Интерполяция с использованием ExponentialSmoothing из моделей статистики
Я использую ExponentialSmoothing от statsmodels для запуска метода Холта-Винтерса на временных рядах. Я получаю прогнозные значения, но не могу извлечь рассчитанные значения и сравнить их с наблюдаемыми значениями.
from pandas import Series
from scipy import stats
import statsmodels.api as sm
from statsmodels.tsa.api import ExponentialSmoothing
modelHW = ExponentialSmoothing(np.asarray(passtrain_df['n_passengers']), seasonal_periods=12, trend='add', seasonal='mul',).fit()
y_hat_avg['Holt_Winter'] = modelHW.forecast(prediction_size)
Так вот, prediction_size = number of forecasted datapoints (4 в моем случае)passtrain_df представляет собой фрейм данных с наблюдениями (140 точек данных), на основе которых строится модель Holt_Winter (регрессия).
Я легко могу отобразить 4 прогнозных значения.
Как извлечь 140 рассчитанных значений?
Пытался использовать:
print(ExponentialSmoothing.predict(np.asarray(passtrain_df), start=0, end=139))
Но у меня, вероятно, где-то есть синтаксическая ошибка
Спасибо!
1 ответ
Редактировать:
Заменен синтетический набор данных с образцами данных из OP
Исправлена функция, которая строит новый прогнозный период
Исправлен формат даты по оси X согласно запросу OP
Ответ:
Если вы ищете рассчитанные значения в течение периода оценки, вы должны использовать modelHW.fittedvalues и не modelHW.forecast(), Последний даст вам только то, что он говорит; прогнозы. И это довольно круто. Позвольте мне показать вам, как сделать обе вещи:
График 1 - Модель в течение периода оценки
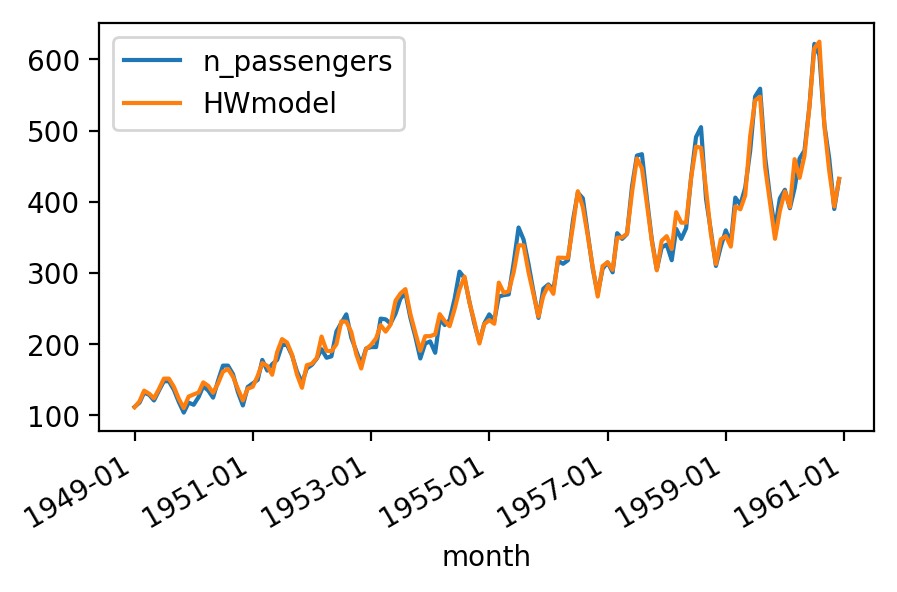
Сюжет 2 - Прогнозы
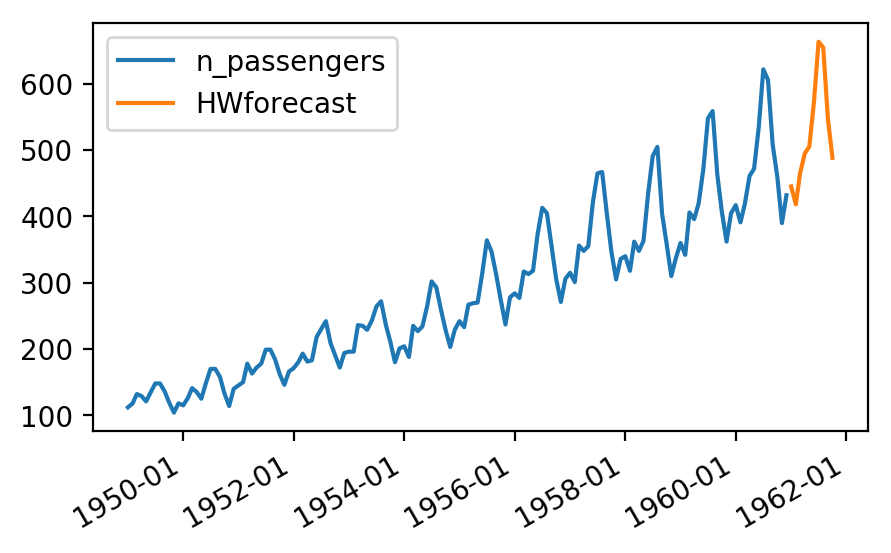
Код:
#imports
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from statsmodels.tsa.api import ExponentialSmoothing
import matplotlib.dates as mdates
#%%
#
# Load data
pass_df = pd.read_csv('https://raw.githubusercontent.com/dacatay/time-series-analysis/master/data/passengers.csv', sep=';')
pass_df = pass_df.set_index('month')
type(pass_df.index)
df = pass_df.copy()
# Model
modelHW = ExponentialSmoothing(np.asarray(df['n_passengers']), seasonal_periods=12, trend='add', seasonal='mul',).fit()
modelHW.summary()
# Model, fitted values
model_values = modelHW.fittedvalues
model_period = df.index
df_model = pd.concat([df['n_passengers'], pd.Series(model_values, index = model_period)], axis = 1)
df_model.columns = ['n_passengers', 'HWmodel']
df_model = df_model.set_index(pd.DatetimeIndex(df_model.index))
