Как отследить путь в поиске по ширине?
Как вы проследите путь поиска в ширину, например, в следующем примере:
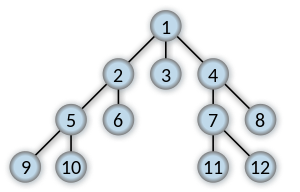
Если в поисках ключа 11, верните кратчайший список, соединяющий от 1 до 11.
[1, 4, 7, 11]
7 ответов
Вы должны были посмотреть на http://en.wikipedia.org/wiki/Breadth-first_search первую очередь.
Ниже приведена краткая реализация, в которой я использовал список списка для представления очереди путей.
# graph is in adjacent list representation
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
queue.append([start])
while queue:
# get the first path from the queue
path = queue.pop(0)
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
# enumerate all adjacent nodes, construct a new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
queue.append(new_path)
print bfs(graph, '1', '11')
Другой подход заключается в поддержании сопоставления от каждого узла к его родителю, и при проверке соседнего узла запишите его родителя. Когда поиск будет завершен, просто вернитесь назад в соответствии с родительским отображением.
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def backtrace(parent, start, end):
path = [end]
while path[-1] != start:
path.append(parent[path[-1]])
path.reverse()
return path
def bfs(graph, start, end):
parent = {}
queue = []
queue.append(start)
while queue:
node = queue.pop(0)
if node == end:
return backtrace(parent, start, end)
for adjacent in graph.get(node, []):
if node not in queue :
parent[adjacent] = node # <<<<< record its parent
queue.append(adjacent)
print bfs(graph, '1', '11')
Приведенные выше коды основаны на предположении, что циклов нет.
Очень простой код. Вы продолжаете добавлять путь каждый раз, когда обнаруживаете узел.
graph = {
'A': set(['B', 'C']),
'B': set(['A', 'D', 'E']),
'C': set(['A', 'F']),
'D': set(['B']),
'E': set(['B', 'F']),
'F': set(['C', 'E'])
}
def retunShortestPath(graph, start, end):
queue = [(start,[start])]
visited = set()
while queue:
vertex, path = queue.pop(0)
visited.add(vertex)
for node in graph[vertex]:
if node == end:
return path + [end]
else:
if node not in visited:
visited.add(node)
queue.append((node, path + [node]))
Мне очень понравился первый ответ Цяо! Единственное, чего здесь не хватает, это пометить вершины как посещенные.
Почему мы должны это сделать?
Давайте представим, что есть еще один узел № 13, связанный с узлом 11. Теперь наша цель - найти узел 13.
После небольшой пробежки очередь будет выглядеть так:
[[1, 2, 6], [1, 3, 10], [1, 4, 7], [1, 4, 8], [1, 2, 5, 9], [1, 2, 5, 10]]
Обратите внимание, что есть ДВЕ пути с узлом № 10 в конце.
Это означает, что пути от узла № 10 будут проверены дважды. В этом случае это не выглядит так плохо, потому что у узла № 10 нет дочерних элементов... Но это может быть очень плохо (даже здесь мы проверим этот узел дважды без причины...)
Узел № 13 не находится в этих путях, поэтому программа не вернется, пока не достигнет второго пути с узлом № 10 в конце... И мы еще раз проверим его.
Все, что нам не хватает, - это набор для отметки посещенных узлов, а не для их повторной проверки.
Это код Цяо после модификации:
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
Выход программы будет:
[1, 4, 7, 11, 13]
Без ненужных перепроверок..
Я думал, что попробую написать код для удовольствия:
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, forefront, end):
# assumes no cycles
next_forefront = [(node, path + ',' + node) for i, path in forefront if i in graph for node in graph[i]]
for node,path in next_forefront:
if node==end:
return path
else:
return bfs(graph,next_forefront,end)
print bfs(graph,[('1','1')],'11')
# >>>
# 1, 4, 7, 11
Если вы хотите циклы, вы можете добавить это:
for i, j in for_front: # allow cycles, add this code
if i in graph:
del graph[i]
С циклами, включенными в график, разве что-то подобное не работает лучше?
from collections import deque
graph = {
1: [2, 3, 4],
2: [5, 6, 3],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs1(graph_to_search, start, end):
queue = deque([start])
visited = {start}
trace = {}
while queue:
# Gets the first path in the queue
vertex = queue.popleft()
# Checks if we got to the end
if vertex == end:
break
for neighbour in graph_to_search.get(vertex, []):
# We check if the current neighbour is already in the visited nodes set in order not to re-add it
if neighbour not in visited:
# Mark the vertex as visited
visited.add(neighbour)
trace[neighbour] = vertex
queue.append(neighbour)
path = [end]
while path[-1] != start:
last_node = path[-1]
next_node = trace[last_node]
path.append(next_node)
return path[::-1]
print(bfs1(graph,1, 13))
Таким образом будут посещаться только новые узлы и, кроме того, не будет циклов.
Мне нравится как @Qiao первый ответ, так и дополнение @Or. Ради немного меньшей обработки я хотел бы добавить к ответу Ор.
В ответе @Or отслеживание посещенного узла великолепно. Мы также можем позволить программе завершиться раньше, чем она есть в настоящее время. В какой-то момент цикла for current_neighbour должен быть endи как только это произойдет, будет найден кратчайший путь, и программа сможет вернуться.
Я бы изменил метод следующим образом, уделив пристальное внимание циклу for.
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
#No need to visit other neighbour. Return at once
if current_neighbour == end
return new_path;
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
Выход и все остальное будет таким же. Однако на обработку кода уйдет меньше времени. Это особенно полезно на больших графиках. Я надеюсь, что это поможет кому-то в будущем.
Версия Javascript и поиск первых/всех путей...
PS, график с циклами работает хорошо.
Ваша банка
convertэто к
python, это просто
function search_path(graph, start, end, exhausted=true, method='bfs') {
// note. Javascript Set is ordered set...
const queue = [[start, new Set([start])]]
const visited = new Set()
const allpaths = []
const hashPath = (path) => [...path].join(',') // any path hashing method
while (queue.length) {
const [node, path] = queue.shift()
// visited node and its path instant. do not modify it others place
visited.add(node)
visited.add(hashPath(path))
for (let _node of graph.get(node) || []) {
// the paths already has the node, loops mean nothing though.
if (path.has(_node))
continue;
// now new path has no repeated nodes.
let newpath = new Set([...path, _node])
if (_node == end){
allpaths.push(newpath)
if(!exhausted) return allpaths; // found and return
}
else {
if (!visited.has(_node) || // new node till now
// note: search all possible including the longest path
visited.has(_node) && !visited.has(hashPath(newpath))
) {
if(method == 'bfs')
queue.push([_node, newpath])
else{
queue.unshift([_node, newpath])
}
}
}
}
}
return allpaths
}
вывод такой..
[
[ 'A', 'C' ],
[ 'A', 'E', 'C'],
[ 'A', 'E', 'F', 'C' ] // including F in `A -> C`
]