Как развернуть датафрейм
- Что такое пивот?
- Как мне повернуть?
- Это стержень?
- Длинный формат широкоформатный?
Я видел много вопросов о сводных таблицах. Даже если они не знают, что спрашивают о сводных таблицах, они обычно так и делают. Практически невозможно написать канонический вопрос и ответ, который охватывает все аспекты поворота....
... Но я собираюсь попробовать.
Проблема с существующими вопросами и ответами состоит в том, что часто вопрос фокусируется на нюансе, который ОП затрудняет обобщение, чтобы использовать ряд существующих хороших ответов. Тем не менее, ни один из ответов не пытается дать исчерпывающее объяснение (потому что это сложная задача)
Посмотрите несколько примеров из моего поиска Google
- Как развернуть датафрейм в Pandas?
- Хороший вопрос и ответ. Но ответ только отвечает на конкретный вопрос с небольшим объяснением.
- сводная таблица панд к фрейму данных
- В этом вопросе OP касается вывода разворота. А именно, как выглядят колонны. ОП хотел, чтобы это выглядело как R. Это не очень полезно для пользователей панд.
- Панды, поворачивающие фрейм данных, повторяющиеся строки
- Еще один достойный вопрос, но ответ сосредоточен на одном методе, а именно
pd.DataFrame.pivot
- Еще один достойный вопрос, но ответ сосредоточен на одном методе, а именно
Поэтому, когда кто-то ищет pivot они получают спорадические результаты, которые, вероятно, не будут отвечать на их конкретный вопрос.
Настроить
Вы можете заметить, что я явно назвал свои столбцы и соответствующие значения столбцов в соответствии с тем, как я собираюсь поворачиваться в ответах ниже. Обратите внимание, чтобы вы узнали, куда идут имена столбцов, где можно получить результаты, которые вы ищете.
import numpy as np
import pandas as pd
from numpy.core.defchararray import add
np.random.seed([3,1415])
n = 20
cols = np.array(['key', 'row', 'item', 'col'])
arr1 = (np.random.randint(5, size=(n, 4)) // [2, 1, 2, 1]).astype(str)
df = pd.DataFrame(
add(cols, arr1), columns=cols
).join(
pd.DataFrame(np.random.rand(n, 2).round(2)).add_prefix('val')
)
print(df)
key row item col val0 val1
0 key0 row3 item1 col3 0.81 0.04
1 key1 row2 item1 col2 0.44 0.07
2 key1 row0 item1 col0 0.77 0.01
3 key0 row4 item0 col2 0.15 0.59
4 key1 row0 item2 col1 0.81 0.64
5 key1 row2 item2 col4 0.13 0.88
6 key2 row4 item1 col3 0.88 0.39
7 key1 row4 item1 col1 0.10 0.07
8 key1 row0 item2 col4 0.65 0.02
9 key1 row2 item0 col2 0.35 0.61
10 key2 row0 item2 col1 0.40 0.85
11 key2 row4 item1 col2 0.64 0.25
12 key0 row2 item2 col3 0.50 0.44
13 key0 row4 item1 col4 0.24 0.46
14 key1 row3 item2 col3 0.28 0.11
15 key0 row3 item1 col1 0.31 0.23
16 key0 row0 item2 col3 0.86 0.01
17 key0 row4 item0 col3 0.64 0.21
18 key2 row2 item2 col0 0.13 0.45
19 key0 row2 item0 col4 0.37 0.70
Вопросы)
Почему я получаю
ValueError: Index contains duplicate entries, cannot reshapeКак мне повернуть
dfтакой, чтоcolзначения являются столбцами,rowзначения являются индексом и средним значениемval0значения?col col0 col1 col2 col3 col4 row row0 0.77 0.605 NaN 0.860 0.65 row2 0.13 NaN 0.395 0.500 0.25 row3 NaN 0.310 NaN 0.545 NaN row4 NaN 0.100 0.395 0.760 0.24Как мне повернуть
dfтакой, чтоcolзначения являются столбцами,rowзначения являются индексом, средним значениемval0значения, а пропущенные значения0?col col0 col1 col2 col3 col4 row row0 0.77 0.605 0.000 0.860 0.65 row2 0.13 0.000 0.395 0.500 0.25 row3 0.00 0.310 0.000 0.545 0.00 row4 0.00 0.100 0.395 0.760 0.24Могу ли я получить что-то кроме
meanвроде как можетsum?col col0 col1 col2 col3 col4 row row0 0.77 1.21 0.00 0.86 0.65 row2 0.13 0.00 0.79 0.50 0.50 row3 0.00 0.31 0.00 1.09 0.00 row4 0.00 0.10 0.79 1.52 0.24Могу ли я сделать больше одной агрегации за раз?