# Model, plot
fig, ax = plt.subplots()
myFmt = mdates.DateFormatter('%Y-%m')
df_model.plot(ax = ax, x_compat=True)
ax.xaxis.set_major_formatter(myFmt)
# Forecasts
prediction_size = 10
forecast_values = modelHW.forecast(prediction_size)
# Forecasts, build new period
forecast_start = df.index[-1]
forecast_start = pd.to_datetime(forecast_start, format='%Y-%m-%d')
forecast_period = pd.period_range(forecast_start, periods=prediction_size+1, freq='M')
forecast_period = forecast_period[1:]
# Forecasts, create dataframe
df_forecast = pd.Series(forecast_values, index = forecast_period.values).to_frame()
df_forecast.columns = ['HWforecast']
# merge input and forecast dataframes
df_all = pd.merge(df,df_forecast, how='outer', left_index=True, right_index=True)
#df_all = df_all.set_index(pd.DatetimeIndex(df_all.index.values))
ix = df_all.index
ixp = pd.PeriodIndex(ix, freq = 'M')
df_all = df_all.set_index(ixp)
# Forecast, plot
fig, ax = plt.subplots()
myFmt = mdates.DateFormatter('%Y-%m')
df_all.plot(ax = ax, x_compat=True)
ax.xaxis.set_major_formatter(myFmt)
Предыдущие попытки:
# imports
import pandas as pd
import numpy as np
from statsmodels.tsa.api import ExponentialSmoothing
# Data that matches your setup, but with a random
# seed to make it reproducible
np.random.seed(42)
# Time
date = pd.to_datetime("1st of Jan, 2019")
dates = date+pd.to_timedelta(np.arange(140), 'D')
# Data
n_passengers = np.random.normal(loc=0.0, scale=5.0, size=140).cumsum()
n_passengers = n_passengers.astype(int) + 100
df = pd.DataFrame({'n_passengers':n_passengers},index=dates)
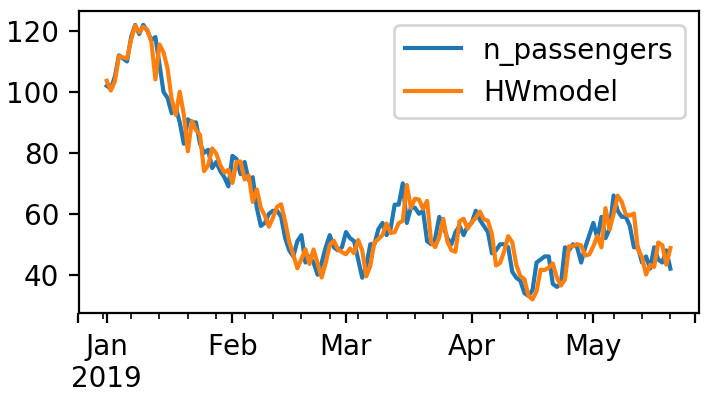
1. Как построить график наблюдаемых и оценочных значений в течение периода оценки:
Следующий фрагмент извлечет все установленные значения и отобразит их в соответствии с вашими наблюдаемыми значениями.
Фрагмент 2:
# Model
modelHW = ExponentialSmoothing(np.asarray(df['n_passengers']), seasonal_periods=12, trend='add', seasonal='mul',).fit()
modelHW.summary()
# Model, fitted values
model_values = modelHW.fittedvalues
model_period = df.index
df_model = pd.concat([df['n_passengers'], pd.Series(model_values, index = model_period)], axis = 1)
df_model.columns = ['n_passengers', 'HWmodel']
df_model.plot()
Участок 1:
2. Как составить и построить модельные прогнозы определенной длины:
Следующий фрагмент даст 10 прогнозов из вашей модели и отобразит их как расширенный период по сравнению с вашими значениями наблюдателя.
