STL разложение временных рядов с отсутствующими значениями для обнаружения аномалий
Я пытаюсь обнаружить аномальные значения во временном ряду климатических данных с некоторыми отсутствующими наблюдениями. При поиске в Интернете я нашел много доступных подходов. Из них stl-разложение кажется привлекательным в смысле удаления трендовых и сезонных компонентов и изучения остатка. Чтение STL: процедура разложения по сезонным трендам На основе Loess, stl, по-видимому, гибко определяет параметры для задания изменчивости, не зависит от выбросов и может применяться, несмотря на пропущенные значения. Тем не менее, пытаясь применить его в R, с четырехлетним наблюдением и определением всех параметров в соответствии с http://stat.ethz.ch/R-manual/R-patched/library/stats/html/stl.html, я возникла ошибка:
"временной ряд содержит внутренние NA", когда na.action=na.omit,
и "ряд не является периодическим или имеет менее двух периодов", когда na.action = na.exclude.
Я дважды проверил, что частота правильно определена. Я видел соответствующие вопросы в блогах, но не нашел ни одного предложения, которое могло бы решить эту проблему. Разве нельзя применить stl в серии с пропущенными значениями? Я очень неохотно их интерполирую, так как не хочу вводить (и, следовательно, обнаруживать...) артефакты. По той же причине я не знаю, насколько целесообразно было бы вместо этого использовать подходы ARIMA (и если пропущенные значения все еще будут проблемой).
Пожалуйста, поделитесь, если вы знаете способ применения stl в серии с пропущенными значениями, или если вы считаете, что мой выбор методологически не обоснован, или если у вас есть какие-либо лучшие предложения. Я совершенно новичок в этой области и поражен кучей (казалось бы...) соответствующей информации.
2 ответа
В начале stl мы находим
x <- na.action(as.ts(x))
и вскоре после этого
period <- frequency(x)
if (period < 2 || n <= 2 * period)
stop("series is not periodic or has less than two periods")
То есть, stl надеется x быть ts объект после na.action(as.ts(x)) (иначе period == 1). Давайте проверим na.omit а также na.exclude первый.
Понятно, что в конце getAnywhere("na.omit.ts") мы нашли
if (any(is.na(object)))
stop("time series contains internal NAs")
что просто и ничего не поделаешь (na.omit не исключает NAs от ts объекты). Сейчас getAnywhere("na.exclude.default") исключает NA наблюдения, но возвращает объект класса exclude:
attr(omit, "class") <- "exclude"
и это другая ситуация. Как уже упоминалось выше, stl надеется na.action(as.ts(x)) быть ts, но na.exclude(as.ts(x)) имеет класс exclude,
Следовательно, если человек удовлетворен NAs исключение, например,
nottem[3] <- NA
frequency(nottem)
# [1] 12
na.new <- function(x) ts(na.exclude(x), frequency = 12)
stl(nottem, na.action = na.new, s.window = "per")
работает. В общем, stl не работает с NA значения (т.е. с na.action = na.pass), он падает глубже в Фортране (см. полный исходный код здесь):
z <- .Fortran(C_stl, ...
Альтернативы na.new не восхитительны
na.contaguous- находит самый длинный последовательный отрезок не пропущенных значений в объекте временного ряда.na.approx,na.locfотzooили какая-то другая интерполяционная функция.- Не уверен насчет этого, но другую реализацию на Фортране можно найти здесь для Python. Можно использовать Python для возможной установки R из исходного кода после некоторых модификаций, если этот модуль действительно допускает пропущенные значения.
Как мы видим из статьи, не существует какой-то простой процедуры для пропущенных значений (например, аппроксимации их в самом начале), которую можно было бы применить к временным рядам перед вызовом stl, Поэтому, учитывая тот факт, что оригинальная реализация является довольно продолжительной, я бы подумал о некоторых других альтернативах, чем полностью новая реализация.
Обновление: довольно оптимальный выбор во многих аспектах, когда NAs может быть na.approx от zooИтак, давайте проверим его производительность, то есть сравним результаты stl с полным набором данных и результатов при наличии некоторого количества NAs, с помощью na.approx, Я использую MAPE как меру точности, но только для тренда, потому что сезонный компонент и остаток пересекают ноль, и это исказит результат. Позиции для NAs выбираются случайным образом.
