Группировка строк в GTSummary
Я пытаюсь сгруппировать некоторые строки/переменные (как категориальные, так и непрерывные), чтобы улучшить читаемость таблицы в большом наборе данных.
Вот фиктивный набор данных:
library(gtsummary)
library(tidyverse)
library(gt)
set.seed(11012021)
# Create Dataset
PIR <-
tibble(
siteidn = sample(c("1324", "1329", "1333", "1334"), 5000, replace = TRUE, prob = c(0.2, 0.45, 0.15, 0.2)) %>% factor(),
countryname = sample(c("NZ", "Australia"), 5000, replace = TRUE, prob = c(0.3, 0.7)) %>% factor(),
hospt = sample(c("Metropolitan", "Rural"), 5000, replace = TRUE, prob = c(0.65, 0.35)) %>% factor(),
age = rnorm(5000, mean = 60, sd = 20),
apache2 = rnorm(5000, mean = 18.5, sd=10),
apache3 = rnorm(5000, mean = 55, sd=20),
mechvent = sample(c("Yes", "No"), 5000, replace = TRUE, prob = c(0.4, 0.6)) %>% factor(),
sex = sample(c("Female", "Male"), 5000, replace = TRUE) %>% factor(),
patient = TRUE
) %>%
mutate(patient_id = row_number())%>%