Фрагмент 3:
# Forecast
prediction_size = 10
forecast_values = modelHW.forecast(prediction_size)
forecast_period = df.index[-1] + pd.to_timedelta(np.arange(prediction_size+1), 'D')
forecast_period = forecast_period[1:]
df_forecast = pd.concat([df['n_passengers'], pd.Series(forecast_values, index = forecast_period)], axis = 1)
df_forecast.columns = ['n_passengers', 'HWforecast']
df_forecast.plot()
Сюжет 2:
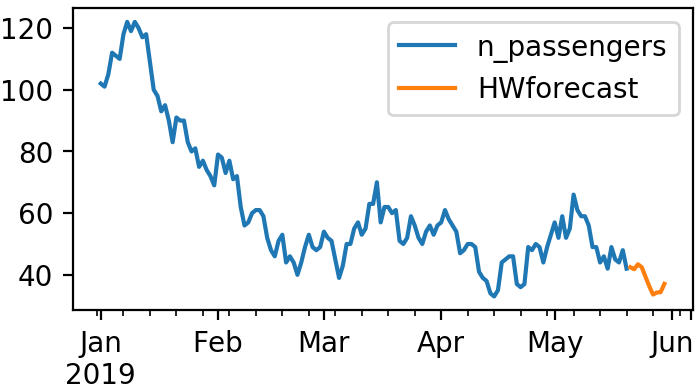
И вот все, что нужно для легкого копирования и вставки:
# imports
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from statsmodels.tsa.api import ExponentialSmoothing
# Data that matches your setup, but with a random
# seed to make it reproducible
np.random.seed(42)
# Time
date = pd.to_datetime("1st of Jan, 2019")
dates = date+pd.to_timedelta(np.arange(140), 'D')
# Data
n_passengers = np.random.normal(loc=0.0, scale=5.0, size=140).cumsum()
n_passengers = n_passengers.astype(int) + 100
df = pd.DataFrame({'n_passengers':n_passengers},index=dates)
# Model
modelHW = ExponentialSmoothing(np.asarray(df['n_passengers']), seasonal_periods=12, trend='add', seasonal='mul',).fit()
modelHW.summary()
# Model, fitted values
model_values = modelHW.fittedvalues
model_period = df.index
df_model = pd.concat([df['n_passengers'], pd.Series(model_values, index = model_period)], axis = 1)
df_model.columns = ['n_passengers', 'HWmodel']
df_model.plot()
# Forecast
prediction_size = 10
forecast_values = modelHW.forecast(prediction_size)
forecast_period = df.index[-1] + pd.to_timedelta(np.arange(prediction_size+1), 'D')
forecast_period = forecast_period[1:]
df_forecast = pd.concat([df['n_passengers'], pd.Series(forecast_values, index = forecast_period)], axis = 1)
df_forecast.columns = ['n_passengers', 'HWforecast']
df_forecast.plot()
@vestland - вот код и ошибка:
y_train = passtrain_df.copy(deep=True)
model_HW = ExponentialSmoothing(np.asarray(y_train['n_passengers']), seasonal_periods=12, trend='add', seasonal='mul',).fit()
model_values = model_HW.fittedvalues
model_period = y_train.index
hw_model = pd.concat([y_train['n_passengers'], pd.Series(model_values, index = model_period)], axis = 1)
hw_model.columns = ['Observed Passengers', 'Holt-Winters']
plt.figure(figsize=(18,12))
hw_model.plot()
forecast_values = model_HW.forecast(prediction_size)
forecast_period = y_train.index[-1] + pd.to_timedelta(np.arange(prediction_size+1),'D')
forecast_period = forecast_period[1:]
hw_forecast = pd.concat([y_train['n_passengers'], pd.Series(forecast_values, index = forecast_period)], axis = 1)
hw_forecast.columns = ['Observed Passengers', 'HW-Forecast']
hw_forecast.plot()
Ошибка:
NullFrequencyError Traceback (most recent call last)
<ipython-input-25-5f37a0dd0cfa> in <module>()
17
18 forecast_values = model_HW.forecast(prediction_size)
---> 19 forecast_period = y_train.index[-1] + pd.to_timedelta(np.arange(prediction_size+1),'D')
20 forecast_period = forecast_period[1:]
21
/anaconda3/lib/python3.6/site- packages/pandas/core/indexes/datetimelike.py in __radd__(self, other)
879 def __radd__(self, other):
880 # alias for __add__
--> 881 return self.__add__(other)
882 cls.__radd__ = __radd__
883
/anaconda3/lib/python3.6/site- packages/pandas/core/indexes/datetimelike.py in __add__(self, other)
842 # This check must come after the check for np.timedelta64
843 # as is_integer returns True for these
--> 844 result = self.shift(other)
845
846 # array-like others
/anaconda3/lib/python3.6/site-packages/pandas/core/indexes/datetimelike.py in shift(self, n, freq)
1049
1050 if self.freq is None:
-> 1051 raise NullFrequencyError("Cannot shift with no freq")
1052
1053 start = self[0] + n * self.freq
NullFrequencyError: Cannot shift with no freq