Прогнозирование временных рядов в нейронной сети (прогнозирование с опережением по N точкам) Итеративное обучение в крупном масштабе
(N=90) Предсказание точки вперед с использованием нейронной сети:
Я пытаюсь предсказать 3 минуты впереди, т.е. 180 пунктов впереди. Поскольку я сжал данные своего временного ряда, приняв среднее значение каждых 2 точек за единицу, я должен предсказать (N=90) прогнозирование с опережением.
Мои данные временных рядов приведены в секундах. Значения находятся в диапазоне 30-90. Они обычно перемещаются с 30 на 90 и с 90 на 30, как видно из приведенного ниже примера.
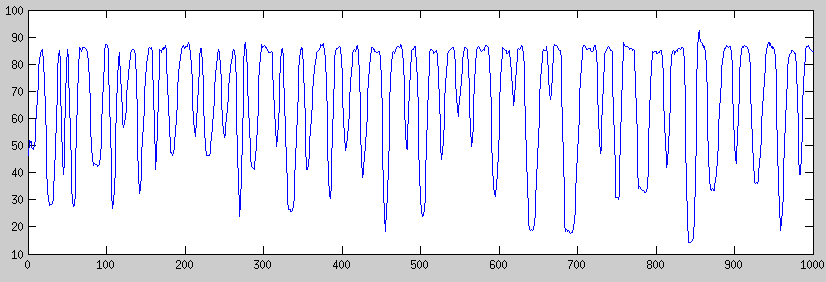
Мои данные могут быть доступны с: https://www.dropbox.com/s/uq4uix8067ti4i3/17HourTrace.mat
У меня возникли проблемы с внедрением нейронной сети для прогнозирования N точек вперед. Моя единственная особенность в прошлый раз. Я использовал рекуррентную нейронную сеть Элмана, а также newff.
В моем сценарии мне нужно прогнозировать 90 баллов вперед. Сначала, как я разделил свои входные и целевые данные вручную: Например:
data_in = [1,2,3,4,5,6,7,8,9,10]; //imagine 1:10 only defines the array index values.
N = 90; %predicted second ahead.
P(:, :) T(:) it could also be(2 theta time) P(:, :) T(:)
[1,2,3,4,5] [5+N] | [1,3,5,7,9] [9+N]
[2,3,4,5,6] [6+N] | [2,4,6,8,10] [10+N]
...
пока он не достигнет конца данных
У меня есть 100 входных точек и 90 выходных точек в рекуррентных нейронных сетях Элмана. Какой может быть самый эффективный скрытый размер узла?
input_layer_size = 90;
NodeNum1 =90;
net = newelm(threshold,[NodeNum1 ,prediction_ahead],{'tansig', 'purelin'});
net.trainParam.lr = 0.1;
net.trainParam.goal = 1e-3;
// В начале моего обучения я фильтрую его с помощью Калмана, нормализуя в диапазоне [0,1], и после этого я перетасовываю данные. 1) Я не смогу тренировать свои полные данные. Сначала я попытался подготовить полные данные M, что составляет около 900 000, что не дало мне решения.
2) Во-вторых, я пытался многократно тренироваться. Но на каждой итерации новые добавленные данные объединяются с уже обученными данными. После 20 000 обученных данных точность начинает снижаться. Первая обученная 1000 данных идеально подходит для обучения. Но после того, как я начну повторное объединение новых данных и продолжу обучение, точность обучения очень быстро падает, например, с 90 до 20. Например.
P = P_test(1:1000) T = T_test(1:1000) counter = 1;
while(1)
net = train(net,P,T, [], [] );%until it reaches to minimum error I train it.
[normTrainOutput] = sim(net,P, [], [] );
P = [ P P(counter*1000:counter*2000)]%iteratively new training portion of the data added.
counter = counter + 1; end
Этот подход очень медленный и после определенного момента он не даст никаких хороших результатов.
Мой третий подход был итеративным обучением; Это было похоже на предыдущее обучение, но на каждой итерации я тренирую только 1000 частей данных, не объединяя их с предыдущими обученными данными. Например, когда я тренирую первые 1000 данных, пока они не достигнут минимальной ошибки, которая имеет>95% точность. После обучения, когда я проделал то же самое для второй 1000-й порции данных, он перезаписывает вес, и предиктор в основном ведет себя как последняя порция данных.
> P = P_test(1:1000) T = T_test(1:1000) counter = 1;
while(1)
> net = train(net,P,T, [], [] ); % I did also use adapt()
> [normTrainOutput] = sim(net,P, [], [] );
>
> P = [ P(counter*1000:counter*2000)]%iteratively only 1000 portion of the data is added.
> counter = counter + 1;
end
Обученные данные: эта цифра является снимком моего обученного тренировочного набора, синяя линия - это исходный временной ряд, а красная линия - это прогнозируемые значения с обученной нейронной сетью. MSE около 50 лет.

Проверенные данные: на следующем рисунке вы можете увидеть мой прогноз для моих данных тестирования с нейронной сетью, которая обучается с 20 000 входных точек, сохраняя ошибку MSE <50 для набора обучающих данных. Он способен поймать несколько паттернов, но в основном я не даю по-настоящему хорошей точности.
