Обход граничащей объемной иерархии в шейдерах
Я работаю над трассировщиком пути, используя вулканские вычислительные шейдеры. Я реализовал дерево, представляющее иерархию ограничивающего объема. Идея BVH состоит в том, чтобы минимизировать количество объектов, на которых необходимо выполнить тест пересечения лучей.
# 1 Наивная реализация
Моя первая реализация очень быстрая, она проходит по дереву до одного листа дерева BVH. Тем не менее, луч может пересекать несколько листьев. Этот код приводит к тому, что некоторые треугольники не отображаются (хотя они должны).
int box_index = -1;
for (int i = 0; i < boxes_count; i++) {
// the first box has no parent, boxes[0].parent is set to -1
if (boxes[i].parent == box_index) {
if (intersect_box(boxes[i], ray)) {
box_index = i;
}
}
}
if (box_index > -1) {
uint a = boxes[box_index].ids_offset;
uint b = a + boxes[box_index].ids_count;
for (uint j = a; j < b; j++) {
uint triangle_id = triangle_references[j];
// triangle intersection code ...
}
}
# 2 Многоуровневая реализация
Моя вторая реализация объясняет тот факт, что несколько листьев могут пересекаться. Тем не менее, эта реализация в 36 раз медленнее, чем реализация # 1 (хорошо, я пропускаю некоторые тесты пересечения в #1, но все же...).
bool[boxes.length()] hits;
hits[0] = intersect_box(boxes[0], ray);
for (int i = 1; i < boxes_count; i++) {
if (hits[boxes[i].parent]) {
hits[i] = intersect_box(boxes[i], ray);
} else {
hits[i] = false;
}
}
for (int i = 0; i < boxes_count; i++) {
if (!hits[i]) {
continue;
}
// only leaves have ids_offset and ids_count defined (not set to -1)
if (boxes[i].ids_offset < 0) {
continue;
}
uint a = boxes[i].ids_offset;
uint b = a + boxes[i].ids_count;
for (uint j = a; j < b; j++) {
uint triangle_id = triangle_references[j];
// triangle intersection code ...
}
}
Эта разница в производительности сводит меня с ума. Кажется, только одно заявление, как if(dynamically_modified_array[some_index]) оказывает огромное влияние на производительность. Я подозреваю, что компилятор SPIR-V или GPU больше не может делать свою магию оптимизации? Итак, вот мои вопросы:
Это действительно проблема оптимизации?
Если да, могу ли я преобразовать реализацию № 2 для лучшей оптимизации? Можно ли как-нибудь дать подсказки по оптимизации?
Существует ли стандартный способ реализации запросов дерева BVH в шейдерах?
1 ответ
После некоторых копаний я нашел решение. Важно понимать, что дерево BVH не исключает возможности оценки всех листьев.
