Как улучшить запрос select min(my_col) в MySQL без добавления и индексации
Приведенный ниже запрос выполняется около минуты на моем экземпляре MySQL (работает на довольно мощной машине с 64 ГБ памяти, диском 2T, процессором 2,30 ГГц с 8 ядрами и 16 логическими, и запрос выполняется на локальном хосте). Этот же запрос выполняется менее чем за секунду в базе данных SQL Server, к которой у меня есть доступ. К сожалению, у меня нет доступа к хосту SQL Server, администратору базы данных и т. д.
select min(visit_start_date)
from visit_occurrence;
Стол был накрыт
Есть ли какая-то конфигурация, которую я мог бы пропустить, что заставило бы этот запрос работать так медленно в MySQL? Как я могу это исправить?
У меня есть большое количество таблиц и запросов, которые мне нужно будет поддерживать, поэтому я действительно хотел бы иметь возможность решить эту проблему глобально, а не создавать индексы везде, где у меня есть медленные запросы.
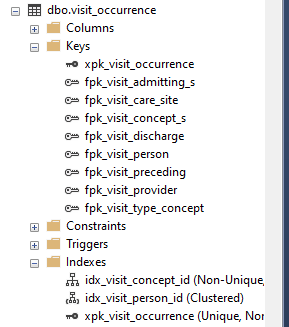
База данных SQL Server, похоже, не имеет индекса для запрашиваемого столбца, как показано ниже.
РЕДАКТИРОВАТЬ:
Нетегированный MS Sql Server, я пометил его, надеясь на помощь наших коллег из MS Sql Server с информацией о том, что у Sql Server есть какой-то способ структурирования данных и/или запросов, которые ускорят выполнение этого типа запросов на этой платформе v другие, такие как MySql
Удалено изображение кода для более точного соответствия стандартам сообщества.
Вы никогда не узнаете, есть ли волшебная кнопка ускорения, если вы не спросите (ENGINE=MyISAM иногда похож на волшебную кнопку ускорения для некоторых запросов в MySql). Я как бы ловлю здесь потенциальное аппаратное или кластерное решение. Является ли Apache Ignite потенциальным решением?
Еще раз спасибо сообществу за вашу поддержку и помощь. Я надеюсь, что это исправит большинство проблем, которые были подняты для этого поста.
ВТОРОЕ РЕДАКТИРОВАНИЕ: Является ли разделение/шардинг, описанное в ссылках ниже, потенциальным решением здесь?
https://user3141592.medium.com/how-to-scale-mysql-42ebd2841fa6
https://dev.mysql.com/doc/refman/8.0/en/partitioning-overview.html
ТРЕТЬЕ РЕДАКТИРОВАНИЕ: примечание о стандартах сообщества.
Частью наших общественных стандартов является гостеприимство, инклюзивность и доброжелательность.
Здесь использовался тег MS Sql Server, так как одной из сравниваемых систем является MS Sql Server. Мы действительно работаем с очень ограниченной информацией. У меня есть две системы: моя система MySql, которую можно узнать, поскольку я ее запускаю, и сервер MS Sql, работающий с той же базой данных в чужой системе, о которой у меня очень мало информации (все, что у меня есть, это приглашение sql только для чтения). Я сравниваю яблоки и апельсины: один и тот же запрос хорошо работает на апельсине (сервер MS Sql) и плохо работает на яблоке (экземпляр My MySql). Я хотел бы знать, почему, чтобы я мог принять обоснованное решение о том, как заставить мои запросы выполняться в разумные сроки. Как сделать яблоко похожим на апельсин? Переключиться ли на сервер MS Sql? Нужно ли развертывать на другом оборудовании? В другой системе работает какая-то система кэширования в памяти поверх их экземпляра базы данных? Для изучения и проверки большинства из этих возможностей потребуется немало времени. Так что да, я хотел бы получить помощь от экспертов MS Sql Server, которые могли бы знать, есть ли параметры кэширования, параметры транзакций и хранилища и т. д., которые можно было бы установить, что имело бы огромное значение, это были бы волшебные кнопки быстрого доступа.
