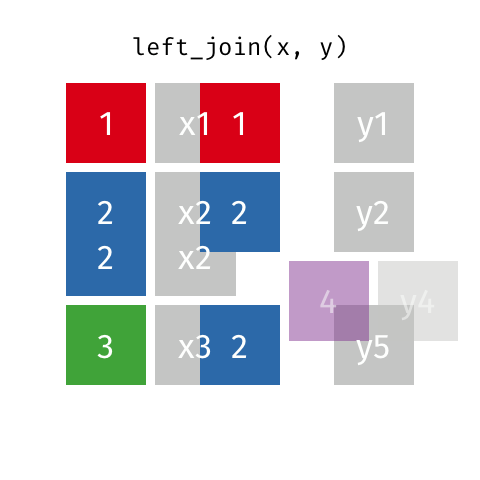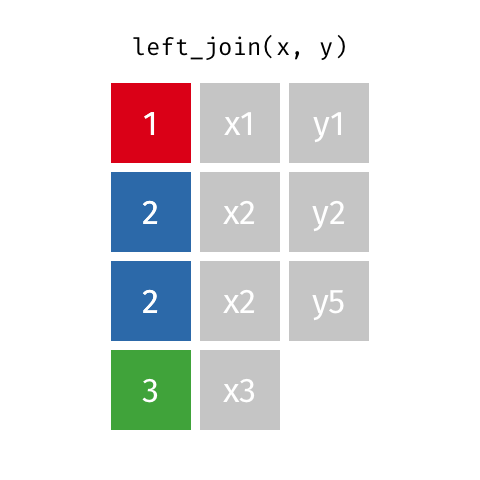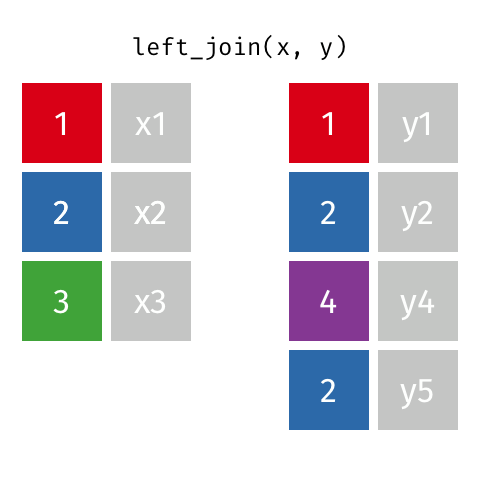
В этом ответе я рассмотрю практический пример pandas.concat.
Учитывая следующее DataFrames с такими же названиями столбцов:
Preco2018 с размером (8784, 5)
Preco 2019 с размером (8760, 5)
У них такие же имена столбцов.
Вы можете комбинировать их, используя pandas.concat, просто
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
В результате получается DataFrame следующего размера (17544, 5)
Если вы хотите визуализировать, он работает так
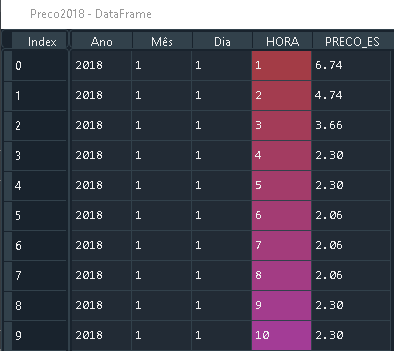
( Источник)
В этом посте будут рассмотрены следующие темы:
- Слияние с индексом при разных условиях
- параметры для объединений на основе индекса:,,
- слияние по индексам
- слияние по индексу одного, столбцу другого
- эффективное использование именованных индексов для упрощения синтаксиса слияния
<strong>ВЕРНУТЬСЯ В начало</strong>
Соединения на основе индекса
TL;DR
Есть несколько вариантов, некоторые из которых проще, чем другие, в зависимости от варианта использования.