sum mean col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4 row row0 0.77 1.21 0.00 0.86 0.65 0.77 0.605 0.000 0.860 0.65 row2 0.13 0.00 0.79 0.50 0.50 0.13 0.000 0.395 0.500 0.25 row3 0.00 0.31 0.00 1.09 0.00 0.00 0.310 0.000 0.545 0.00 row4 0.00 0.10 0.79 1.52 0.24 0.00 0.100 0.395 0.760 0.24Могу ли я объединить несколько столбцов значений?
val0 val1 col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4 row row0 0.77 0.605 0.000 0.860 0.65 0.01 0.745 0.00 0.010 0.02 row2 0.13 0.000 0.395 0.500 0.25 0.45 0.000 0.34 0.440 0.79 row3 0.00 0.310 0.000 0.545 0.00 0.00 0.230 0.00 0.075 0.00 row4 0.00 0.100 0.395 0.760 0.24 0.00 0.070 0.42 0.300 0.46Можно разделить на несколько столбцов?
item item0 item1 item2 col col2 col3 col4 col0 col1 col2 col3 col4 col0 col1 col3 col4 row row0 0.00 0.00 0.00 0.77 0.00 0.00 0.00 0.00 0.00 0.605 0.86 0.65 row2 0.35 0.00 0.37 0.00 0.00 0.44 0.00 0.00 0.13 0.000 0.50 0.13 row3 0.00 0.00 0.00 0.00 0.31 0.00 0.81 0.00 0.00 0.000 0.28 0.00 row4 0.15 0.64 0.00 0.00 0.10 0.64 0.88 0.24 0.00 0.000 0.00 0.00Или же
item item0 item1 item2 col col2 col3 col4 col0 col1 col2 col3 col4 col0 col1 col3 col4 key row key0 row0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.86 0.00 row2 0.00 0.00 0.37 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.50 0.00 row3 0.00 0.00 0.00 0.00 0.31 0.00 0.81 0.00 0.00 0.00 0.00 0.00 row4 0.15 0.64 0.00 0.00 0.00 0.00 0.00 0.24 0.00 0.00 0.00 0.00 key1 row0 0.00 0.00 0.00 0.77 0.00 0.00 0.00 0.00 0.00 0.81 0.00 0.65 row2 0.35 0.00 0.00 0.00 0.00 0.44 0.00 0.00 0.00 0.00 0.00 0.13 row3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.28 0.00 row4 0.00 0.00 0.00 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 key2 row0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.40 0.00 0.00 row2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.13 0.00 0.00 0.00 row4 0.00 0.00 0.00 0.00 0.00 0.64 0.88 0.00 0.00 0.00 0.00 0.00Могу ли я объединить частоту, с которой столбец и строки встречаются вместе, то есть "кросс-табуляция"?
col col0 col1 col2 col3 col4 row row0 1 2 0 1 1 row2 1 0 2 1 2 row3 0 1 0 2 0 row4 0 1 2 2 1
5 ответов
Начнем с ответа на первый вопрос:
Вопрос 1
Почему я получаю
ValueError: Index contains duplicate entries, cannot reshape
Это происходит потому, что панды пытаются переиндексировать columns или же index объект с повторяющимися записями. Существуют различные методы, которые могут использовать для разворота. Некоторые из них не очень подходят, когда есть дубликаты клавиш, в которых его просят повернуть. Например. Рассматривать pd.DataFrame.pivot, Я знаю, что есть повторяющиеся записи, которые разделяют row а также col ценности:
df.duplicated(['row', 'col']).any()
True
Итак, когда я pivot с помощью
df.pivot(index='row', columns='col', values='val0')
Я получаю ошибку, упомянутую выше. Фактически, я получаю ту же ошибку, когда пытаюсь выполнить ту же задачу с:
df.set_index(['row', 'col'])['val0'].unstack()
Вот список идиом, которые мы можем использовать для поворота
pd.DataFrame.groupby+pd.DataFrame.unstack- Хороший общий подход для выполнения практически любого типа разворота
- Вы указываете все столбцы, которые будут составлять поворотные уровни строк и уровни столбцов в одной группе. Вы следуете этому, выбирая оставшиеся столбцы, которые вы хотите агрегировать, и функции, которые вы хотите выполнить агрегирование. Наконец-то вы
unstackуровни, которые вы хотите быть в индексе столбца.
