Машинное обучение - классификация одного класса / обнаружение новизны / оценка аномалий?
Мне нужен алгоритм машинного обучения, который будет удовлетворять следующим требованиям:
- Обучающие данные представляют собой набор векторов признаков, принадлежащих к одному и тому же "положительному" классу (поскольку я не могу произвести отрицательные выборки данных).
- Тестовые данные - это некоторые векторы функций, которые могут принадлежать или не принадлежать положительному классу.
- Прогноз должен быть непрерывным значением, которое должно указывать "расстояние" от положительных образцов (т. Е. 0 означает, что тестовый образец явно принадлежит к положительному классу, а 1 означает, что он явно отрицательный, но 0,3 означает, что он несколько положительный)
Пример: допустим, что векторы объектов - это векторы 2D объектов.
Положительные данные тренировки:
- (0, 1), (0, 2), (0, 3)
Тестовые данные:
- (0, 10) должна быть аномалией, но не отчетливой
- (1, 0) должна быть аномалией, но с более высоким "рангом", чем (0, 10)
- (1, 10) должна быть аномалией с еще более высоким "рангом" аномалии
1 ответ
Проблема, которую вы описали, обычно называется обнаружением выбросов, аномалий или новизны. Есть много методов, которые могут быть применены к этой проблеме. Хороший обзор методов обнаружения новинок можно найти здесь. В статье дается полная классификация методов и краткое описание каждого, но для начала я перечислю некоторые из стандартных:
- K-ближайшие соседи - простой метод, основанный на расстоянии, который предполагает, что нормальные выборки данных близки к другим нормальным выборкам данных, в то время как новые выборки расположены далеко от нормальных точек. Реализацию KNN на Python можно найти в ScikitLearn.
- Модели смесей (например, модель гауссовой смеси) - вероятностные модели, моделирующие генеративную функцию плотности вероятности данных, например, с использованием смеси гауссовых распределений. Учитывая набор нормальных выборок данных, цель состоит в том, чтобы найти параметры распределения вероятности так, чтобы он лучше описывал выборки. Затем используйте вероятность новой выборки, чтобы решить, принадлежит ли она к распределению или является выбросом. ScikitLearn реализует модели гауссовых смесей и использует алгоритм максимизации ожиданий для их изучения.
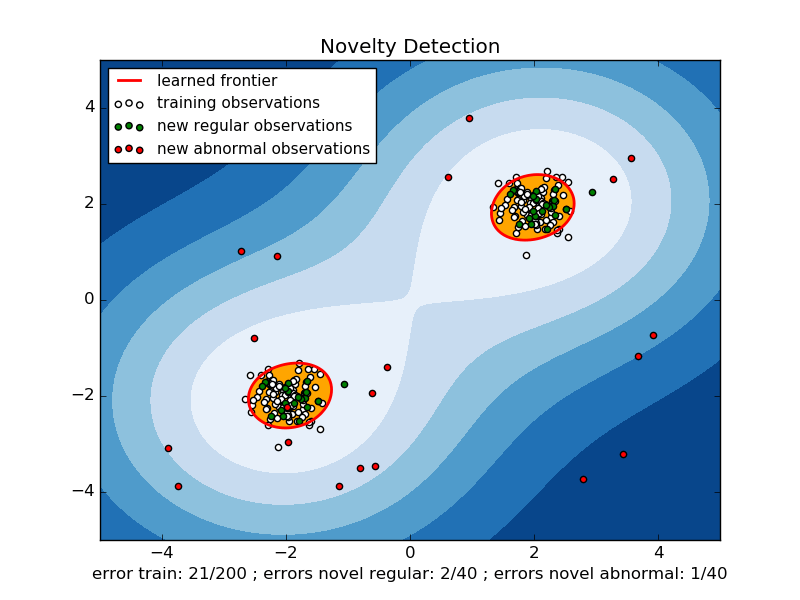
- Одноклассная машина опорных векторов (SVM) - расширение стандартного классификатора SVM, которое пытается найти границу, которая отделяет нормальные выборки от неизвестных новых выборок (в классическом подходе граница определяется путем максимизации разницы между нормальными выборки и происхождение пространства, проецируемого на так называемое "пространство признаков"). ScikitLearn имеет реализацию одноклассного SVM, которая позволяет легко его использовать, и хороший пример. Я прилагаю график этого примера, чтобы проиллюстрировать границы одноклассного SVM-поиска "вокруг" нормальных образцов данных: