TensorFlow MNIST DCGAN: как настроить функцию потерь?
Я хотел бы создать DCGAN для MNIST самостоятельно в TensorFlow. Тем не менее, я изо всех сил пытаюсь выяснить, как мне установить функцию потерь для генератора. В реализации Keras DCGAN автор использовал небольшой "обходной путь" для этой проблемы: он просто построил 3 модели. Генератор (G), дискриминатор (D) и третий, где он только что скомбинировал G с D, при этом установив способность поезда D к значению false.
Таким образом, он может кормить D реальными изображениями + сгенерированными изображениями, чтобы обучать D и обучать комбинированную модель G+D, потому что потеря D распространяется на G, так как D не обучаем в комбинированной модели G+D.
В TensorFlow я уже построил G и D. Обучение D относительно простое, поскольку мне просто нужно объединить партию реальных обучающих образов MNIST с созданными и вызвать учебную операцию:
session.run(D_train_op,
feed_dict={x: batch_x, y: batch_y})
В этом примере обучающая операция представляет собой двоичную кросс-энтропию:
tf.losses.softmax_cross_entropy(y, D_out)
... но как мне настроить функцию потерь для G, если у меня нет "сложенной" модели, объединяющей "G и D" в одну, третью модель?
Я знаю, что мне нужно сгенерировать пакет изображений с помощью G, передать их в D, и тогда я смогу получить потерю D... однако вывод G имеет форму (batch_size, 28, 28, 1), Как бы я настроить функцию потерь для G вручную?
Без "обходного пути" для комбинированной модели "G and D" мне придется распространять потерю D, которая имеет выходную форму (batch_size, 1) на выходной слой Г.
Например, если G выполнит некоторую классификацию, это будет не так сложно выяснить... но G выводит изображения. Таким образом, я не могу напрямую отобразить потерю D на выходной слой G.
Нужно ли настраивать третью модель, сочетающую G+D? Или есть способ рассчитать потери для G вручную?
Любая помощь высоко ценится:)
1 ответ
На этапе обучения генератора вы можете подумать, что в сети также используется дискриминатор. Но чтобы сделать обратное распространение, вы будете учитывать только веса генератора. Хорошее объяснение этому можно найти здесь.
Как упоминалось в оригинальной статье, стоимость дискриминатора составляет:
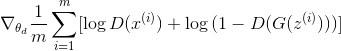
А стоимость генератора составляет:
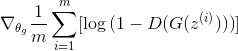
Конечно, вам не нужно рассчитывать это вручную. Tensorflow уже справляется с этим. Чтобы сделать весь процесс, вы можете реализовать следующее:
G_sample = generator(z)
D_real = discriminator(X)
D_fake = discriminator(G_sample)
D_loss = tf.reduce_mean(-tf.log(D_real)-tf.log(1-D_fake))
G_loss = tf.reduce_mean(-tf.log(D_fake))
где D_real, D_fake и D_sample - последние уровни вашей сети. Тогда вы можете реализовать тренировочный процесс стандартным способом:
D_solver = (tf.train.AdamOptimizer(learning_rate=0.0001,beta1=0.5)
.minimize(D_loss, var_list=theta_D))
G_solver = (tf.train.AdamOptimizer(learning_rate=0.0001,beta1=0.5)
.minimize(G_loss, var_list=theta_G))
И просто запустите решатели на сессии.