pd.DataFrame.pivot_table- Прославленная версия
groupbyс более интуитивным API. Для многих это предпочтительный подход. И это намеченный подход со стороны разработчиков. - Укажите уровень строки, уровни столбцов, значения для агрегирования и функции для выполнения агрегации.
- Прославленная версия
pd.DataFrame.set_index+pd.DataFrame.unstack- Удобный и интуитивно понятный для некоторых (включая меня). Не удается обработать дублированные сгруппированные ключи.
- Похож на
groupbyВ парадигме мы указываем все столбцы, которые в конечном итоге будут уровнями строк или столбцов, и устанавливаем их в качестве индекса. Мы тогдаunstackуровни, которые мы хотим в столбцах. Если оставшиеся уровни индекса или уровни столбца не являются уникальными, этот метод завершится ошибкой.
pd.DataFrame.pivot- Очень похоже на
set_indexв том, что он разделяет ограничение дубликата ключа. API также очень ограничен. Требуются только скалярные значения дляindex,columns,values, - Похож на
pivot_tableМетод в том, что мы выбираем строки, столбцы и значения для поворота. Однако мы не можем агрегировать, и если строки или столбцы не являются уникальными, этот метод завершится ошибкой.
- Очень похоже на
pd.crosstab- Это специализированная версия
pivot_tableи в чистом виде это наиболее интуитивно понятный способ выполнения нескольких задач.
- Это специализированная версия
pd.factorize+np.bincount- Это очень продвинутый метод, который очень неясен, но очень быстр. Его нельзя использовать ни при каких обстоятельствах, но когда его можно использовать, и вы можете его использовать, вы получите плоды производительности.
pd.get_dummies+pd.DataFrame.dot- Я использую это для умного выполнения кросс-табуляции.
Примеры
Что я собираюсь сделать для каждого последующего ответа и вопроса, чтобы ответить на него, используя pd.DataFrame.pivot_table, Затем я предоставлю альтернативы для выполнения той же задачи.
Вопрос 3
Как мне повернуть
dfтакой, чтоcolзначения являются столбцами,rowзначения являются индексом, средним значениемval0значения, а пропущенные значения0?
pd.DataFrame.pivot_tablefill_valueне установлено по умолчанию. Я склонен устанавливать это соответствующим образом. В этом случае я установил его0, Обратите внимание, что я пропустил вопрос 2, так как он такой же, как этот ответ безfill_valueaggfunc='mean'по умолчанию, и мне не нужно было его устанавливать. Я включил это, чтобы быть явным.df.pivot_table( values='val0', index='row', columns='col', fill_value=0, aggfunc='mean') col col0 col1 col2 col3 col4 row row0 0.77 0.605 0.000 0.860 0.65 row2 0.13 0.000 0.395 0.500 0.25 row3 0.00 0.310 0.000 0.545 0.00 row4 0.00 0.100 0.395 0.760 0.24
pd.DataFrame.groupbydf.groupby(['row', 'col'])['val0'].mean().unstack(fill_value=0)pd.crosstabpd.crosstab( index=df['row'], columns=df['col'], values=df['val0'], aggfunc='mean').fillna(0)
Вопрос 4
Могу ли я получить что-то кроме
meanвроде как можетsum?
pd.DataFrame.pivot_tabledf.pivot_table( values='val0', index='row', columns='col', fill_value=0, aggfunc='sum') col col0 col1 col2 col3 col4 row row0 0.77 1.21 0.00 0.86 0.65 row2 0.13 0.00 0.79 0.50 0.50 row3 0.00 0.31 0.00 1.09 0.00 row4 0.00 0.10 0.79 1.52 0.24pd.DataFrame.groupbydf.groupby(['row', 'col'])['val0'].sum().unstack(fill_value=0)pd.crosstabpd.crosstab( index=df['row'], columns=df['col'], values=df['val0'], aggfunc='sum').fillna(0)
Вопрос 5
Могу ли я сделать больше одной агрегации за раз?