- <strong></strong> с участием
left_indexиright_index(или и используя индексы имен)
- поддерживает внутренний / левый / правый / полный
- можно присоединиться только к двум за раз
- поддерживает соединения столбец-столбец, индекс-столбец, индекс-индекс
- <strong></strong> (присоединиться по индексу)
- поддерживает внутренний / левый (по умолчанию) / правый / полный
- может присоединяться к нескольким DataFrames одновременно
- поддерживает соединения индекса-индекса
- <strong></strong> (присоединяется по индексу)
- поддерживает внутренний / полный (по умолчанию)
- может присоединяться к нескольким DataFrames одновременно
- поддерживает соединения индекса-индекса
Индекс для индексирования соединений
Настройка и основы
import pandas as pd
import numpy as np
np.random.seed([3, 14])
left = pd.DataFrame(data={'value': np.random.randn(4)},
index=['A', 'B', 'C', 'D'])
right = pd.DataFrame(data={'value': np.random.randn(4)},
index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
Обычно внутреннее соединение по индексу выглядит так:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Другие объединения следуют аналогичному синтаксису.
Известные альтернативы
по умолчанию - соединения по индексу.
DataFrame.joinпо умолчанию делает LEFT OUTER JOIN, поэтому здесь это необходимо.left.join(right, how='inner', lsuffix='_x', rsuffix='_y') value_x value_y idxkey B -0.402655 0.543843 D -0.524349 0.013135Обратите внимание, что мне нужно было указать
lsuffixиrsuffixаргументы, поскольку в противном случае произошла бы ошибка:left.join(right) ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')Поскольку названия столбцов совпадают. Это не было бы проблемой, если бы они были названы по-другому.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner') leftvalue value idxkey B -0.402655 0.543843 D -0.524349 0.013135<tcode id="15082"></tcode>присоединяется к индексу и может присоединяться к двум или более DataFrames одновременно. По умолчанию он выполняет полное внешнее соединение, поэтому
how='inner'здесь требуется ..pd.concat([left, right], axis=1, sort=False, join='inner') value value idxkey B -0.402655 0.543843 D -0.524349 0.013135Для получения дополнительной информации см. Этот пост .
Индекс к объединению столбца
Чтобы выполнить внутреннее соединение с использованием индекса слева, столбец справа, вы будете использовать комбинацию
left_index=True и
right_on=....
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
Другие объединения следуют аналогичной структуре. Обратите внимание, что только
mergeможет выполнять индексирование для объединения столбцов. Вы можете объединить несколько столбцов, при условии, что количество уровней индекса слева равно количеству столбцов справа.
join и
concatне допускают смешанных слияний. Вам нужно будет установить индекс в качестве предварительного шага, используя
<tcode id="15125"></tcode>.
Фактическое использование именованного индекса [pandas> = 0,23]
Если ваш индекс назван, то из pandas> = 0,23,
DataFrame.merge позволяет указать имя индекса для
on (или и
right_on как надо).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Для предыдущего примера слияния с индексом левого столбца справа вы можете использовать
left_on с индексным именем слева:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
Продолжить чтение
Перейдите к другим темам в Pandas Merging 101, чтобы продолжить обучение:
* Вы здесь
В этом посте будут рассмотрены следующие темы:
- как правильно обобщить на несколько DataFrames (и почему здесь есть недостатки)
- слияние уникальных ключей
- слияние на неуникальных ключах
<strong>ВЕРНУТЬСЯ В начало</strong>
Обобщение на несколько фреймов данных
Часто возникает ситуация, когда необходимо объединить несколько DataFrames. Наивно, это можно сделать, объединив вызовы:
df1.merge(df2, ...).merge(df3, ...)
Однако для многих DataFrame это быстро выходит из-под контроля. Кроме того, может потребоваться обобщение для неизвестного количества DataFrames.
Здесь я представляю многостороннее соединение по уникальным ключам, и
DataFrame.joinдля многосторонних соединений по неуникальным ключам. Во-первых, настройка.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Многостороннее слияние уникальных ключей
Если ваши ключи (здесь ключ может быть либо столбцом, либо индексом) уникальны, вы можете использовать. Обратите внимание, что
pd.concatприсоединяется к DataFrames в индексе .
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
Опустить
join='inner'для ПОЛНОГО ВНЕШНЕГО СОЕДИНЕНИЯ. Обратите внимание, что вы не можете указать соединения LEFT или RIGHT OUTER (если они вам нужны, используйте, как описано ниже).
