Python PANDAS: пересчет многовариантных временных рядов с помощью группового
У меня есть данные в следующем общем формате, который я хотел бы изменить на 30-дневные окна временных рядов:
'customer_id','transaction_dt','product','price','units'
1,2004-01-02,thing1,25,47
1,2004-01-17,thing2,150,8
2,2004-01-29,thing2,150,25
3,2017-07-15,thing3,55,17
3,2016-05-12,thing3,55,47
4,2012-02-23,thing2,150,22
4,2009-10-10,thing1,25,12
4,2014-04-04,thing2,150,2
5,2008-07-09,thing2,150,43
Я хотел бы, чтобы 30-дневные окна начинались 2014-01-01 и заканчивались 12-31-2018. НЕ гарантируется, что у каждого клиента будут записи в каждом окне. Если у клиента есть несколько транзакций в окне, он берет средневзвешенную цену, суммирует единицы и объединяет названия продуктов, чтобы создать одну запись для каждого клиента на окно.
То, что я до сих пор, выглядит примерно так:
wa = lambda x:np.average(x, weights=df.loc[x.index, 'units'])
con = lambda x: '/'.join(x))
agg_funcs = {'customer_id':'first',
'product':'con',
'price':'wa',
'transaction_dt':'first',
'units':'sum'}
df_window = df.groupby(['customer_id', pd.Grouper(freq='30D')]).agg(agg_funcs)
df_window_final = df_window.unstack('customer_id', fill_value=0)
Если кто-нибудь знает некоторые лучшие способы решения этой проблемы (в частности, с помощью метода на месте и / или векторизации), я был бы признателен за это. В идеале, я также хотел бы добавить даты начала и окончания окна в виде столбцов к строкам.
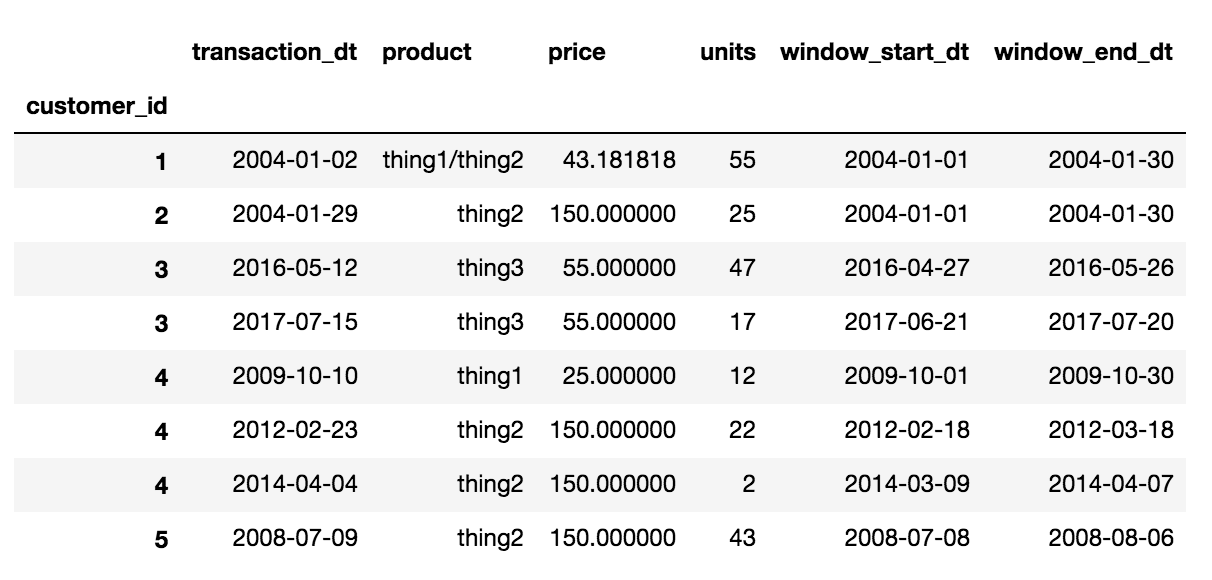
Окончательный результат будет выглядеть так в идеале:
'customer_id','transaction_dt','product','price','units','window_start_dt','window_end_dt'
1,2004-01-02,thing1/thing2,(weighted average price),(total units),(window_start_dt),(window_end_dt)
2,2004-01-29,thing2,(weighted average price),(total units),(window_start_dt),(window_end_dt)
3,2017-07-15,thing3,(weighted average price),(total units),(window_start_dt),(window_end_dt)
3,2016-05-12,thing3,(weighted average price),(total units),(window_start_dt),(window_end_dt)
4,2012-02-23,thing2,(weighted average price),(total units),(window_start_dt),(window_end_dt)
4,2009-10-10,thing1,(weighted average price),(total units),(window_start_dt),(window_end_dt)
4,2014-04-04,thing2,(weighted average price),(total units),(window_start_dt),(window_end_dt)
5,2008-07-09,thing2,(weighted average price),(total units),(window_start_dt),(window_end_dt)
1 ответ
Отредактировано для нового решения. Я думаю, что вы можете преобразовать каждый из transaction_dt к объекту Period 30 дней, а затем выполните группировку.
p = pd.period_range('2004-1-1', '12-31-2018',freq='30D')
def find_period(v):
p_idx = np.argmax(v < p.end_time)
return p[p_idx]
df['period'] = df['transaction_dt'].apply(find_period)
df
customer_id transaction_dt product price units period
0 1 2004-01-02 thing1 25 47 2004-01-01
1 1 2004-01-17 thing2 150 8 2004-01-01
2 2 2004-01-29 thing2 150 25 2004-01-01
3 3 2017-07-15 thing3 55 17 2017-06-21
4 3 2016-05-12 thing3 55 47 2016-04-27
5 4 2012-02-23 thing2 150 22 2012-02-18
6 4 2009-10-10 thing1 25 12 2009-10-01
7 4 2014-04-04 thing2 150 2 2014-03-09
8 5 2008-07-09 thing2 150 43 2008-07-08
Теперь мы можем использовать этот фрейм данных для получения конкатенации продуктов, средневзвешенной цены и суммы единиц. Затем мы используем некоторые из функций периода, чтобы получить время окончания.
def my_funcs(df):
data = {}
data['product'] = '/'.join(df['product'].tolist())
data['units'] = df.units.sum()
data['price'] = np.average(df['price'], weights=df['units'])
data['transaction_dt'] = df['transaction_dt'].iloc[0]
data['window_start_time'] = df['period'].iloc[0].start_time
data['window_end_time'] = df['period'].iloc[0].end_time
return pd.Series(data, index=['transaction_dt', 'product', 'price','units',
'window_start_time', 'window_end_time'])
df.groupby(['customer_id', 'period']).apply(my_funcs).reset_index('period', drop=True)