R gtsummary Row с итоговыми значениями категориальных переменных
У меня есть набор данных примерно 700000 пациентов, у которых есть идентификаторы больниц (факторная переменная). Я хотел бы создать строку, в которой видно количество больниц (это отдельно от количества пациентов). У меня есть 3 категориальные переменные в качестве столбцов в дополнение к общему столбцу.
На данный момент для каждого идентификатора больницы есть отдельная строка с количеством пациентов на каждом сайте для каждой категории.
Мой код выглядит следующим образом:
t1 <- PIR %>%
select(siteidn, countryname) %>%
tbl_summary(by = countryname ,missing = "no",
label = list(
siteidn = "Number of ICUs"),
statistic = list(
all_continuous() ~ "{mean} ({sd})",
all_categorical() ~ "{n} ({p}%)")) %>%
bold_labels() %>%
italicize_levels() %>%
add_overall()
t2 <- PIR %>%
select(siteidn, hospt) %>%
tbl_summary(by = hospt ,missing = "no",
label = list(
siteidn = "Number of ICUs"),
statistic = list(
all_continuous() ~ "{mean} ({sd})",
all_categorical() ~ "{n} ({p}%)")) %>%
bold_labels() %>%
italicize_levels()
t3 <- PIR %>%
select(siteidn, iculevelname) %>%
tbl_summary(by = iculevelname ,missing = "no",
label = list(
siteidn = "Number of ICUs"),
statistic = list(
all_continuous() ~ "{mean} ({sd})",
all_categorical() ~ "{n} ({p}%)")) %>%
bold_labels() %>%
italicize_levels()
tbl_merge(
tbls = list(t1, t2, t3),
tab_spanner = c("**Country**", "**Hospital Type**", "**ICU Level**"))
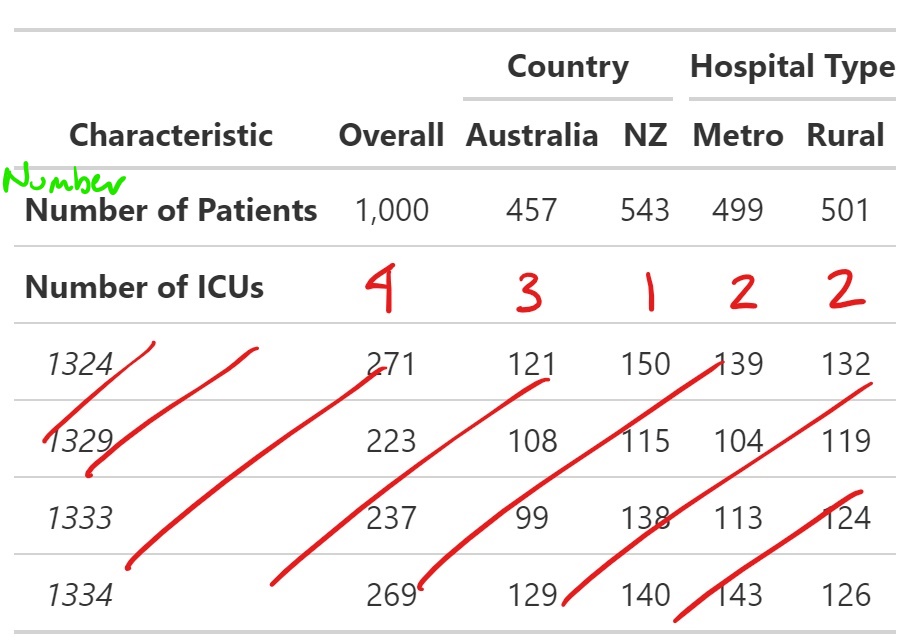
Получается следующая таблица:
Как видно, для каждого идентификатора больницы есть отдельная строка. Я хотел бы иметь одну строку, в которой есть общее количество больниц на каждом уровне (т.е. общее количество больниц в Австралии, Новой Зеландии, Метрополитен и т. д.).
Мои вопросы:
- Есть ли способ получить общую строку для факторной переменной, которая не является номером пациента?
