Платформа Entity Component System Framework, поддерживающая кеш процессора
Я не могу найти единую реализацию инфраструктуры, которая бы поддерживала кэш-память ЦП, а это означает, что данные, по которым проходят системы в каждом цикле игрового цикла, хранятся в непрерывной памяти.
Давайте посмотрим, системы переходят на конкретные объекты, которые удовлетворяют их условиям, т.е. объект должен содержать компоненты A, B, C, которые должны обрабатываться системой X. Это означает, что мне нужна непрерывная память, которая содержит все объекты и компоненты (не ссылки, поскольку ссылки не поддерживают кэш-память, и у вас будет много пропусков кэша), чтобы получить их из ОЗУ настолько быстро, насколько это возможно. во время обработки X системы. Но сразу после обработки X-системы Y-система начинает работать с набором объектов, которые удовлетворяют ее условиям, например, все объекты, содержащие A и B. Это означает, что мы имеем дело с тем же набором объектов, что и X-система, а также с некоторыми другими объектами, которые есть A и B. Это означает, что у нас есть две смежные памяти, которые имеют дубликаты данных. Во-первых, дублирование данных очень плохо по известным причинам. А также это, в свою очередь, означает, что нам нужна синхронизация, которая опять-таки не является дружественной к кэш-памяти ЦП, поскольку вам нужно найти некоторые объекты из одного вектора и обновить новыми данными, содержащимися в другом векторе.
Это только одна из моих мыслей. Существуют и другие, более реалистичные идеи для модели данных Entity Component System Framework, но в каждой модели, которую я мог выяснить, есть одна и та же проблема: во время каждого цикла игрового цикла вы не можете предотвратить множество пропусков кэша из-за несмежных данных.
Может ли кто-нибудь предложить реализацию, статью, пример просто кое-что по этой теме, которое может помочь мне понять, какую модель данных следует использовать для получения дизайна, дружественного к кешу, поскольку это одна из самых важных вещей в производительности игры.
3 ответа
Я хотел бы пойти с ответом нежелательной (так как я написал связанную статью;)), но вот другой, другой, взять на себя это:
Если вы хотите кэш-дружественный дизайн, вам нужно перечислить:
- Ваш микропроцессор
- Ваша архитектура процессора
- Ваша автобусная архитектура
- ...
- Ваш размер рабочего набора для каждого подкадра
- Ваш общий рабочий набор / RAM для всех игровых объектов
- Количество взаимосвязей в вашей конкретной игре
- ... так далее
В зависимости от того, насколько жесткими или неочевидными являются эти требования, вам придется принимать различные простые (или сложные) решения относительно своего дизайна. Разработчики игр часто переписывают mem-management. Они делают это не потому, что они глупые, они делают это потому, что легко / стоит (ре) оптимизировать для каждого проекта (это название AAA или название AA? Является ли графика более важной? Или сетевая задержка?). и т. д.) и для каждого аппаратного обеспечения (на ПК целевое оборудование меняется каждый месяц)
Я рекомендую вам выбрать набор аппаратного обеспечения, создать простую игру на основе ES и запустить tryign, чтобы спроектировать использование кэша с дружественным кешированием - и документировать его публично, сделать его открытым для всех и посмотреть, сможете ли вы заинтересовать других людей. в запуске ваших тестов.
Адам Мартин /t=machine недавно опубликовал Структуры данных для Entity Systems: непрерывная память - это единственная статья, посвященная разметке памяти в ECS, о которой я знаю.
Вы не указываете язык, но в мире java entreri и artemis-odb (через PackedComponents / также, disclaimer: my port) обрабатывают то, что Адам называет "Итерация 1: BigArray для ComponentType".
Теоретически я думаю, что эта проблема требует слишком больших усилий, чтобы оправдать время, которое может потребоваться, чтобы решить ее идеально. Я уже слишком много времени уделял этому в прошлом, придумывая замысловатые решения, чтобы вернуться к более простому. Наши самые большие горячие точки не обязательно будут возникать из-за необязательных промахов кэша для обхода сущности / компонента. Многие системы будут выполнять свою тяжелую работу для конкретного объекта, которая может быть ускорена, и многие компоненты часто будут достаточно большими, чтобы уменьшить преимущества попыток сортировать их таким образом, чтобы несколько соседей соответствовали минимальному числу строки кэша.