group_by(
siteidn) %>% mutate(
count_site = row_number() == 1L) %>%
ungroup()%>%
group_by(
patient_id) %>% mutate(
count_pt = row_number() == 1L) %>%
ungroup()
Затем я использую следующий код для создания своей таблицы:
t1 <- PIR %>%
select(patientn = count_pt, siten = count_site, age, sex, apache2, apache3, apache2, mechvent, countryname) %>%
tbl_summary(
by = countryname,
missing = "no",
statistic = list(
patientn ~ "{n}",
siten ~ "{n}",
age ~ "{mean} ({sd})",
apache2 ~ "{mean} ({sd})",
mechvent ~ "{n} ({p}%)",
sex ~ "{n} ({p}%)",
apache3 ~ "{mean} ({sd})"),
label = list(
siten = "Number of ICUs",
patientn = "Number of Patients",
age = "Age",
apache2 = "APACHE II Score",
mechvent = "Mechanical Ventilation",
sex = "Sex",
apache3 = "APACHE III Score")) %>%
modify_header(stat_by = "**{level}**") %>%
add_overall(col_label = "**Overall**")
t2 <- PIR %>%
select(patientn = count_pt, siten = count_site, age, sex, apache2, apache3, apache2, mechvent, hospt) %>%
tbl_summary(
by = hospt,
missing = "no",
statistic = list(
patientn ~ "{n}",
siten ~ "{n}",
age ~ "{mean} ({sd})",
apache2 ~ "{mean} ({sd})",
mechvent ~ "{n} ({p}%)",
sex ~ "{n} ({p}%)",
apache3 ~ "{mean} ({sd})"),
label = list(
siten = "Number of ICUs",
patientn = "Number of Patients",
age = "Age",
apache2 = "APACHE II Score",
mechvent = "Mechanical Ventilation",
sex = "Sex",
apache3 = "APACHE III Score")) %>%
modify_header(stat_by = "**{level}**")
tbl <-
tbl_merge(
tbls = list(t1, t2),
tab_spanner = c("**Country**", "**Hospital Type**")
) %>%
modify_spanning_header(stat_0_1 ~ NA) %>%
modify_footnote(everything() ~ NA)
Получается следующая таблица:
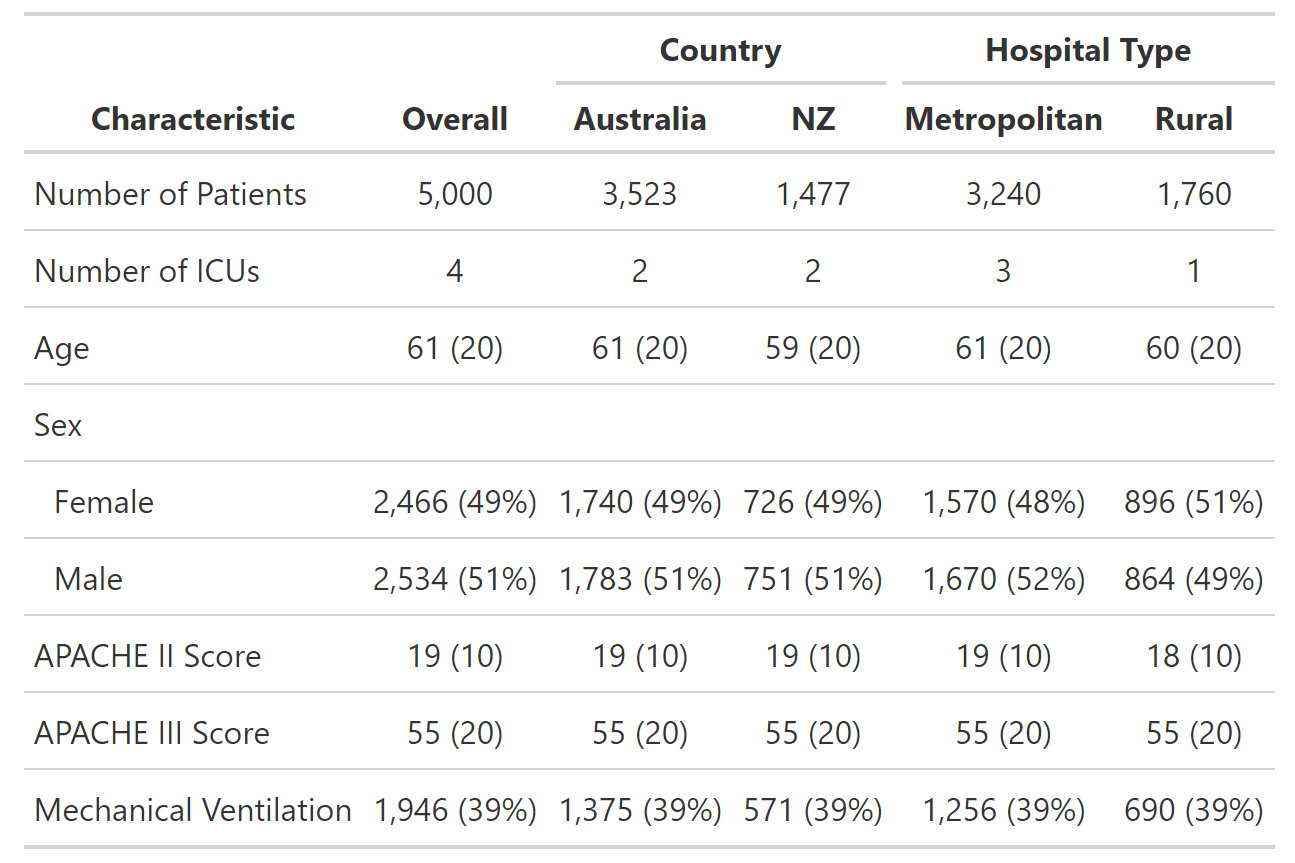
Я хотел бы сгруппировать определенные строки вместе для удобства чтения. В идеале я бы хотел, чтобы таблица выглядела так:
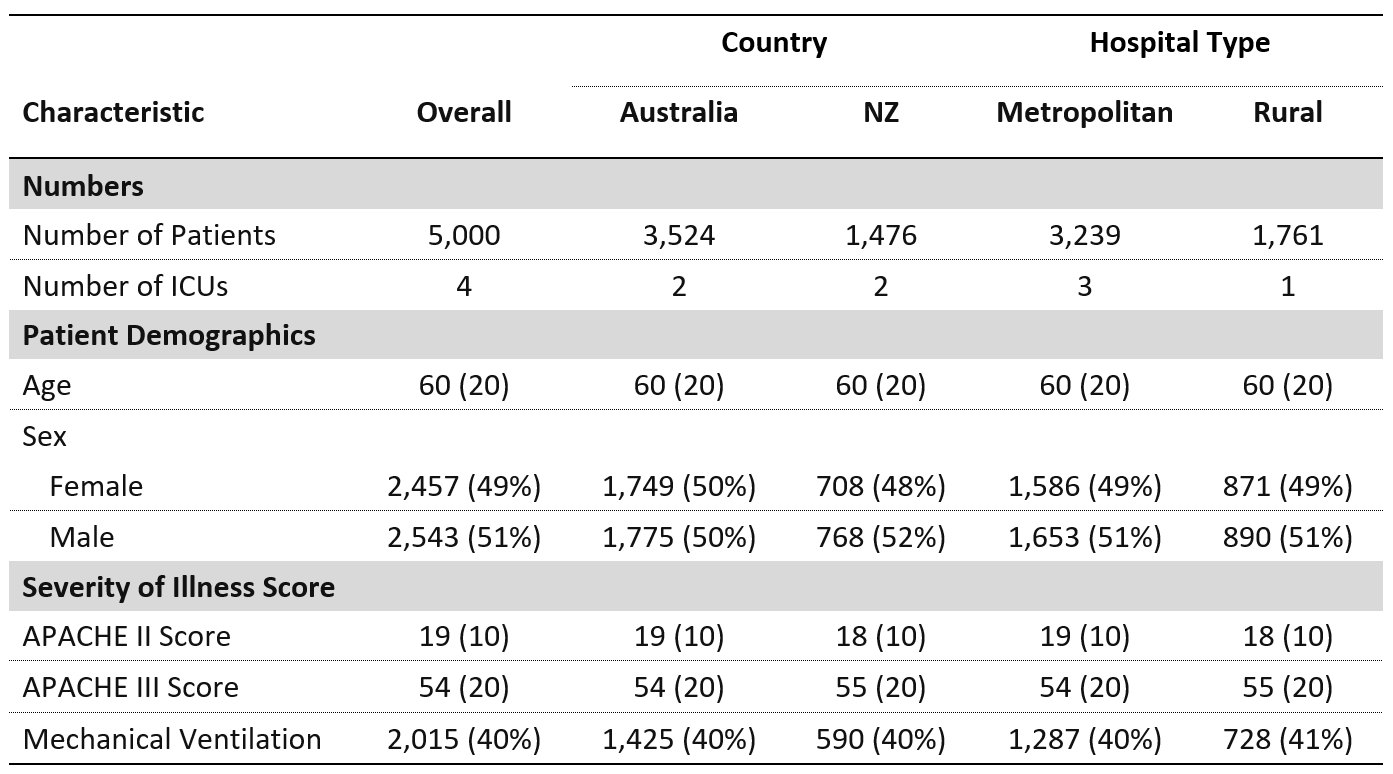
Я попытался использовать пакет gt со следующим кодом:
tbl <-