- Можно ли вставить общий столбец после объединения таблиц (чтобы общий столбец не попадал под заголовок «Страна»)?
- Есть ли способ создать строку для количества пациентов и не указывать эти данные в заголовках?
Спасибо всем за ваше время.
Бен
ДОБАВИТЬ: Вот изображение того, как я хотел бы, чтобы таблица выглядела. Прошу прощения за грубость. Я хотел бы иметь только одну строку для факторной переменной общего количества отделений интенсивной терапии, а не иметь строку каждого отделения интенсивной терапии с количеством пациентов в ней (красные чернила).
Кроме того, есть ли способ сгруппировать 2 строки под общим заголовком, аналогичным факторным переменным (зеленые чернила).
Я понимаю, что мои навыки R находятся в зачаточном состоянии. Всем спасибо за терпение!
Бен
1 ответ
Я согласен с Беном, всегда полезно включать набор данных, который мы можем запустить на нашей машине, и пример того, как вы хотите, чтобы результат выглядел. Ниже приведен пример кода, который отвечает на большинство ваших вопросов.
- Есть ли способ получить общую строку для факторной переменной, которая не является номером пациента?
Я не уверен, что вы ищете здесь. Пожалуйста, подробнее.
- Можно ли вставить общий столбец после объединения таблиц (чтобы общий столбец не попадал под заголовок «Страна»)?
Да, вы можете использовать
- Есть ли способ создать строку для количества пациентов и не указывать эти данные в заголовках?
Да, если вы создадите новый столбец в своем наборе данных, который будет ИСТИННЫМ для всех наблюдений, мы можем обобщить этот столбец и сообщить N.
Кроме того, если вы делаете перекрестные таблицы только для одной переменной, вам следует изучить
library(gtsummary)
library(tidyverse)
set.seed(20210108)
# create dummy dataset
PIR <-
tibble(
siteidn = sample(c("1325", "1324", "1329"), 100, replace = TRUE) %>% factor(),
countryname = sample(c("NZ", "Australia"), 100, replace = TRUE) %>% factor(),
hospt = sample(c("Metro", "Rural"), 100, replace = TRUE) %>% factor(),
patient = TRUE
) %>%
group_by(siteidn) %>%
mutate(
count_site = row_number() == 1L # one TRUE per site
) %>%
ungroup() %>%
labelled::set_variable_labels(siteidn = "Number of ICUs", # Assigning labels
patient = "N")
t1 <- PIR %>%
select(patient, siteidn, countryname) %>%
tbl_summary(
by = countryname,
missing = "no",
statistic = patient ~ "{n}" # only print N for the top row
) %>%
modify_header(stat_by = "**{level}**") %>% # Remove the Ns from the header row
add_overall(col_label = "**Overall**")
t2 <- PIR %>%
select(patient, siteidn, hospt) %>%
tbl_summary(
by = hospt,
missing = "no",
statistic = patient ~ "{n}" # only print N for the top row
) %>%
modify_header(stat_by = "**{level}**") # Remove the Ns from the header row
tbl <-
tbl_merge(
tbls = list(t1, t2),
tab_spanner = c("**Country**", "**Hospital Type**")
) %>%
bold_labels() %>%
italicize_levels() %>%
# remove spanning header for overall column, use `show_header_names(tbl)` to print column names
modify_spanning_header(stat_0_1 ~ NA) %>%
modify_footnote(everything() ~ NA) # remove footnote, as it's not informative in this setting

РЕДАКТИРОВАТЬ: после уточнения исходного постера добавлен еще один пример того, как можно представить Ns.
В приведенной ниже таблице показаны два способа отображения Ns для пациентов и количества центров. Первая находится в двух строках с двумя переменными, а последняя строка представляет собой способ представления информации в одной строке.
t1 <- PIR %>%
select(patient, site_only = count_site, combination = count_site, countryname) %>%
tbl_summary(
by = countryname,
missing = "no",
statistic = list(c(patient, site_only) ~ "{n}",
combination ~ "Site N {n}; Total N {N}")
)
