Форматировать номер в метке легенды в seaborn/ геопандас
Я искал везде, и кажется, что большинство методов с легендой в matplotlib о строковых метках. Тем не менее, я очень часто сталкиваюсь с легендами числовых меток и не нашел способа отформатировать числа в них.
В первом случае я использовал .plot() Функция и установить легенду с помощью ключевого слова:
fig, ax = plt.subplots(figsize=(10, 15))
legend_kwds = {'loc': 3, 'fontsize': 15}
style_kwds = {'edgecolor': 'white', 'linewidth': 2}
gdf.plot(column='pop2010', cmap='Blues', scheme='QUANTILES', k=4, legend=True, legend_kwds=legend_kwds, edgecolor='k', ax=ax)
и получил следующий участок: карта. Как видите, слишком много знаков после запятой, и я хочу, чтобы метка легенды была целым числом.
Во втором случае я поставил свою легенду ax.legend():
ax.legend(title='Clock Hours in 24 Hours', loc=2, ncol=2, fontsize=13)
и получил эту легенду, но я также хочу, чтобы она была целым числом.
Интересно, есть ли способ отформатировать числа в легенде в matplotlib для обоих случаев. Есть ли какая-то логика, которая может помочь мне понять это?
0 ответов
Поскольку я недавно столкнулся с той же проблемой, и решение, по-видимому, не доступно на stackru или других сайтах, я подумал, что опубликую подход, который я выбрал, в случае его полезности.
Во-первых, основной сюжет с использованием geopandas карта мира:
# load world data set
world_orig = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
world = world_orig[(world_orig['pop_est'] > 0) & (world_orig['name'] != "Antarctica")].copy()
world['gdp_per_cap'] = world['gdp_md_est'] / world['pop_est']
# basic plot
fig = world.plot(column='pop_est', figsize=(12,8), scheme='fisher_jenks',
cmap='YlGnBu', legend=True)
leg = fig.get_legend()
leg._loc = 3
plt.show()
Метод, который я использовал, опирался на get_texts() метод для matplotlib.legend.Legend объект, затем перебирая элементы в leg.get_texts() разделить текстовый элемент на нижнюю и верхнюю границы, а затем создать новую строку с примененным форматированием и установить ее с помощью set_text() метод.
# formatted legend
fig = world.plot(column='pop_est', figsize=(12,8), scheme='fisher_jenks',
cmap='YlGnBu', legend=True)
leg = fig.get_legend()
leg._loc = 3
for lbl in leg.get_texts():
label_text = lbl.get_text()
lower = label_text.split()[0]
upper = label_text.split()[2]
new_text = f'{float(lower):,.0f} - {float(upper):,.0f}'
lbl.set_text(new_text)
plt.show()
Это очень подход "проб и ошибок", поэтому я не удивлюсь, если бы был лучший способ. Тем не менее, возможно, это будет полезно.
Способ 1:
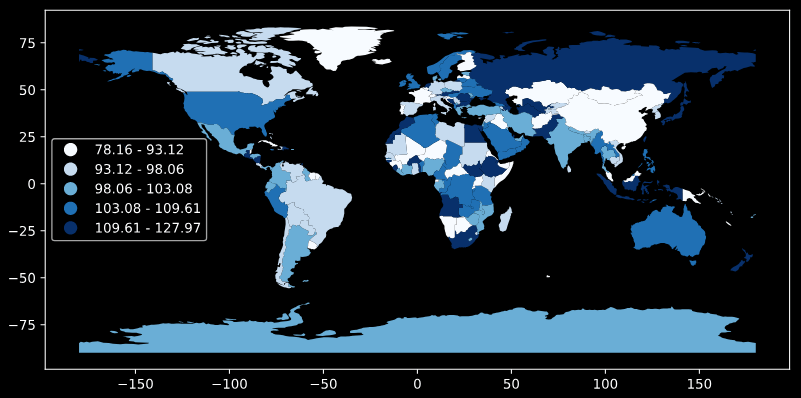
GeoPandas использует классификатор PySal. Вот пример карты квантилей (k=5).
import matplotlib.pyplot as plt
import numpy as np
import pysal.viz.mapclassify as mc
import geopandas as gpd
# load dataset
path = gpd.datasets.get_path('naturalearth_lowres')
gdf = gpd.read_file(path)
# generate a random column
gdf['random_col'] = np.random.normal(100, 10, len(gdf))
# plot quantiles map
fig, ax = plt.subplots(figsize=(10, 10))
gdf.plot(column='random_col', scheme='quantiles', k=5, cmap='Blues',
legend=True, legend_kwds=dict(loc=6), ax=ax)
Это дает нам:
Предположим, что мы хотим округлить числа в легенде. Мы можем получить классификацию через .Quantiles() функция в pysal.viz.mapclassify,
mc.Quantiles(gdf.random_col, k=5)
Функция возвращает объект classifiers.Quantiles:
Quantiles
Lower Upper Count
==========================================
x[i] <= 93.122 36
93.122 < x[i] <= 98.055 35
98.055 < x[i] <= 103.076 35
103.076 < x[i] <= 109.610 35
109.610 < x[i] <= 127.971 36
Объект имеет атрибут bins, который возвращает массив, содержащий верхние границы во всех классах.
array([ 93.12248452, 98.05536454, 103.07553581, 109.60974753,
127.97082465])
Таким образом, мы можем использовать эту функцию, чтобы получить все границы классов, поскольку верхняя граница в более низком классе равна нижней границе в более высоком классе. Отсутствует только одна нижняя граница в низшем классе, которая равна минимальному значению столбца, который вы пытаетесь классифицировать в вашем DataFrame.
Вот пример округления всех чисел до целых:
# get all upper bounds
upper_bounds = mc.Quantiles(gdf.random_col, k=5).bins
# get and format all bounds
bounds = []
for index, upper_bound in enumerate(upper_bounds):
if index == 0:
lower_bound = gdf.random_col.min()
else:
lower_bound = upper_bounds[index-1]
# format the numerical legend here
bound = f'{lower_bound:.0f} - {upper_bound:.0f}'
bounds.append(bound)
# get all the legend labels
legend_labels = ax.get_legend().get_texts()
# replace the legend labels
for bound, legend_label in zip(bounds, legend_labels):
legend_label.set_text(bound)
В итоге мы получим:
Способ 2:
В дополнение к GeoPandas' .plot() метод, вы также можете рассмотреть .choropleth() функция, предлагаемая геоплотом, в которой вы можете легко использовать различные типы схем и количество классов при прохождении legend_labels Арг, чтобы изменить метки легенды. Например,
import geopandas as gpd
import geoplot as gplt
path = gpd.datasets.get_path('naturalearth_lowres')
gdf = gpd.read_file(path)
legend_labels = ['< 2.4', '2.4 - 6', '6 - 15', '15 - 38', '38 - 140 M']
gplt.choropleth(gdf, hue='pop_est', cmap='Blues', scheme='quantiles',
legend=True, legend_labels=legend_labels)
что дает вам