Отсутствующие данные в MLR RStudio
Я действительно новичок в кодировании и R, поэтому изо всех сил пытаюсь найти ответ, который я могу понять или узнать, является ли это ответом. Я надеюсь, что кто-нибудь может помочь.
Я пытаюсь провести множественную линейную регрессию в R.
Это данные опроса 561 человека. Вот образец первых 12 строк данных.
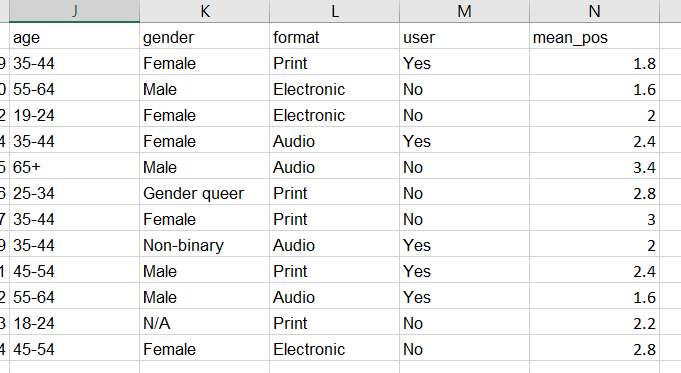
Я хочу найти значимость между положительным отношением, которое представляет собой среднее из 4 вопросов шкалы Лайкерта (зависимая переменная), и объясняющей переменной возраста, пола, пользователя и формата.
Я выполнил код все в одном:
mlrpositive.lm <- lm(mean_pos ~ age + gender + format + user, data = mlr.data)
Я заметил, что в нем отсутствовали объясняющие переменные, например, для возраста не было «18–24», для пола не было «женский», для пользователя отсутствовали «нет» и отсутствовал формат «Аудио».
Я выполнял каждую индивидуально и получил тот же результат.
positive.gender.lm <- lm(mean_pos ~ gender, data = mlr.data)
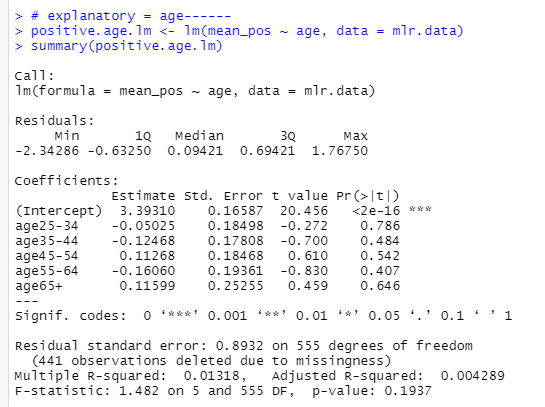
Я не знаю, как это исправить.
1 ответ
Это нормально. Когда вы запускаете регрессию по факторам, первый фактор улавливается перехватом. Невозможно показать столько отдельных факторов, сколько у вас есть категорий, потому что регрессия станет неопределенной и не запустится.
Это аналогично задаче в алгебре, если вы видите
5 = x + y; для числового ответа недостаточно информации, поэтому мы могли бы обосновать любое значение для x (и придумать подходящую копию y).
Точно так же мы могли бы оправдать бесконечный диапазон значений для первого фактора, при условии, что мы скорректируем другие коэффициенты, чтобы приспособиться. Вместо этого мы обрабатываем значение переменной, на которое явно не ссылаются, как «контрольную» группу, с которой сравниваются другие.
https://stattrek.com/multiple-regression/dummy-variables.aspx
При определении фиктивных переменных распространенной ошибкой является определение слишком большого количества переменных. Если категориальная переменная может принимать k значений, возникает соблазн определить k фиктивных переменных. Сопротивляйтесь этому побуждению. Помните, что вам нужно всего k - 1 фиктивных переменных.
K-я фиктивная переменная избыточна; он не несет никакой новой информации. И это создает серьезную проблему мультиколлинеарности для анализа. Использование k фиктивных переменных, когда требуется только k - 1 фиктивных переменных, называется ловушкой фиктивных переменных. Избегайте этой ловушки!
https://otexts.com/fpp2/useful-predictors.html#seasonal-dummy-variables
Многие новички попытаются добавить седьмую фиктивную переменную для седьмой категории. Это известно как «ловушка фиктивной переменной», потому что это приведет к сбою регрессии. Будет слишком много параметров для оценки, когда также будет включен перехват. Общее правило - использовать на одну фиктивную переменную меньше, чем категорий. Итак, для квартальных данных используйте три фиктивные переменные; для ежемесячных данных используйте 11 фиктивных переменных; а для ежедневных данных используйте шесть фиктивных переменных и так далее.
Интерпретация каждого из коэффициентов, связанных с фиктивными переменными, заключается в том, что он является мерой воздействия этой категории по отношению к пропущенной категории.