Реализация № 3 ниже, использует ссылки попадания и пропуска. Ящики должны быть отсортированы таким образом, чтобы в худшем случае все они запрашивались в правильном порядке (поэтому достаточно одного цикла). Однако ссылки используются для пропуска узлов, которые не нужно оценивать. Когда текущий узел является листовым узлом, выполняются фактические треугольные пересечения.
- Ссылка на попадание ~ к какому узлу перейти в случае попадания (зеленый внизу)
- ссылка на мисс ~, к какому узлу перейти в случае пропуска (красный внизу)
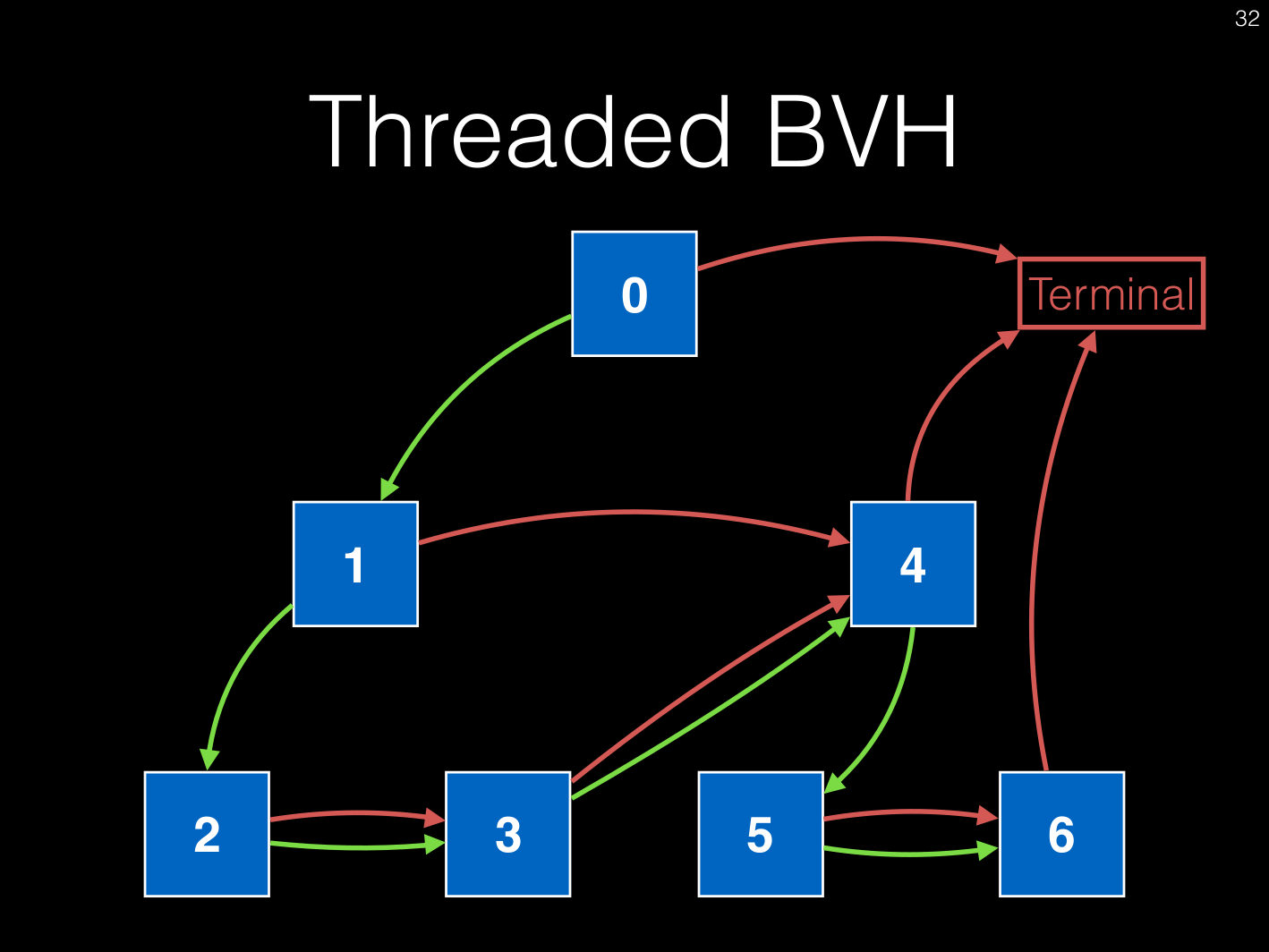
Изображение взято отсюда. Соответствующая статья и исходный код также есть на странице профессора Тошии Хачисуки. Та же самая концепция также описана в этой статье, на которую ссылаются слайды.
#3 Дерево BVH с ссылками Hit и Miss
Мне пришлось расширить данные, которые передаются в шейдер с помощью ссылок. Кроме того, для правильного хранения дерева потребовалось некоторое автономное переключение. Сначала я попытался использовать цикл while (цикл до box_index_next -1), что снова привело к сумасшедшему замедлению. В любом случае, работает достаточно быстро:
int box_index_next = 0;
for (int box_index = 0; box_index < boxes_count; box_index++) {
if (box_index != box_index_next) {
continue;
}
bool hit = intersect_box(boxes[box_index], ray);
bool leaf = boxes[box_index].ids_count > 0;
if (hit) {
box_index_next = boxes[box_index].links.x; // hit link
} else {
box_index_next = boxes[box_index].links.y; // miss link
}
if (hit && leaf) {
uint a = boxes[box_index].ids_offset;
uint b = a + boxes[box_index].ids_count;
for (uint j = a; j < b; j++) {
uint triangle_id = triangle_references[j];
// triangle intersection code ...
}
}
}
Этот код примерно в 3 раза медленнее, чем быстрая, но ошибочная реализация #1. Это несколько ожидаемо, теперь скорость зависит от реального дерева, а не от оптимизации GPU. Рассмотрим, например, вырожденный случай, когда треугольники выровнены вдоль оси: луч в одном и том же направлении может пересекаться со всеми треугольниками, тогда необходимо оценить все листья дерева.
Профессор Тошия Хатисука предлагает дальнейшую оптимизацию для таких случаев в своих полях (стр. 36 и далее): один хранит несколько версий дерева BVH, пространственно отсортированных по x, -x, y, -y, z и -z. Для обхода необходимо выбрать правильную версию на основе луча. Тогда можно остановить прохождение, как только треугольник с листа пересекается, так как все оставшиеся узлы, которые нужно посетить, будут пространственно позади этого узла (с точки зрения луча).