Тем не менее, если вы просто хотите, скажем, отсортировать компоненты таким образом, чтобы обеспечить удобные для кэша шаблоны доступа к памяти, но только для одной или двух критически важных систем без перекрывающихся конфликтов и, возможно, для самых крошечных и самых многочисленных типов компонентов, где это связано чтобы помочь наиболее, это достаточно легко сделать с некоторой постобработкой здесь и там. Я рекомендую искать это вместо этого в ответ на ваши горячие точки.
И часто просто некоторая базовая сортировка помогает вам сократить долю пропущенных кеш-памяти для всех систем, независимо от того, какую комбинацию компонентов они обрабатывают. Если вы начнете с такого представителя (как я использую):
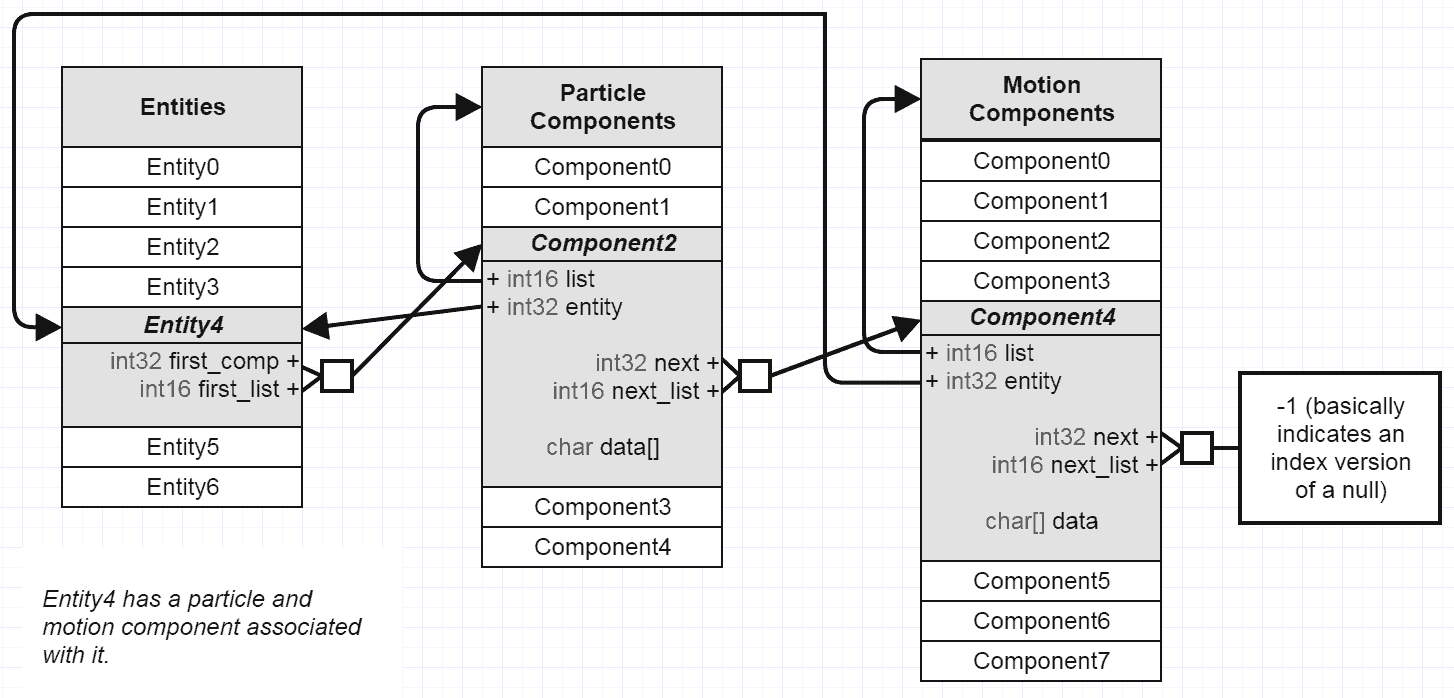
И через некоторое время запуска состояния игры, а также спорадического удаления и добавления компонентов вы получите что-то вроде этого:
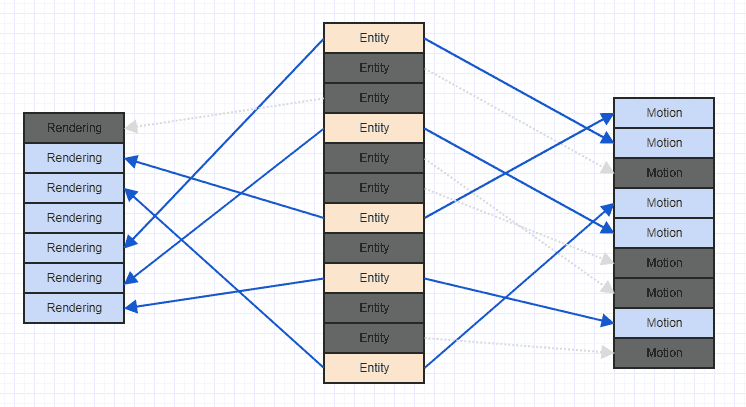
Вы можете распутать беспорядок и разобраться так:
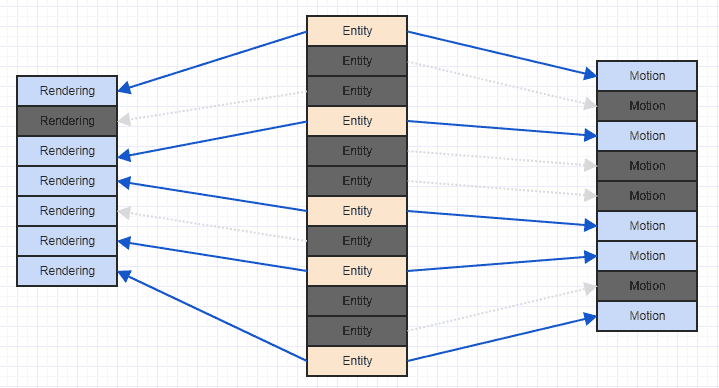
Это можно сделать очень дешево с помощью радикальной сортировки, сортируя элементы на основе индекса сущности, которому они принадлежат как ключ в линейном времени. При достойной реализации вы, как правило, можете скрыть это, не замечая никаких сбоев в частоте кадров. Я нарисовал диаграмму не так, как в приведенной выше таблице данных (просто чтобы понять, какой компонент принадлежит какому-либо объекту), но идея та же. Просто радикально отсортируйте массив компонентов на основе индекса объекта (ID объекта), обновите ссылки (используйте параллельный массив для отображения индексов до / после, который сортируется вместе с данными компонента с использованием индекса объекта в качестве ключа), и теперь все все красиво и аккуратно и не запутано со случайными моделями доступа.
