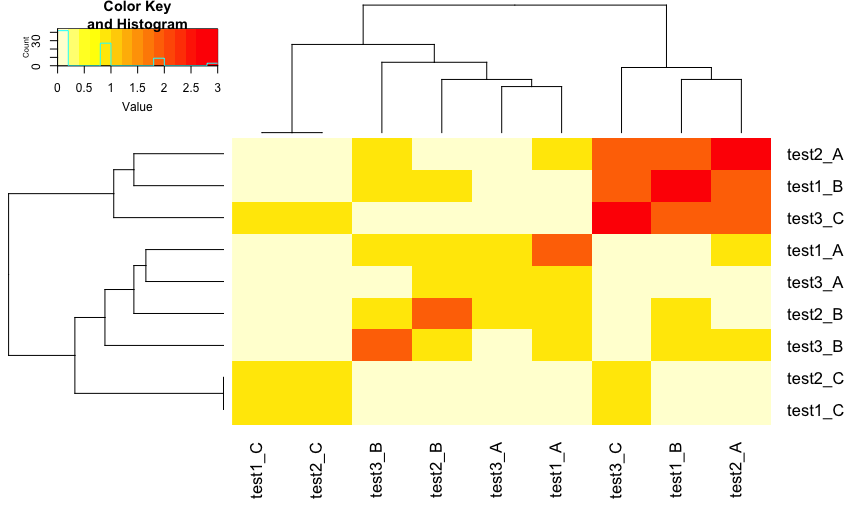
Тепловая карта категорийных переменных
У меня есть фрейм данных элементов, и у каждого есть несколько столбцов классификатора, которые являются категориальными переменными.
ID test1 test2 test3
1 A B A
2 B A C
3 C C C
4 A A B
5 B B B
6 B A C
Я хочу сгенерировать тепловую карту для каждой комбинации тестовых столбцов (test1 v test2, test1 v test3 и т. Д.), Используя ggplot2. Тепловая карта будет иметь все факторы в столбце этого теста (в данном случае A,B,C) на стороне x и все факторы другого теста на y-стороне, а поля в тепловой карте должны быть окрашены на основе количество идентификаторов, которые имеют эту комбинацию классификатора.
Например, в приведенном выше вводе, если у нас есть тепловая карта между test1 и test2, то прямоугольник, который находится на пересечении B для test1 и A для test2, будет самым ярким, так как есть 2 идентификатора с этой комбинацией. Я надеюсь использовать эти тепловые карты для анализа того, какие тесты являются наиболее подходящими для набора данных, но не могу использовать корреляцию Пирсона R, поскольку они являются категориальными переменными.
Я знаком с ggplot, поэтому я предпочитаю этот пакет, но если он проще в pheatplot, я в порядке с этим.
2 ответа
Потребовалось время, чтобы понять, как это сделать, и все же я не уверен, что это лучший способ.
Данные:dat = structure(list(ID = 1:6,
test1 = c("A", "B", "C", "A", "B", "B"),
test2 = c("B", "A", "C", "A", "B", "A"),
test3 = c("A", "C", "C", "B", "B", "C")
),
.Names = c("ID", "test1", "test2", "test3"),
class = "data.frame", row.names = c(NA, -6L)
)
library(tidyverse)
library(ggthemes)
library(gridExtra)
fcombs <- expand.grid(LETTERS[1:3], LETTERS[1:3], stringsAsFactors = F)
tcombs <- as.data.frame(combn(colnames(dat[,-1]), 2), stringsAsFactors = F)
lapply через комбинации тестов, full_joinсчитать длину каждой группы, исключая NAsdtl <- lapply(tcombs, function(i){
select(dat, ID, i) %>%
full_join(x = fcombs, by = c("Var1" = i[1], Var2 = i[2])) %>%
group_by(Var1, Var2) %>%
mutate(N = sum(!is.na(ID)), ID = NULL) %>%
ungroup()
}
)
pl <- lapply(seq_along(tcombs), function(i){
gtitle = paste(tcombs[[i]], collapse = " ~ ")
dtl[[i]] %>%
ggplot(aes(x = Var1, y = Var2, fill = N)) +
geom_tile() +
theme_tufte() +
theme(axis.title = element_blank()) +
ggtitle(gtitle)
}
)
tableGrob объекты)tbl <- lapply(tcombs, function(i) tableGrob(select(dat, ID, i),
theme = ttheme_minimal()))
resl <- c(pl, tbl)[c(1, 4, 2, 5, 3, 6)]
grid.arrange(grobs = resl, ncol = 2, nrow = 3)

Ваш вопрос немного неясен, но я думаю, что вы ищете что-то подобное. Я не ggplot2 человек, поэтому я позволю кому-то еще предоставить этот код.
x <- read.table(text="ID test1 test2 test3
1 A B A
2 B A C
3 C C C
4 A A B
5 B B B
6 B A C", stringsAsFactors=FALSE, header=T)
xl <- reshape2::melt(data = x, id.vars="ID", variable.name = "Test", value.name="Grade")
xl$Test_Gr <- apply(xl[,2:3], 1, paste0, collapse="_")
xw <- reshape2::dcast(xl, ID ~ Test_Gr, fun.aggregate = length)
xwm <- as.matrix(xw[,-1])
xc <- t(xwm) %*% xwm
colnames(xc) <- colnames(xw)[-1]
rownames(wc) <- colnames(xw)[-1]
gplots::heatmap.2(xc, trace="none", col = rev(heat.colors(15)))