tbl_merge(
tbls = list(t1, t2),
tab_spanner = c("**Country**", "**Hospital Type**")
) %>%
modify_spanning_header(stat_0_1 ~ NA) %>%
modify_footnote(everything() ~ NA) %>%
as_gt() %>%
gt::tab_row_group(
group = "Severity of Illness Scores",
rows = 7:8) %>%
gt::tab_row_group(
group = "Patient Demographics",
rows = 3:6) %>%
gt::tab_row_group(
group = "Numbers",
rows = 1:2)
Получается нужная таблица:
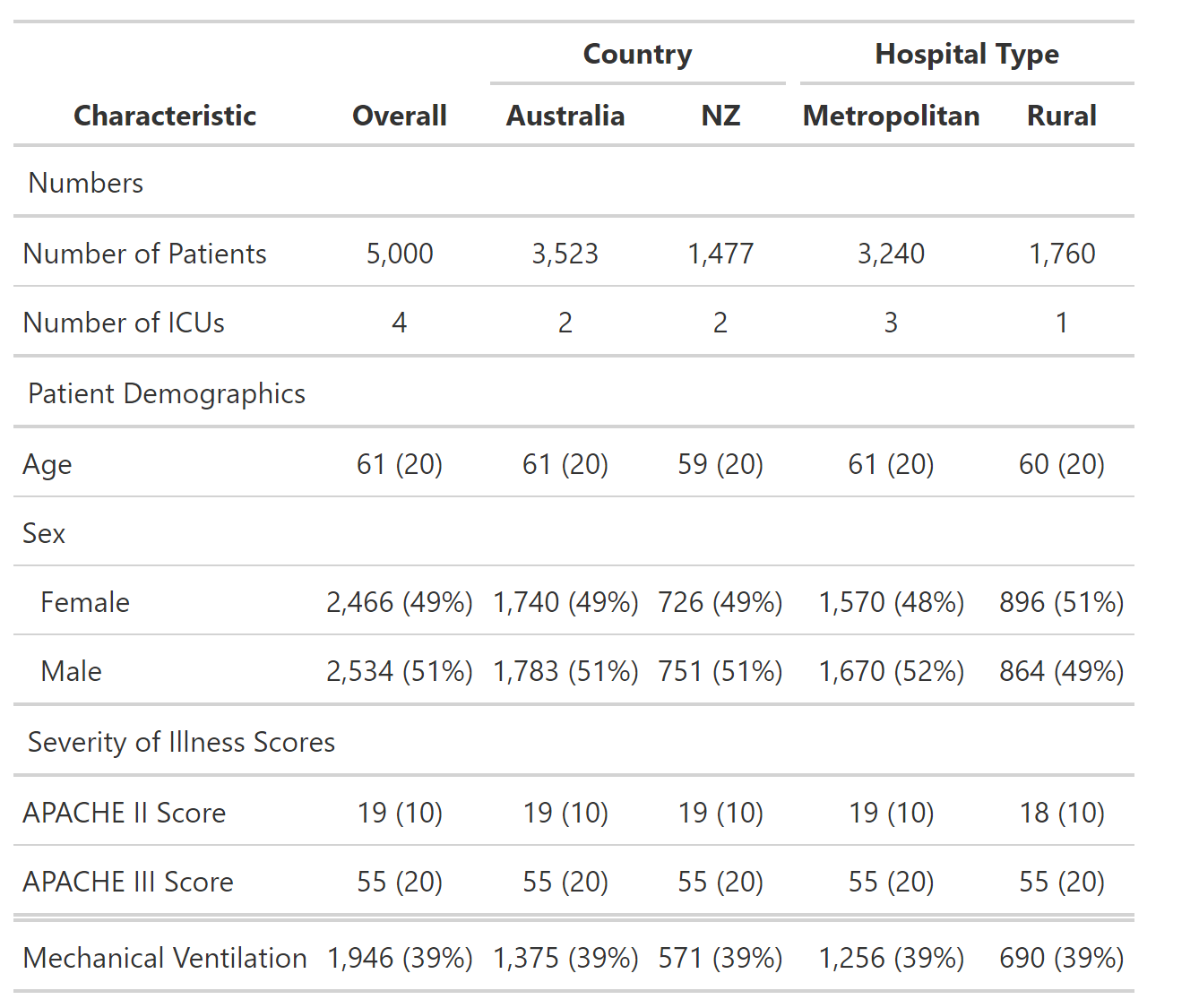
У меня есть пара проблем, связанных с тем, как я это делаю.
Когда я пытаюсь использовать имена строк (переменные), появляется сообщение об ошибке (Невозможно создать подмножество столбцов, которые не существуют...). Есть ли способ сделать это, используя имена переменных? С большими таблицами у меня возникают проблемы с использованием метода номеров строк для присвоения имен строк. Это особенно верно, когда есть одна переменная, которая теряет свое место при перемещении в конец для учета сгруппированных строк.