Это может не дать системе, заинтересованной в конкретной комбинации объектов, совершенно непрерывный набор компонентов (могут быть некоторые пробелы, как на приведенной выше диаграмме), но, по крайней мере, она не будет перемещаться назад и вперед и назад в памяти, возможно, потребуется загрузить область памяти в строку кеша только для того, чтобы вытеснить ее, а затем вернуться и перезагрузить ее снова, и, вероятно, существует высокая вероятность того, что во многих случаях к этим компонентам будет обращаться последовательно.
И если этого недостаточно, то с учетом конкретных рассматриваемых сущностей, в которых есть именно те компоненты, которые интересуют систему для определенного запроса, вы можете отсортировать компоненты в верхней части массива по тем конкретным сущностям, которые нужны системе, закрывая любые промежутки, и теперь у вас есть идеальная смежность для системы, в частности, для обработки сущностей, которые содержат компоненты движения и рендеринга. Это также может быть сделано в линейном времени с пост-обработкой здесь и там, может применяться периодически после удаления и добавления ряда компонентов.
Я никогда не видел необходимости заходить так далеко. Я просто время от времени делаю обобщенную сортировку по идентификаторам сущностей, чтобы в целом улучшить шаблоны доступа ко всем системам (но без оптимального решения для любой конкретной системы). Ваш вариант использования может потребовать оптимальной версии, но я бы предложил сосредоточиться на ключевых системах с большими точками доступа, которые действительно выигрывают от этого.