Обратите внимание, что для pivot_table а также cross_tab Мне нужно было пройти список вызовов. С другой стороны, groupby.agg способен принимать строки для ограниченного числа специальных функций. groupby.agg также взял бы те же самые вызовы, которые мы передали другим, но часто более эффективно использовать имена строковых функций, так как есть эффективность, которую нужно получить.
pd.DataFrame.pivot_tabledf.pivot_table( values='val0', index='row', columns='col', fill_value=0, aggfunc=[np.size, np.mean]) size mean col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4 row row0 1 2 0 1 1 0.77 0.605 0.000 0.860 0.65 row2 1 0 2 1 2 0.13 0.000 0.395 0.500 0.25 row3 0 1 0 2 0 0.00 0.310 0.000 0.545 0.00 row4 0 1 2 2 1 0.00 0.100 0.395 0.760 0.24pd.DataFrame.groupbydf.groupby(['row', 'col'])['val0'].agg(['size', 'mean']).unstack(fill_value=0)pd.crosstabpd.crosstab( index=df['row'], columns=df['col'], values=df['val0'], aggfunc=[np.size, np.mean]).fillna(0, downcast='infer')
Вопрос 6
Могу ли я объединить несколько столбцов значений?
pd.DataFrame.pivot_tableмы проходимvalues=['val0', 'val1']но мы могли бы оставить это полностьюdf.pivot_table( values=['val0', 'val1'], index='row', columns='col', fill_value=0, aggfunc='mean') val0 val1 col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4 row row0 0.77 0.605 0.000 0.860 0.65 0.01 0.745 0.00 0.010 0.02 row2 0.13 0.000 0.395 0.500 0.25 0.45 0.000 0.34 0.440 0.79 row3 0.00 0.310 0.000 0.545 0.00 0.00 0.230 0.00 0.075 0.00 row4 0.00 0.100 0.395 0.760 0.24 0.00 0.070 0.42 0.300 0.46pd.DataFrame.groupbydf.groupby(['row', 'col'])['val0', 'val1'].mean().unstack(fill_value=0)
Вопрос 7
Можно разделить на несколько столбцов?
pd.DataFrame.pivot_tabledf.pivot_table( values='val0', index='row', columns=['item', 'col'], fill_value=0, aggfunc='mean') item item0 item1 item2 col col2 col3 col4 col0 col1 col2 col3 col4 col0 col1 col3 col4 row row0 0.00 0.00 0.00 0.77 0.00 0.00 0.00 0.00 0.00 0.605 0.86 0.65 row2 0.35 0.00 0.37 0.00 0.00 0.44 0.00 0.00 0.13 0.000 0.50 0.13 row3 0.00 0.00 0.00 0.00 0.31 0.00 0.81 0.00 0.00 0.000 0.28 0.00 row4 0.15 0.64 0.00 0.00 0.10 0.64 0.88 0.24 0.00 0.000 0.00 0.00pd.DataFrame.groupbydf.groupby( ['row', 'item', 'col'] )['val0'].mean().unstack(['item', 'col']).fillna(0).sort_index(1)
Вопрос 8
Можно разделить на несколько столбцов?