library(zoo)
library(plyr)
library(reshape)
library(ggplot2)
mape <- function(f, x) colMeans(abs(1 - f / x) * 100)
stlCheck <- function(data, p = 3, ...){
set.seed(20130201)
pos <- lapply(3^(0:p), function(x) sample(1:length(data), x))
datasetsNA <- lapply(pos, function(x) {data[x] <- NA; data})
original <- data.frame(stl(data, ...)$time.series, stringsAsFactors = FALSE)
original$id <- "Original"
datasetsNA <- lapply(datasetsNA, function(x)
data.frame(stl(x, na.action = na.approx, ...)$time.series,
id = paste(sum(is.na(x)), "NAs"),
stringsAsFactors = FALSE))
stlAll <- rbind.fill(c(list(original), datasetsNA))
stlAll$Date <- time(data)
stlAll <- melt(stlAll, id.var = c("id", "Date"))
results <- data.frame(trend = sapply(lapply(datasetsNA, '[', i = "trend"), mape, original[, "trend"]))
results$id <- paste(3^(0:p), "NAs")
results <- melt(results, id.var = "id")
results$x <- min(stlAll$Date) + diff(range(stlAll$Date)) / 4
results$y <- min(original[, "trend"]) + diff(range(original[, "trend"])) / (4 * p) * (0:p)
results$value <- round(results$value, 2)
ggplot(stlAll, aes(x = Date, y = value, colour = id, group = id)) + geom_line() +
facet_wrap(~ variable, scales = "free_y") + theme_bw() +
theme(legend.title = element_blank(), strip.background = element_rect(fill = "white")) +
labs(x = NULL, y = NULL) + scale_colour_brewer(palette = "Set1") +
lapply(unique(results$id), function(z)
geom_text(data = results, colour = "black", size = 3,
aes(x = x, y = y, label = paste0("MAPE (", id, "): ", value, "%"))))
}
nottem240 наблюдений
stlCheck(nottem, s.window = 4, t.window = 50, t.jump = 1)
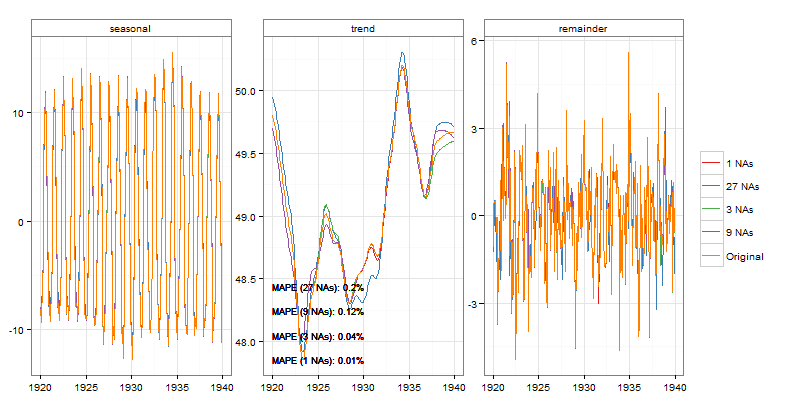
co2468 наблюдений
stlCheck(log(co2), s.window = 21)

mdeaths, 72 наблюдения
stlCheck(mdeaths, s.window = "per")
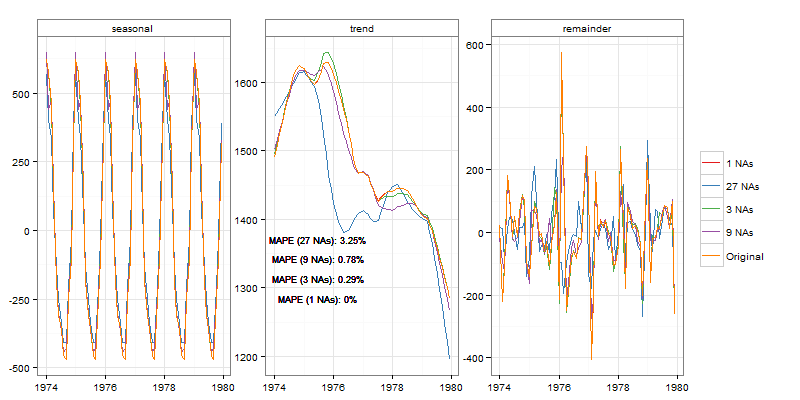
Визуально мы видим некоторые различия в тренде в случаях 1 и 3. Но эти различия довольно малы в 1, а также удовлетворительны в 3, учитывая размер выборки (72).
Понимаю, что это старый вопрос, но думал, что я буду обновлять, так как есть более новый stl Пакет доступен в R называется stlplus, Вот его домашняя страница на github. Вы можете установить его из CRAN с install.packages("stlplus") или прямо из GitHub с devtools::install_github("hafen/stlplus"),