Seaborn: создание гистограммы по группам с помощью асимметричных пользовательских погрешностей
У меня есть Pandas dataframe, в котором есть пара групповых столбцов, как показано ниже.
gr1 grp2 variables lb m ub
A A1 V1 1.00 1.50 2.5
A A2 V2 1.50 2.50 3.5
B A1 V1 3.50 14.50 30.5
B A2 V2 0.25 0.75 1.0
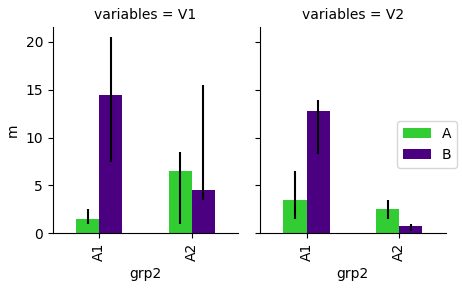
Я пытаюсь получить отдельный вспомогательный график для каждой переменной в variables с помощью FacetGrid, Я пытаюсь построить окончательный сюжет, который мне нужен, который выглядит следующим образом.

Это то, что я до сих пор.
g = sns.FacetGrid(df, col="variables", hue="grp1")
g.map(sns.barplot, 'grp2', 'm', order=times)
Но, к сожалению, это складывает все мои точки данных.
Как я должен делать это с Seaborn?
ОБНОВЛЕНИЕ: следующий код в основном делает то, что я после, но в настоящее время не отображается yerr,
g = sns.factorplot(x="Grp2", y="m", hue="Grp1", col="variables", data=df, kind="bar", size=4, aspect=.7, sharey=False)
Как я могу включить lb а также ub как погрешность на факторплоте?
1 ответ
Прежде чем мы начнем, позвольте мне упомянуть, что matplotlib требует, чтобы ошибки относились к данным, а не к абсолютным границам. Следовательно, мы изменили бы фрейм данных, чтобы учесть это, вычитая соответствующие столбцы.
u = u"""grp1 grp2 variables lb m ub
A A1 V1 1.00 1.50 2.5
A A2 V2 1.50 2.50 3.5
B A1 V1 7.50 14.50 20.5
B A2 V2 0.25 0.75 1.0
A A2 V1 1.00 6.50 8.5
A A1 V2 1.50 3.50 6.5
B A2 V1 3.50 4.50 15.5
B A1 V2 8.25 12.75 13.9"""
import io
import pandas as pd
df = pd.read_csv(io.StringIO(u), delim_whitespace=True)
# errors must be relative to data (not absolute bounds)
df["lb"] = df["m"]-df["lb"]
df["ub"] = df["ub"]-df["m"]
Теперь есть два решения, которые по сути одинаковы. Давайте начнем с решения, которое не использует морского происхождения, а обертку для построения панд (причина станет ясна позже).
Не использую Seaborn
Pandas позволяет строить сгруппированные гистограммы, используя кадры данных, где каждый столбец принадлежит или составляет одну группу. Поэтому необходимо предпринять следующие шаги:
- создать количество участков в соответствии с количеством различных
variables, groupbyдата поvariables- для каждой группы создайте сводный фрейм данных со значениями
grp1как столбцы и томуmкак значения. Сделайте то же самое для двух столбцов ошибок. - Примените решение из раздела Как добавить асимметричные панели ошибок в сгруппированную диаграмму Pandas?
Код будет выглядеть так:
import io
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(io.StringIO(u), delim_whitespace=True)
# errors must be relative to data (not absolute bounds)
df["lb"] = df["m"]-df["lb"]
df["ub"] = df["ub"]-df["m"]
def func(x,y,h,lb,ub, **kwargs):
data = kwargs.pop("data")
# from https://stackru.com/a/37139647/4124317
errLo = data.pivot(index=x, columns=h, values=lb)
errHi = data.pivot(index=x, columns=h, values=ub)
err = []
for col in errLo:
err.append([errLo[col].values, errHi[col].values])
err = np.abs(err)
p = data.pivot(index=x, columns=h, values=y)
p.plot(kind='bar',yerr=err,ax=plt.gca(), **kwargs)
fig, axes = plt.subplots(ncols=len(df.variables.unique()))
for ax, (name, group) in zip(axes,df.groupby("variables")):
plt.sca(ax)
func("grp2", "m", "grp1", "lb", "ub", data=group, color=["limegreen", "indigo"])
plt.title(name)
plt.show()
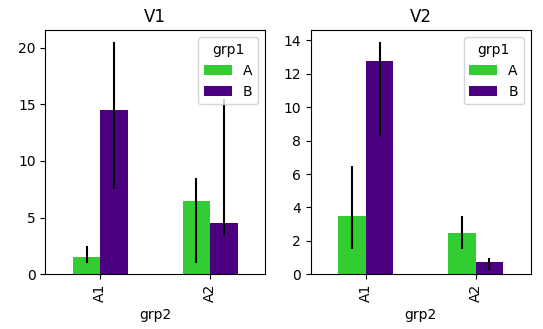
используя Seaborn
Seaborn factorplot не допускает пользовательских панелей ошибок. Поэтому необходимо использовать FaceGrid подход. Чтобы не складывать бруски, нужно поставить hue аргумент в map вызов. Таким образом, следующее является эквивалентом sns.factorplot Звони с вопроса.
g = sns.FacetGrid(data=df, col="variables", size=4, aspect=.7 )
g.map(sns.barplot, "grp2", "m", "grp1", order=["A1","A2"] )
Теперь проблема в том, что мы не можем получить панели ошибок в столбце извне или, что более важно, мы не можем дать ошибки для сгруппированной диаграммы в seaborn.barplot, Для несгруппированного барплота можно было бы сообщить об ошибке через yerr аргумент, который передается на matplotlib plt.bar сюжет. Эта концепция показана в этом вопросе. Тем не менее, так как seaborn.barplot звонки plt.bar несколько раз, один раз для каждого hueошибки в каждом вызове будут одинаковыми (иначе их размерность не будет совпадать).
Единственный вариант, который я вижу, это использовать FacetGrid и сопоставить с ней точно такую же функцию, которая использовалась выше. Это каким-то образом делает использование морского происхождения устаревшим, но для полноты здесь FacetGrid решение.
import io
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv(io.StringIO(u), delim_whitespace=True)
# errors must be relative to data (not absolute bounds)
df["lb"] = df["m"]-df["lb"]
df["ub"] = df["ub"]-df["m"]
def func(x,y,h,lb,ub, **kwargs):
data = kwargs.pop("data")
# from https://stackru.com/a/37139647/4124317
errLo = data.pivot(index=x, columns=h, values=lb)
errHi = data.pivot(index=x, columns=h, values=ub)
err = []
for col in errLo:
err.append([errLo[col].values, errHi[col].values])
err = np.abs(err)
p = data.pivot(index=x, columns=h, values=y)
p.plot(kind='bar',yerr=err,ax=plt.gca(), **kwargs)
g = sns.FacetGrid(df, col="variables", size=4, aspect=.7, )
g.map_dataframe(func, "grp2", "m", "grp1", "lb", "ub" , color=["limegreen", "indigo"])
g.add_legend()
plt.show()