pd.DataFrame.pivot_tabledf.pivot_table( values='val0', index=['key', 'row'], columns=['item', 'col'], fill_value=0, aggfunc='mean') item item0 item1 item2 col col2 col3 col4 col0 col1 col2 col3 col4 col0 col1 col3 col4 key row key0 row0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.86 0.00 row2 0.00 0.00 0.37 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.50 0.00 row3 0.00 0.00 0.00 0.00 0.31 0.00 0.81 0.00 0.00 0.00 0.00 0.00 row4 0.15 0.64 0.00 0.00 0.00 0.00 0.00 0.24 0.00 0.00 0.00 0.00 key1 row0 0.00 0.00 0.00 0.77 0.00 0.00 0.00 0.00 0.00 0.81 0.00 0.65 row2 0.35 0.00 0.00 0.00 0.00 0.44 0.00 0.00 0.00 0.00 0.00 0.13 row3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.28 0.00 row4 0.00 0.00 0.00 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 key2 row0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.40 0.00 0.00 row2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.13 0.00 0.00 0.00 row4 0.00 0.00 0.00 0.00 0.00 0.64 0.88 0.00 0.00 0.00 0.00 0.00pd.DataFrame.groupbydf.groupby( ['key', 'row', 'item', 'col'] )['val0'].mean().unstack(['item', 'col']).fillna(0).sort_index(1)pd.DataFrame.set_indexпотому что набор ключей уникален как для строк, так и для столбцовdf.set_index( ['key', 'row', 'item', 'col'] )['val0'].unstack(['item', 'col']).fillna(0).sort_index(1)
Вопрос 9
Могу ли я объединить частоту, с которой столбец и строки встречаются вместе, то есть "кросс-табуляция"?
pd.DataFrame.pivot_tabledf.pivot_table(index='row', columns='col', fill_value=0, aggfunc='size') col col0 col1 col2 col3 col4 row row0 1 2 0 1 1 row2 1 0 2 1 2 row3 0 1 0 2 0 row4 0 1 2 2 1pd.DataFrame.groupbydf.groupby(['row', 'col'])['val0'].size().unstack(fill_value=0)pd.cross_tabpd.crosstab(df['row'], df['col'])pd.factorize+np.bincount# get integer factorization `i` and unique values `r` # for column `'row'` i, r = pd.factorize(df['row'].values) # get integer factorization `j` and unique values `c` # for column `'col'` j, c = pd.factorize(df['col'].values) # `n` will be the number of rows # `m` will be the number of columns n, m = r.size, c.size # `i * m + j` is a clever way of counting the # factorization bins assuming a flat array of length # `n * m`. Which is why we subsequently reshape as `(n, m)` b = np.bincount(i * m + j, minlength=n * m).reshape(n, m) # BTW, whenever I read this, I think 'Bean, Rice, and Cheese' pd.DataFrame(b, r, c) col3 col2 col0 col1 col4 row3 2 0 0 1 0 row2 1 2 1 0 2 row0 1 0 1 2 1 row4 2 2 0 1 1pd.get_dummiespd.get_dummies(df['row']).T.dot(pd.get_dummies(df['col'])) col0 col1 col2 col3 col4 row0 1 2 0 1 1 row2 1 0 2 1 2 row3 0 1 0 2 0 row4 0 1 2 2 1
Чтобы расширить ответ @piRSquared на другую версию вопроса 10
Вопрос 10.1
DataFrame:
d = data = {'A': {0: 1, 1: 1, 2: 1, 3: 2, 4: 2, 5: 3, 6: 5},
'B': {0: 'a', 1: 'b', 2: 'c', 3: 'a', 4: 'b', 5: 'a', 6: 'c'}}
df = pd.DataFrame(d)
A B
0 1 a
1 1 b
2 1 c
3 2 a
4 2 b
5 3 a
6 5 c
Выход:
0 1 2
A
1 a b c
2 a b None
3 a None None
5 c None None
С помощью df.groupby а также pd.Series.tolist
t = df.groupby('A')['B'].apply(list)
out = pd.DataFrame(t.tolist(),index=t.index)
out
0 1 2
A
1 a b c
2 a b None
3 a None None
5 c None None
Или гораздо лучшая альтернатива с использованием pd.pivot_table с df.squeeze.
t = df.pivot_table(index='A',values='B',aggfunc=list).squeeze()
out = pd.DataFrame(t.tolist(),index=t.index)
Чтобы лучше понять, как работает pivot, вы можете посмотреть пример из документации Pandas:

df = pd.DataFrame({
'foo': ['one', 'one', 'one', 'two', 'two', 'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']
})
Таблица ввода:
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
Поворот :
pd.pivot(
data=df,
index='foo', # Column to use to make new frame’s index. If None, uses existing index.
columns='bar', # Column to use to make new frame’s columns.
values='baz' # Column(s) to use for populating new frame’s values.