Есть ли способ сделать это до передачи в tbl_summary? Хотя мне нравится вывод этой таблицы, я использую Word в качестве выходного документа для статистических отчетов и хотел бы иметь возможность форматировать таблицы в Word, если это необходимо (или моими сотрудниками). Я обычно использую gtsummary::as_flextable для вывода таблицы.
Спасибо еще раз,
Бен
2 ответа
- Когда я пытаюсь использовать имена строк (переменные), появляется сообщение об ошибке (Невозможно создать подмножество столбцов, которые не существуют...). Есть ли способ сделать это, используя имена переменных? С большими таблицами у меня возникают проблемы с использованием метода номеров строк для присвоения имен строк. Это особенно верно, когда есть одна переменная, которая теряет свое место при перемещении в конец для учета сгруппированных строк.
Есть два способа сделать это: 1. построить отдельные таблицы для каждой группы, затем сложить их друг с другом и 2. добавить столбец группировки в
library(gtsummary)
library(dplyr)
packageVersion("gtsummary")
#> '1.3.6'
# Method 1 - Stack separate tables
t1 <- trial %>% select(age) %>% tbl_summary()
t2 <- trial %>% select(grade) %>% tbl_summary()
tbl1 <-
tbl_stack(
list(t1, t2),
group_header = c("Demographics", "Tumor Characteristics")
) %>%
modify_footnote(all_stat_cols() ~ NA)
# Method 2 - build a grouping variable
tbl2 <-
trial %>%
select(age, grade) %>%
tbl_summary() %>%
modify_table_body(
mutate,
group_variable = case_when(variable == "age" ~ "Deomgraphics",
variable == "grade" ~ "Tumor Characteristics")
) %>%
modify_table_body(group_by, group_variable)

2. Есть ли способ сделать это перед передачей в tbl_summary? Хотя мне нравится вывод этой таблицы, я использую Word в качестве выходного документа для статистических отчетов и хотел бы иметь возможность форматировать таблицы в Word, если это необходимо (или моими сотрудниками). Я обычно использую gtsummary::as_flextable для вывода таблицы.
Приведенные выше примеры изменяют таблицу перед экспортом в формат gt, поэтому вы можете экспортировать эти примеры в flextable. Однако flextable не имеет такой же встроенной функциональности строки заголовков (или, по крайней мере, я не знаю об этом и не использую ее в
Я думаю, что у меня может быть решение для этого (очевидно, спасибо и команде, предоставившей нам эту функцию)
Все, что вам нужно сделать, это отредактировать базовый фрейм данных, чтобы добавить переменную с желаемой строкой группировки, используяmodify_table_body, а затем поместите его в желаемое положение, например:
library(gtsummary)
library(dplyr)
packageVersion("gtsummary")
trial%>%
select(age, stage, grade)%>%
tbl_summary()%>%
modify_table_body(
~.x %>%
# add your variable
rbind(
tibble(
variable="Demographics",
var_type=NA,
var_label = "Demographics",
row_type="label",
label="Demographics",
stat_0= NA))%>% # expand the components of the tibble as needed if you have more columns
# can add another one
rbind(
tibble(
variable="Tumor characteristics",
var_type=NA,
var_label = "Tumor characteristics",
row_type="label",
label="Tumor characteristics",
stat_0= NA))%>%
# specify the position you want these in
arrange(factor(variable, levels=c("Demographics",
"age",
"Tumor characteristics",
"stage",
"grade"))))%>%
# and you can then indent the actual variables
modify_column_indent(columns=label, rows=variable%in%c("age",
"stage",
"grade"))%>%
# and double indent their levels
modify_column_indent(columns=label, rows= (variable%in%c("stage",
"grade")
& row_type=="level"),
double_indent=T)