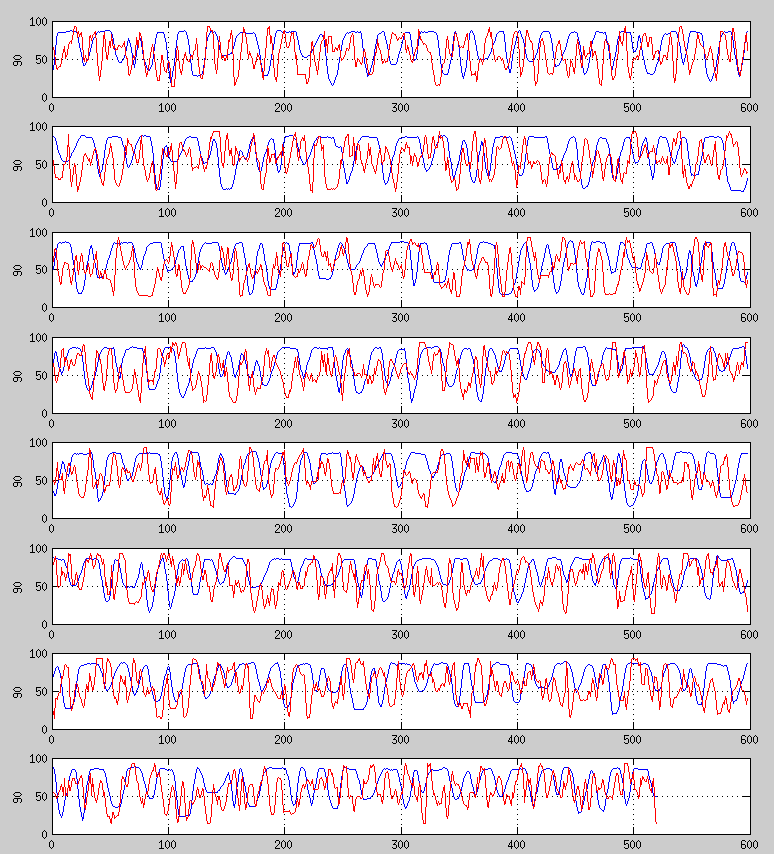
Я не смог добиться успеха ни одним из этих подходов. В каждой итерации я также наблюдаю, что небольшое изменение в альфа полностью перезаписывает уже обученные данные и больше фокусируется на текущей обучаемой части данных. Я не смогу найти решение этой проблемы. В итеративном обучении я должен сохранять малую скорость обучения и малое количество эпох.
И я не мог найти эффективный способ прогнозировать 90 пунктов вперед во временных рядах. Любые предложения, что я должен сделать, чтобы предсказать N пунктов впереди, любой учебник или ссылку для информации.
Каков наилучший способ повторного обучения? При втором подходе, когда я достигаю 15 000 обученных данных, размер обучения начинает внезапно уменьшаться. Итеративно я должен изменить альфа во время выполнения?
==========
Любое предложение или вещи, которые я делаю неправильно, будут очень благодарны.
Я также реализовал рекуррентную нейронную сеть. Но при обучении для больших данных я столкнулся с теми же проблемами. Можно ли выполнить адаптивное обучение (онлайн-обучение) в Recurrent Neural Networks для (newelm)? Вес не обновится сам, и я не увидел никаких улучшений.
Если да, то как это возможно, какие функции мне следует использовать?
net = newelm(threshold,[6, 8, 90],{'tansig','tansig', 'purelin'});
net.trainFcn = 'trains';
batch_size = 10;
while(1)
net = train(net,Pt(:, k:k+batch_size ) , Tt(:, k:k+batch_size) );
end
2 ответа
Взгляните на Echo State Networks (ESN) или другие формы резервуарных вычислений. Они идеально подходят для прогнозирования временных рядов, очень просты в использовании и быстро сходятся. Вам не нужно беспокоиться о структуре сети (каждый нейрон в среднем слое имеет случайные веса, которые не меняются). Вы только узнаете выходные веса.
Если бы я правильно понял проблему с сетями Echo State Network, я бы просто обучил сеть прогнозировать следующую точку И 90 пунктов вперед. Это можно сделать, просто форсируя желаемый выход в выходных нейронах, а затем выполняя регрессию гребня, чтобы узнать веса выходного сигнала.
При запуске сети после ее обучения на каждом шаге n будет выводиться следующая точка (n + 1), которую вы будете возвращать в сеть в качестве входных данных (для продолжения итерации), и на 90 пунктов вперед (n + 90), с которой вы можете делать все, что хотите, то есть: вы также можете передавать его обратно в сеть, чтобы он влиял на следующие выходы.
Извините, если ответ не очень понятен. В кратком ответе трудно объяснить, как работают резервуарные вычисления, но если вы просто прочитаете статью в ссылке, вам будет очень легко понять принципы.
Если вы решили использовать ESN, прочитайте этот документ, чтобы понять наиболее важные свойства ESN и действительно знать, что вы делаете.
РЕДАКТИРОВАТЬ: В зависимости от того, насколько "предсказуема" ваша система, прогнозирование 90 пунктов впереди может быть все еще очень трудным. Например, если вы пытаетесь предсказать хаотическую систему, шум может привести к очень большим ошибкам, если вы прогнозируете далеко вперед.
Используйте нечеткую логику, используя функцию принадлежности, чтобы предсказать будущие данные. будет эффективным методом.