Как скопировать / вставить DataFrame из Stackru в Python
В вопросах и ответах пользователи очень часто публикуют пример DataFrame с которыми работает их вопрос / ответ:
In []: x
Out[]:
bar foo
0 4 1
1 5 2
2 6 3
Было бы очень полезно иметь возможность получить это DataFrame в мой интерпретатор Python, чтобы я мог начать отладку вопроса или тестирование ответа.
Как я могу это сделать?
1 ответ
Панды написаны людьми, которые действительно знают, что люди хотят делать.
С версии 0.13 есть функция pd.read_clipboard что абсурдно эффективно для того, чтобы заставить это "просто работать".
Скопируйте и вставьте часть кода в вопрос, который начинается bar foo, (т.е. DataFrame) и сделать это в интерпретаторе Python:
In [53]: import pandas as pd
In [54]: df = pd.read_clipboard()
In [55]: df
Out[55]:
bar foo
0 4 1
1 5 2
2 6 3
Предостережения
- Не включайте iPython
Inили жеOutвещи или не получится - Если у вас есть именованный индекс, вам нужно добавить
engine='python'(см. эту проблему на GitHub). Движок 'c' в настоящее время не работает, когда индекс назван. - Это не блестяще в MultiIndexes:
Попробуй это:
0 1 2
level1 level2
foo a 0.518444 0.239354 0.364764
b 0.377863 0.912586 0.760612
bar a 0.086825 0.118280 0.592211
который не работает вообще, или это:
0 1 2
foo a 0.859630 0.399901 0.052504
b 0.231838 0.863228 0.017451
bar a 0.422231 0.307960 0.801993
Который работает, но возвращает что-то совершенно неверное!
pd.read_clipboard() изящный Однако, если вы пишете код в сценарии или записной книжке (и вы хотите, чтобы ваш код работал в будущем), это не очень подходит. Вот альтернативный способ скопировать / вставить выходные данные в новый объект данных, который гарантирует, что df переживет содержимое вашего буфера обмена:
import pandas as pd
d = '''0 1 2 3 4
A Y N N Y
B N Y N N
C N N N N
D Y Y N Y
E N Y Y Y
F Y Y N Y
G Y N N Y'''
df = pd.read_csv(pd.compat.StringIO(d), sep='\s+')
Несколько заметок:
- Строка в тройных кавычках сохраняет символы новой строки в выходных данных.
StringIOоборачивает вывод в файлоподобный объект, которыйread_csvтребует.- настройка
sepв\s+делает так, чтобы каждый непрерывный блок пробелов рассматривался как один разделитель.
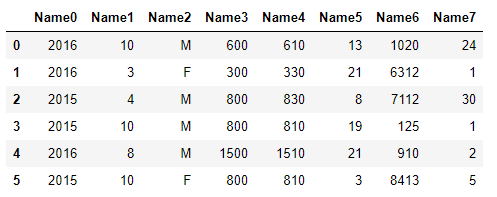
Если вы копируете из CSV-файла, в котором есть такие стандартные записи:
2016,10,M,0600,0610,13,1020,24
2016,3,F,0300,0330,21,6312,1
2015,4,M,0800,0830,8,7112,30
2015,10,M,0800,0810,19,0125,1
2016,8,M,1500,1510,21,0910,2
2015,10,F,0800,0810,3,8413,5
df =pd.read_clipboard(sep=",", header=None)
df.rename(columns={0: "Name0", 1: "Name1",2:"Name2",3:"Name3",4:"Name4",5:"Name5",6:"Name6",7:"Name7",8:"Name8"})
предоставит вам правильно определенный pandas Dataframe.