statsmodel ARMA в выборочном прогнозировании
Я использую statsmodel ARMA() оценить моделируемое MA(1) процесс:
import statsmodels.tsa.api as smt
import numpy as np
import matplotlib.pyplot as plt
# Simulate an MA(1) process
n = int(1000)
alphas = np.array([0.])
betas = np.array([0.6])
ar = np.r_[1, -alphas]
ma = np.r_[1, betas]
ma1 = smt.arma_generate_sample(ar=ar, ma=ma, nsample=n) #input
# Fit the MA(1) model to our simulated time series
max_lag = 30
mdl = smt.ARMA(ma1, order=(0, 1)).fit(maxlag=max_lag, method='mle', trend='nc')
# in sample predict
pred = mdl.predict()
#plotting
plt.style.use('bmh')
fig = plt.figure(figsize=(9,7))
ax = plt.gca()
plt.plot(ma1, label='Actual')
plt.plot(pred, 'r-', label = "In-sample predict")
plt.legend(loc='upper left')
Я получаю следующее:
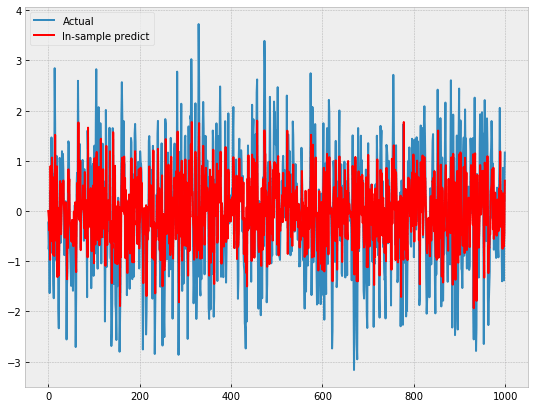
Прогноз в выборке, кажется, масштабируется. Это почему?
Я также построил кумулятивную сумму фактического и прогнозного значений, учитывая, что обычно мы делаем разность первого порядка для интеграции данных.
fig = plt.figure(figsize=(9,7))
ax = plt.gca()
plt.plot(ma1.cumsum(), label='Actual')
plt.plot(pred.cumsum(), 'r-', label='Predict')
plt.legend(loc='upper left')
Я получил что-то вроде этого:
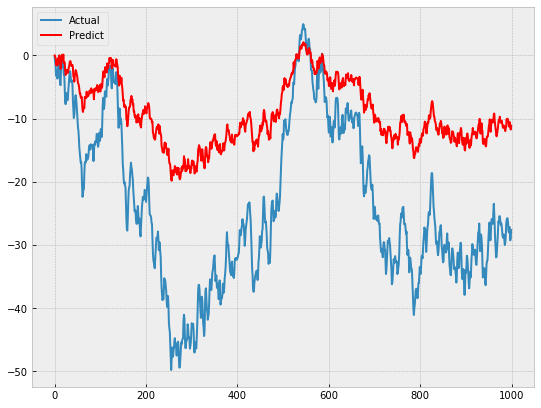
Я сделал что-то не так? Почему весы так отключены?
1 ответ
Это не очень значимый сюжет или упражнение.
Вы накапливаете прогнозы на один шаг вперед, которые начинаются на разных уровнях, заданных историей для этого наблюдения или в этот момент времени.
Модель с первым различием может быть оценена и предсказана как ARIMA(0,1,1). В этом случае прогноз уровня `typ="level") основан на предсказанных изменениях, добавленных к наблюдению в предыдущий момент времени.