Как обрабатывать данные с помощью мультииндексов с помощью панд
У меня есть серия, как это.
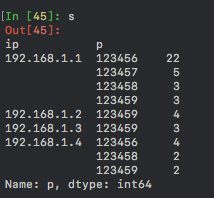
Я хочу обработать эту серию, чтобы получить максимум p за каждый ip.
Результат:
ip
192.168.1.1 22
192.168.1.2 4
192.168.1.3 3
192.168.1.4 4
Есть ли способ сделать это легко?
2 ответа
Решение
Если ip находится в индексе (в первой позиции), вы должны использовать этот синтаксис.
s.groupby(level=0).max()
# ip
# 192.168.1.1 22
# 192.168.1.2 4
# 192.168.1.3 3
# 192.168.1.4 4
# Name: p, dtype: int64
То, что вы ищете, это групповое предложение панд: s.groupby(level=0).max()
Пример:
iterables = [['192.168.1.1', '192.168.1.2', '192.168.1.3', '192.168.1.4'],
['123455', '123456', '123457']]
index = pd.MultiIndex.from_product(iterables, names=['ip', 'p'])
s = pd.Series(np.random.randint(30, size=12), index=index)
s
Выход:
ip p
192.168.1.1 123455 18
123456 20
123457 12
192.168.1.2 123455 25
123456 1
123457 4
192.168.1.3 123455 28
123456 19
123457 22
192.168.1.4 123455 20
123456 10
123457 12
И чтобы получить максимум для каждого IP:
s.groupby(level=0).max()
Выход:
ip
192.168.1.1 20
192.168.1.2 25
192.168.1.3 28
192.168.1.4 20
Изменить: изменено с s.groupby['ip'].max() в s.groupby(level=0).max() так как некоторые тесты, которые я сделал, не работали