R - анализ данных и масштабируемый код
Хай, в последние дни у меня была маленькая / большая проблема.
У меня есть набор данных транзакции с 1 миллионом строк и двумя столбцами (идентификатор клиента и идентификатор продукта), и я хочу преобразовать это в двоичную матрицу. Я использовал функцию изменения формы и распространения, но в обоих случаях я использовал оперативную память 64 Мб, а Rstudio / R отключился. Поскольку я использую только один процессор, этот процесс занимает много времени. Мой вопрос: что нового в этом переходе между малыми и большими данными? Кто я могу использовать больше процессора?
Я ищу, и я нашел пару решений, но мне нужно мнение эксперта
1 - Используете Spark R?
2 - решение H20.ai? http://h2o.ai/product/enterprise-support/
3 - Революционная аналитика? http://www.revolutionanalytics.com/big-data
4 - перейти в облако? как Microsoft Azure?
Если мне нужно, я могу использовать виртуальную машину с большим количеством ядер... но мне нужно знать, как можно совершить эту транзакцию
Моя конкретная проблема
У меня есть этот data.frame (но с 1 миллионом строк)
Sell<-data.frame(UserId = c(1,1,1,2,2,3,4), Code = c(111,12,333,12,111,2,3))
и я сделал:
Sell[,3] <-1
test<-spread(Sell, Code, V3)
это работает с небольшим набором данных... но с 1 миллионом строк это занимает много времени (12 часов) и снижается, потому что мой максимальный объем памяти составляет 64 МБ. Какие-либо предложения?
2 ответа
Я не уверен, что это вопрос кодирования... НО...
Новый предварительный просмотр сообщества SQL Server 2016 имеет встроенный R на сервере, и вы можете скачать предварительный просмотр, чтобы попробовать здесь: https://www.microsoft.com/en-us/evalcenter/evaluate-sql-server-2016
Это приведет к тому, что ваш код R попадет в ваши данные и будет работать поверх движка SQL, обеспечивая такую же масштабируемость, которую вы встроили в SQL.
Или вы можете установить виртуальную машину в Azure, перейдя на новый портал, выбрав "Новый", "Виртуальная машина" и выполнив поиск "SQL". 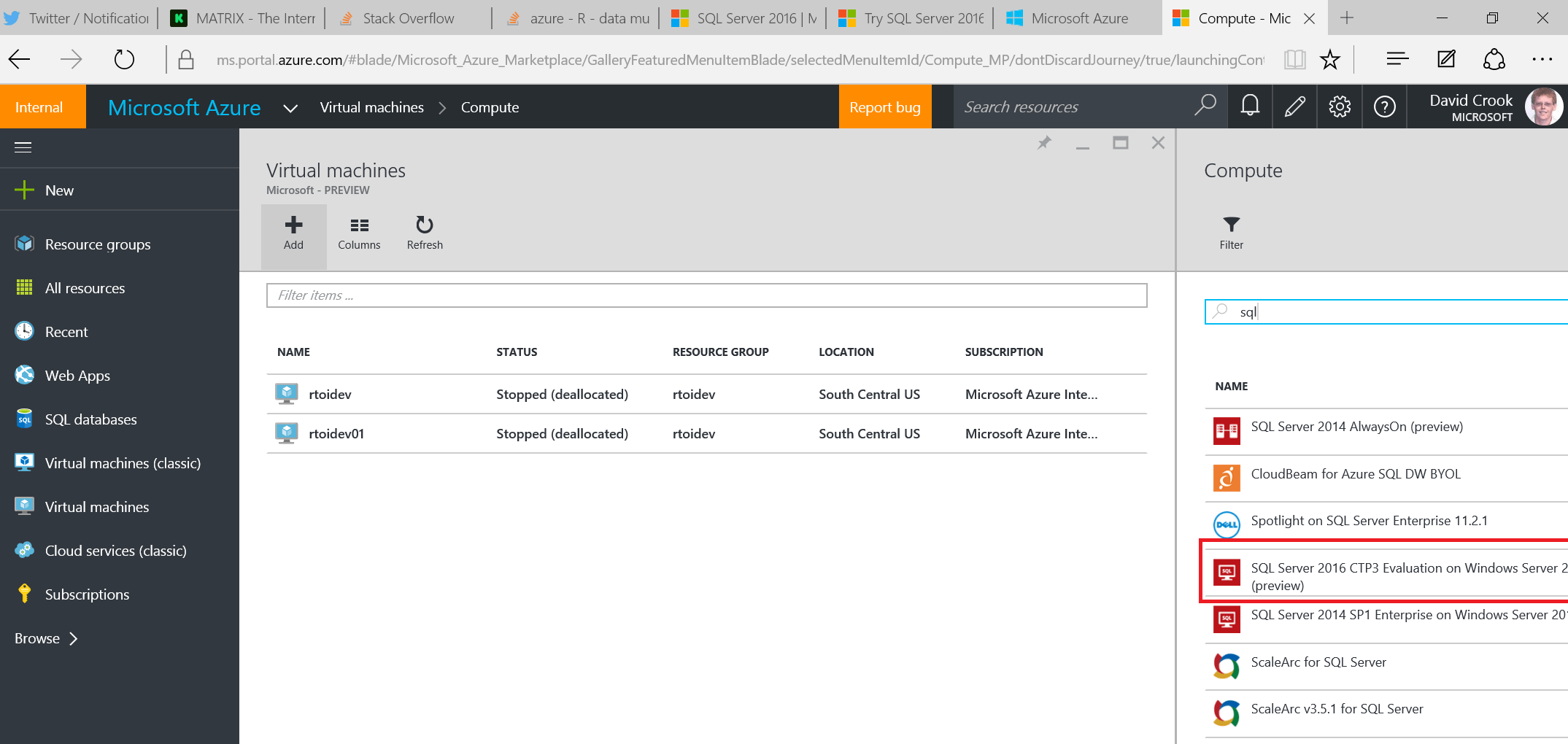
Вы не говорите, что хотите сделать с результатом, но самый эффективный способ создать такую матрицу - это создать разреженную матрицу.
Это плотный матричный объект, который тратит много оперативной памяти на все эти NA ценности.
test
# UserId 2 3 12 111 333
#1 1 NA NA 1 1 1
#2 2 NA NA 1 1 NA
#3 3 1 NA NA NA NA
#4 4 NA 1 NA NA NA
Этого можно избежать с помощью разреженной матрицы, которая внутри по-прежнему является структурой длинного формата, но имеет методы для операций с матрицами.
library(Matrix)
Sell[] <- lapply(Sell, factor)
test1 <- sparseMatrix(i = as.integer(Sell$UserId),
j = as.integer(Sell$Code),
x = rep(1, nrow(Sell)),
dimnames = list(levels(Sell$UserId),
levels(Sell$Code)))
#4 x 5 sparse Matrix of class "dgCMatrix"
# 2 3 12 111 333
#1 . . 1 1 1
#2 . . 1 1 .
#3 1 . . . .
#4 . 1 . . .
Вам понадобится еще меньше оперативной памяти с логически разреженной матрицей:
test2 <- sparseMatrix(i = as.integer(Sell$UserId),
j = as.integer(Sell$Code),
x = rep(TRUE, nrow(Sell)),
dimnames = list(levels(Sell$UserId),
levels(Sell$Code)))
#4 x 5 sparse Matrix of class "lgCMatrix"
# 2 3 12 111 333
#1 . . | | |
#2 . . | | .
#3 | . . . .
#4 . | . . .