Комментарий к волшебной кнопке «быстро», возможно, был немного снисходительным.
Изображение, показывающее индексы, было показано, поскольку я просто пытался подчеркнуть, что другая система, похоже, не имеет индекса для запрашиваемого столбца. В этом случае картинка стоила тысячи слов.
2 ответа
Если в таблице указано
ENGINE=MyISAM, то это то, что имеет значение. Почти во всех случаях это плохой выбор.
innodb_buffer_pool_size=16Gне имеет значения , за исключением того, что он отнимает память у MyISAM.
default-storage-engine=INNODBактуален только при создании таблицы с явным указанием
ENGINE=.
Некоторые из ваших таблиц MyISAM, а некоторые InnoDB? Сколько у вас оперативной памяти?
Большинство решений по повышению производительности обязательно включают
INDEX. Пожалуйста, объясните, почему вы не можете позволить себе индекс. Это может превратить этот запрос в менее чем 10 мс, независимо от количества строк в таблице.
Извините, но я не принимаю «вместо того, чтобы создавать индексы везде, где у меня медленные запросы».
Изменение таблиц с MyISAM на InnoDB в некоторых случаях поможет повысить производительность. Предлагаю изменить движок по мере добавления индексов.
Покажите нам еще несколько запросов, и мы поможем вам решить, какие индексы нужны.
select min(visit_start_date) from visit_occurrence;потребности
INDEX(date); другие запросы могут быть не такими тривиальными. Не попадайтесь в ловушку «индексировать каждый столбец».
Более
В MySQL...
Одно соединение использует только одно ядро, поэтому большее количество ядер помогает только при наличии большего количества соединений. (Некоторые крошечные исключения существуют в MySQL 8.0.)
Разделение редко помогает с производительностью; используйте это, не получая совета. (ПС:
BY RANGEпожалуй, единственный полезный вариант.)Репликация предназначена для чтения-масштабирования (и резервного копирования и...)
Шардинг предназначен для масштабирования записи. Это требует множества дополнительных архитектурных вещей, таких как маршрутизация запросов на соответствующие серверы. (В качестве возможных инструментов у MariaDB есть Spider и FederatedX.) В любом случае, сегментирование — нетривиальная задача.
Кластеризация предназначена для обеспечения высокой доступности (высокая доступность, автоматическая отработка отказа и т. д.), а некоторым помогает масштабировать операции чтения и записи. См.: Galera, кластер InnoDB.
Аппаратное обеспечение редко бывает чем-то большим, чем временное решение проблем с производительностью.
Кэширование приводит к потенциально противоречивым результатам, так что будьте осторожны. Кроме того, обратите внимание на мою мантру «не ставьте кеш перед кешем».
(Я могу дать совет по любой из этих тем.)
Будь то в MyISAM или InnoDB. или даже SQL Server, ваш запрос
select min(visit_start_date) from visit_occurrence;
может быть почти мгновенно удовлетворен этим индексом, потому что он использует так называемое свободное сканирование индекса .
CREATE INDEX visit_start_date ON visit_occurrence (visit_start_date);
Запрос с агрегатной функцией, такой как MIN(), всегда является запросом GROUP BY. Но если предложение GROUP BY отсутствует в операторе SQL, сервер группирует всю таблицу.
Вы упомянули запрос, который может быть немедленно удовлетворен при использовании MyISAM. Это
Дизайн индекса — это не черное искусство. Но это искусство, основанное на тех измерениях, которые мы получаем от ОБЪЯСНИТЬ (или АНАЛИЗИРОВАТЬ, или ОБЪЯСНИТЬ, АНАЛИЗИРОВАТЬ). Основная истина приложений, управляемых базой данных (при любом типе сервера базы данных), заключается в том, что индексирование необходимо пересматривать по мере роста приложения. Хорошая новость: изменение, добавление или удаление индексов не меняет ваших данных.