)
Таблица результатов:
bar A B C
foo
one 1 2 3
two 4 5 6
Звонок (вместе сadd_suffix())
Часто,reset_index()требуется после вызова или . Например, чтобы выполнить следующее преобразование (где один столбец стал именем столбца):

вы используете следующий код, где после вы добавляете префикс к вновь созданным именам столбцов и конвертируете индекс (в этом случае"movies") обратно в столбец и удалите имя имени оси:
df.pivot(*df).add_prefix('week_').reset_index().rename_axis(columns=None)
Как упоминалось в других ответах, «поворот» может относиться к двум различным операциям:
- Агрегация без стека (т. е. сделать результаты более широкими).
- Изменение формы (аналогично повороту в Excel,
reshapeв пустом илиpivot_widerв р)
1. Агрегация
или просто несложенные результатыgroupby.aggоперация. Фактически, исходный код показывает, что под капотом верно следующее:
- = + (читайте здесь для получения дополнительной информации.)
- "="
NB Вы можете использовать список имен столбцов какindex,columnsи аргументы.
df.groupby(rows+cols)[vals].agg(aggfuncs).unstack(cols)
# equivalently,
df.pivot_table(vals, rows, cols, aggfuncs)
1.1.crosstabявляется частным случаем ; таким образом +
Следующие эквивалентны:
-
pd.crosstab(df['colA'], df['colB']) -
df.pivot_table(index='colA', columns='colB', aggfunc='size', fill_value=0) -
df.groupby(['colA', 'colB']).size().unstack(fill_value=0)
Обратите внимание, чтоpd.crosstabимеет значительно большие накладные расходы, поэтому он значительно медленнее, чем оба и + . На самом деле, как отмечено здесь , медленнее, чемgroupby+ также.
2. Изменение формы
pivotявляется более ограниченной версиейpivot_tableгде его целью является преобразование длинного кадра данных в длинный.
df.set_index(rows+cols)[vals].unstack(cols)
# equivalently,
df.pivot(rows, cols, vals)
2.1. Увеличивайте строки/столбцы, как в вопросе 10.
Вы также можете применить информацию из вопроса 10 к операции сводки с несколькими столбцами. Есть два случая:
«long-to-long» : изменить форму, увеличив индексы

Код:
df = pd.DataFrame({'A': [1, 1, 1, 2, 2, 2], 'B': [*'xxyyzz'], 'C': [*'CCDCDD'], 'E': [100, 200, 300, 400, 500, 600]}) rows, cols, vals = ['A', 'B'], ['C'], 'E' # using pivot syntax df1 = ( df.assign(ix=df.groupby(rows+cols).cumcount()) .pivot([*rows, 'ix'], cols, vals) .fillna(0, downcast='infer') .droplevel(-1).reset_index().rename_axis(columns=None) ) # equivalently, using set_index + unstack syntax df1 = ( df .set_index([*rows, df.groupby(rows+cols).cumcount(), *cols])[vals] .unstack(fill_value=0) .droplevel(-1).reset_index().rename_axis(columns=None) )«от длинного к ширине» : изменить форму, увеличив столбцы

Код:
df1 = ( df.assign(ix=df.groupby(rows+cols).cumcount()) .pivot(rows, [*cols, 'ix'])[vals] .fillna(0, downcast='infer') ) df1 = df1.set_axis([f"{c[0]}_{c[1]}" for c in df1], axis=1).reset_index() # equivalently, using the set_index + unstack syntax df1 = ( df .set_index([*rows, df.groupby(rows+cols).cumcount(), *cols])[vals] .unstack([-1, *range(-2, -len(cols)-2, -1)], fill_value=0) ) df1 = df1.set_axis([f"{c[0]}_{c[1]}" for c in df1], axis=1).reset_index()минимальный случай с использованием
set_index+unstackсинтаксис: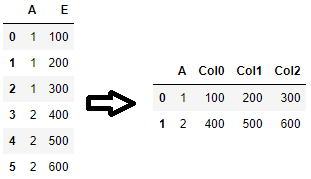
Код:
df1 = df.set_index(['A', df.groupby('A').cumcount()])['E'].unstack(fill_value=0).add_prefix('Col').reset_index()
1 агрегирует значения и распаковывает их. В частности, он создает единый плоский список из индекса и столбцов, вызываетgroupby()с этим списком в качестве группировщика и агрегирует с использованием переданных методов агрегатора (по умолчаниюmean). Затем после агрегации он вызываетunstack()по списку столбцов. Итак, внутри pivot_table = groupby + unstack . Более того, еслиfill_valueпередается,fillna()называется.