Многостороннее слияние ключей с дубликатами
concatработает быстро, но имеет свои недостатки. Он не может обрабатывать дубликаты.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
В этой ситуации мы можем использовать, поскольку он может обрабатывать неуникальные ключи (обратите внимание, что
joinприсоединяется к DataFrames по их индексу; это зовёт
merge под капотом и выполняет LEFT OUTER JOIN, если не указано иное).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Продолжить чтение
Перейдите к другим темам в Pandas Merging 101, чтобы продолжить обучение:
* Вы здесь
Pandas на данный момент не поддерживает неравенство в синтаксисе слияния; один вариант — с функцией conditional_join от pyjanitor — я являюсь участником этой библиотеки:
# pip install pyjanitor
import pandas as pd
import janitor
left.conditional_join(right, ('value', 'value', '>'))
left right
key value key value
0 A 1.764052 D -0.977278
1 A 1.764052 F -0.151357
2 A 1.764052 E 0.950088
3 B 0.400157 D -0.977278
4 B 0.400157 F -0.151357
5 C 0.978738 D -0.977278
6 C 0.978738 F -0.151357
7 C 0.978738 E 0.950088
8 D 2.240893 D -0.977278
9 D 2.240893 F -0.151357
10 D 2.240893 E 0.950088
11 D 2.240893 B 1.867558
left.conditional_join(right, ('value', 'value', '<'))
left right
key value key value
0 A 1.764052 B 1.867558
1 B 0.400157 E 0.950088
2 B 0.400157 B 1.867558
3 C 0.978738 B 1.867558
Столбцы передаются как переменный аргумент кортежей, каждый кортеж состоит из столбца из левого фрейма данных, столбца из правого фрейма данных и оператора соединения, который может быть любым из(>, <, >=, <=, !=). В приведенном выше примере возвращается столбец MultiIndex из-за перекрытия имен столбцов.
С точки зрения производительности это лучше, чем наивное перекрестное соединение:
np.random.seed(0)
dd = pd.DataFrame({'value':np.random.randint(100000, size=50_000)})
df = pd.DataFrame({'start':np.random.randint(100000, size=1_000),
'end':np.random.randint(100000, size=1_000)})
dd.head()
value
0 68268
1 43567
2 42613
3 45891
4 21243
df.head()
start end
0 71915 47005
1 64284 44913
2 13377 96626
3 75823 38673
4 29151 575
%%timeit
out = df.merge(dd, how='cross')
out.loc[(out.start < out.value) & (out.end > out.value)]
5.12 s ± 19 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df.conditional_join(dd, ('start', 'value' ,'<'), ('end', 'value' ,'>'))
280 ms ± 5.56 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df.conditional_join(dd, ('start', 'value' ,'<'), ('end', 'value' ,'>'), use_numba=True)
124 ms ± 12.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
out = df.merge(dd, how='cross')
out = out.loc[(out.start < out.value) & (out.end > out.value)]
A = df.conditional_join(dd, ('start', 'value' ,'<'), ('end', 'value' ,'>'))
columns = A.columns.tolist()
A = A.sort_values(columns, ignore_index = True)
out = out.sort_values(columns, ignore_index = True)
A.equals(out)
True
В зависимости от размера данных вы можете получить большую производительность, если присутствует эквивалентное соединение. В этом случае используется функция слияния pandas, но окончательный кадр данных задерживается до тех пор, пока не будут вычислены неэквивалентные соединения. Здесь нетnumbaподдержку при наличии равных условий. Посмотрим на данные отсюда :
import pandas as pd
import numpy as np
import random
import datetime
def random_dt_bw(start_date,end_date):
days_between = (end_date - start_date).days
random_num_days = random.randrange(days_between)
random_dt = start_date + datetime.timedelta(days=random_num_days)
return random_dt
def generate_data(n=1000):
items = [f"i_{x}" for x in range(n)]
start_dates = [random_dt_bw(datetime.date(2020,1,1),datetime.date(2020,9,1)) for x in range(n)]
end_dates = [x + datetime.timedelta(days=random.randint(1,10)) for x in start_dates]
offerDf = pd.DataFrame({"Item":items,
"StartDt":start_dates,
"EndDt":end_dates})