Другими словами, метод, который производитpv_1такой же, как метод, который производитgb_1в примере ниже.
pv_1 = df.pivot_table(index=rows, columns=cols, values=vals, aggfunc=aggfuncs, fill_value=0)
# internal operation of `pivot_table()`
gb_1 = df.groupby(rows+cols)[vals].agg(aggfuncs).unstack(cols).fillna(0, downcast="infer")
pv_1.equals(gb_1) # True
2 crosstab()вызовы, т. е. перекрестная таблица = сводная_таблица . В частности, он строит DataFrame из переданных массивов значений, фильтрует его по общим индексам и вызывает . Это более ограничено, чем потому, что он допускает только одномерный массив, подобный as , в отличие отpivot_table()который может иметь несколько столбцов какvalues.
Функция поворота в pandas имеет ту же функциональность, что и операция поворота в Excel. Мы можем преобразовать набор данных из длинного формата в широкий формат.
Давайте рассмотрим пример
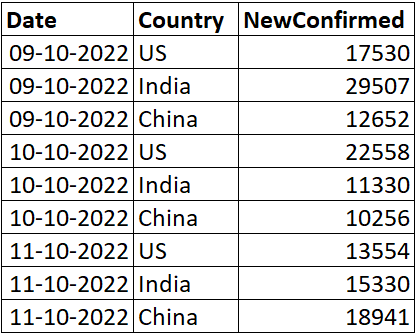
Мы хотим преобразовать набор данных в такую форму, чтобы каждая страна стала столбцом, а новые подтвержденные случаи — значениями, соответствующими странам. Мы можем выполнить эту манипуляцию с данными, используя функцию поворота.
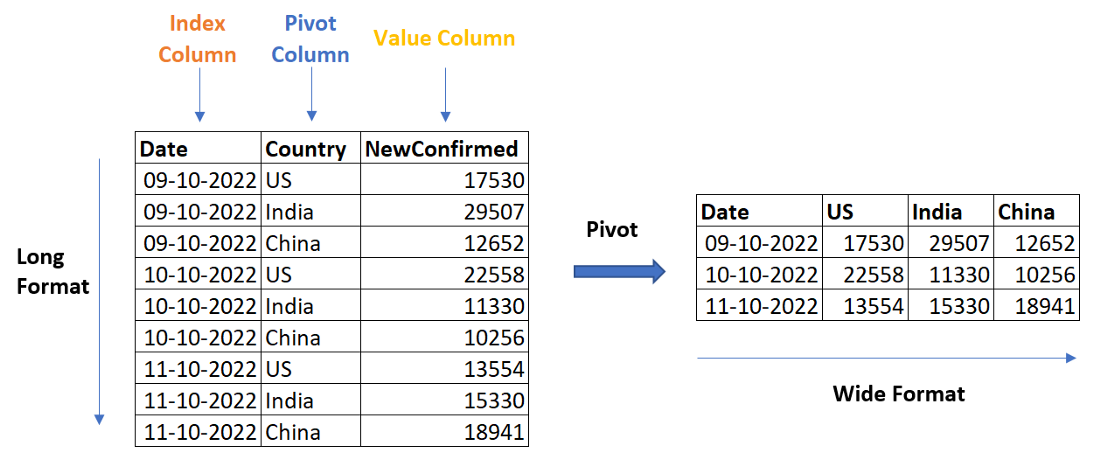
Повернуть набор данных
pivot_df = pd.pivot(df, index =['Date'], columns ='Country', values =['NewConfirmed'])
## renaming the columns
pivot_df.columns = df['Country'].sort_values().unique()
Мы можем вывести новые столбцы на тот же уровень, что и данные столбца индекса, сбросив индекс.
сбросить индекс, чтобы изменить уровни столбцов
pivot_df = pivot_df.reset_index()