transaction_items = [f"i_{random.randint(0,n)}" for x in range(5*n)]
transaction_dt = [random_dt_bw(datetime.date(2020,1,1),datetime.date(2020,9,1)) for x in range(5*n)]
sales_amt = [random.randint(0,1000) for x in range(5*n)]
transactionDf = pd.DataFrame({"Item":transaction_items,"TransactionDt":transaction_dt,"Sales":sales_amt})
return offerDf,transactionDf
offerDf,transactionDf = generate_data(n=100000)
offerDf = (offerDf
.assign(StartDt = offerDf.StartDt.astype(np.datetime64),
EndDt = offerDf.EndDt.astype(np.datetime64)
)
)
transactionDf = transactionDf.assign(TransactionDt = transactionDf.TransactionDt.astype(np.datetime64))
# you can get more performance when using ints/datetimes
# in the equi join, compared to strings
offerDf = offerDf.assign(Itemr = offerDf.Item.str[2:].astype(int))
transactionDf = transactionDf.assign(Itemr = transactionDf.Item.str[2:].astype(int))
transactionDf.head()
Item TransactionDt Sales Itemr
0 i_43407 2020-05-29 692 43407
1 i_95044 2020-07-22 964 95044
2 i_94560 2020-01-09 462 94560
3 i_11246 2020-02-26 690 11246
4 i_55974 2020-03-07 219 55974
offerDf.head()
Item StartDt EndDt Itemr
0 i_0 2020-04-18 2020-04-19 0
1 i_1 2020-02-28 2020-03-07 1
2 i_2 2020-03-28 2020-03-30 2
3 i_3 2020-08-03 2020-08-13 3
4 i_4 2020-05-26 2020-06-04 4
# merge on strings
merged_df = pd.merge(offerDf,transactionDf,on='Itemr')
classic_int = merged_df[(merged_df['TransactionDt']>=merged_df['StartDt']) &
(merged_df['TransactionDt']<=merged_df['EndDt'])]
# merge on ints ... usually faster
merged_df = pd.merge(offerDf,transactionDf,on='Item')
classic_str = merged_df[(merged_df['TransactionDt']>=merged_df['StartDt']) &
(merged_df['TransactionDt']<=merged_df['EndDt'])]
# merge on integers
cond_join_int = (transactionDf
.conditional_join(
offerDf,
('Itemr', 'Itemr', '=='),
('TransactionDt', 'StartDt', '>='),
('TransactionDt', 'EndDt', '<=')
)
)
# merge on strings
cond_join_str = (transactionDf
.conditional_join(
offerDf,
('Item', 'Item', '=='),
('TransactionDt', 'StartDt', '>='),
('TransactionDt', 'EndDt', '<=')
)
)
%%timeit
merged_df = pd.merge(offerDf,transactionDf,on='Item')
classic_str = merged_df[(merged_df['TransactionDt']>=merged_df['StartDt']) &
(merged_df['TransactionDt']<=merged_df['EndDt'])]
292 ms ± 3.84 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
merged_df = pd.merge(offerDf,transactionDf,on='Itemr')
classic_int = merged_df[(merged_df['TransactionDt']>=merged_df['StartDt']) &
(merged_df['TransactionDt']<=merged_df['EndDt'])]
253 ms ± 2.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
(transactionDf
.conditional_join(
offerDf,
('Item', 'Item', '=='),
('TransactionDt', 'StartDt', '>='),
('TransactionDt', 'EndDt', '<=')
)
)
256 ms ± 9.66 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
(transactionDf
.conditional_join(
offerDf,
('Itemr', 'Itemr', '=='),
('TransactionDt', 'StartDt', '>='),
('TransactionDt', 'EndDt', '<=')
)
)
71.8 ms ± 2.24 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
# check that both dataframes are equal
cols = ['Item', 'TransactionDt', 'Sales', 'Itemr_y','StartDt', 'EndDt', 'Itemr_x']
cond_join_str = cond_join_str.drop(columns=('right', 'Item')).set_axis(cols, axis=1)
(cond_join_str
.sort_values(cond_join_str.columns.tolist())
.reset_index(drop=True)
.reindex(columns=classic_str.columns)
.equals(
classic_str
.sort_values(classic_str.columns.tolist())
.reset_index(drop=True)
))
True
Я думаю, вы должны включить это в свое объяснение, так как это релевантное слияние, которое я вижу довольно часто, которое называется
Установка:
names1 = [{'A':'Jack', 'B':'Jill'}]
names2 = [{'C':'Tommy', 'D':'Tammy'}]
df1=pd.DataFrame(names1)
df2=pd.DataFrame(names2)
df_merged= pd.merge(df1.assign(X=1), df2.assign(X=1), on='X').drop('X', 1)
Это создает фиктивный столбец X, объединяется с X, а затем отбрасывает его для создания
df_merged:
A B C D
0 Jack Jill Tommy Tammy