Пользовательский генератор данных для сегментации изображений выполняет различные дополнения к изображению и маске.
Я пытаюсь выполнить сегментацию изображений на дорогах, для которых я выполняю увеличение данных с помощью библиотеки imgaug, и я создаю собственный загрузчик данных для обучения, чтобы мне не приходилось хранить все изображения и маски в моей оперативной памяти. Это код моего пользовательского загрузчика данных:
- Улучшения:
# import imgaug.augmenters as iaa
# For the assignment choose any 4 augumentation techniques
# check the imgaug documentations for more augmentations
aug2 = iaa.Fliplr(1)
aug3 = iaa.Flipud(1)
aug4 = iaa.Emboss(alpha=(1), strength=1)
aug5 = iaa.DirectedEdgeDetect(alpha=(0.8), direction=(1.0))
aug6 = iaa.Sharpen(alpha=(1.0), lightness=(1.5))
- Загрузчик данных:
class Dataset:
'''
This class creates a dataset of (image, mask) pairs. It takes in a dataframe containing all the paths of the images
and masks, performs augmentation on them and returns them as a pair.
'''
def __init__(self, dataframe):
self.ipath = dataframe['image'] # image path
self.mpath = dataframe['mask'] # mask path
self.label_clr = {'road':10, 'parking':20, 'drivable fallback':20,'sidewalk':30,'non-drivable fallback':40,'rail track':40,\
'person':50, 'animal':50, 'rider':60, 'motorcycle':70, 'bicycle':70, 'autorickshaw':80,\
'car':80, 'truck':90, 'bus':90, 'vehicle fallback':90, 'trailer':90, 'caravan':90,\
'curb':100, 'wall':100, 'fence':110,'guard rail':110, 'billboard':120,'traffic sign':120,\
'traffic light':120, 'pole':130, 'polegroup':130, 'obs-str-bar-fallback':130,'building':140,\
'bridge':140,'tunnel':140, 'vegetation':150, 'sky':160, 'fallback background':160,'unlabeled':0,\
'out of roi':0, 'ego vehicle':170, 'ground':180,'rectification border':190,\
'train':200}
self.colors = list(set(self.label_clr.values())) # pixel values for each class
def __getitem__(self, i):
# this function loads the image and the mask and performs augmentation on top of it.
# reading data
# read data
image = cv2.imread(self.ipath.iloc[i], cv2.IMREAD_UNCHANGED)[:,:,::-1]
mask = cv2.imread(self.mpath.iloc[i], cv2.IMREAD_UNCHANGED)[:,:,::-1]
image = normalize_image(image)
# print(image.shape, image_mask.shape)
image = cv2.resize(src=image, dsize=(512,512), interpolation=cv2.INTER_NEAREST)
mask = cv2.resize(src=mask, dsize=(512,512), interpolation=cv2.INTER_NEAREST)
image_masks = [(mask[:,:,0] == v) for v in self.colors]
image_mask = np.stack(image_masks, axis=-1).astype('float')
# image_mask = normalize_image(image_mask) # no need to normalize the mask since it is alerady going to be a vector of ones and zeros which we want as the output labels
a = np.random.uniform()
# a=i[1]
print(a)
if a<0.2:
image = aug2.augment_image(image)
image_mask = aug2.augment_image(image_mask)
print('fliplr')
elif a<0.4:
image = aug3.augment_image(image)
image_mask = aug3.augment_image(image_mask)
print('Flipud')
elif a<0.6:
image = aug4.augment_image(image)
# image_mask = aug4.augment_image(image_mask)# no need to apply these augmentations since the masks for these remain the same anyways.
print('emboss')
elif a<0.8:
image = aug5.augment_image(image)
# image_mask = image_mask# no need to apply these augmentations since the masks for these remain the same anyways.
print('edge detect')
else:
image = aug6.augment_image(image)
# image_mask = aug6.augment_image(image_mask)# no need to apply these augmentations since the masks for these remain the same anyways.
print('Emboss')
return image, image_mask
def __len__(self):
return len(self.ipath)
########################################################################
class DataLoader(tf.keras.utils.Sequence):
'''
This class makes batches of data and gives them to the model during training.
'''
def __init__(self, dataset, batch_size=1, shuffle=False):
self.dataset = dataset
self.batch_size = batch_size
self.shuffle = shuffle
self.indexes = np.arange(len(dataset))
def __getitem__(self, i):
'''
This function makes batches of data and label masks from the dataset and returns it.
'''
# collect batch data
start = i*self.batch_size
stop = (i+1)*self.batch_size
data = []
for j in range(start, stop):
# a = np.random.uniform()
data.append(self.dataset[j])
batch = [np.stack(samples, axis=0) for samples in zip(*data)]
return tuple(batch)
def __len__(self):
return len(self.indexes)//self.batch_size
def on_epoch_end(self):
if self.shuffle:
self.indexes = np.random.permutation(self.indexes)
Однако, когда я тестировал генератор, создавая изображения для образца, я обнаружил, что генератор данных применяет различные дополнения как к изображению, так и к маске. Вот код и результаты, которые я получил:
image, mask = test_dataloader[21][0][0], test_dataloader[21][1][0]
orig_argmax = np.argmax(mask, axis=-1)
orig_argmax = np.expand_dims(orig_argmax, axis=2)
orig_mask = np.concatenate((orig_argmax*10, orig_argmax*10, orig_argmax*10), axis=-1) # concatenating into 3 channels for RGB
fig, ax = plt.subplots(ncols=2, figsize=(15,15))
# plot_image(img[0], ax[0], 'Original Image')
plot_image(image, ax[0], 'Original Image (Augmented)')
plot_image(orig_mask, ax[1], 'Original Mask')
Печать аугментаций, примененных к изображению, и значения
a:
Изображение и маска после увеличения:
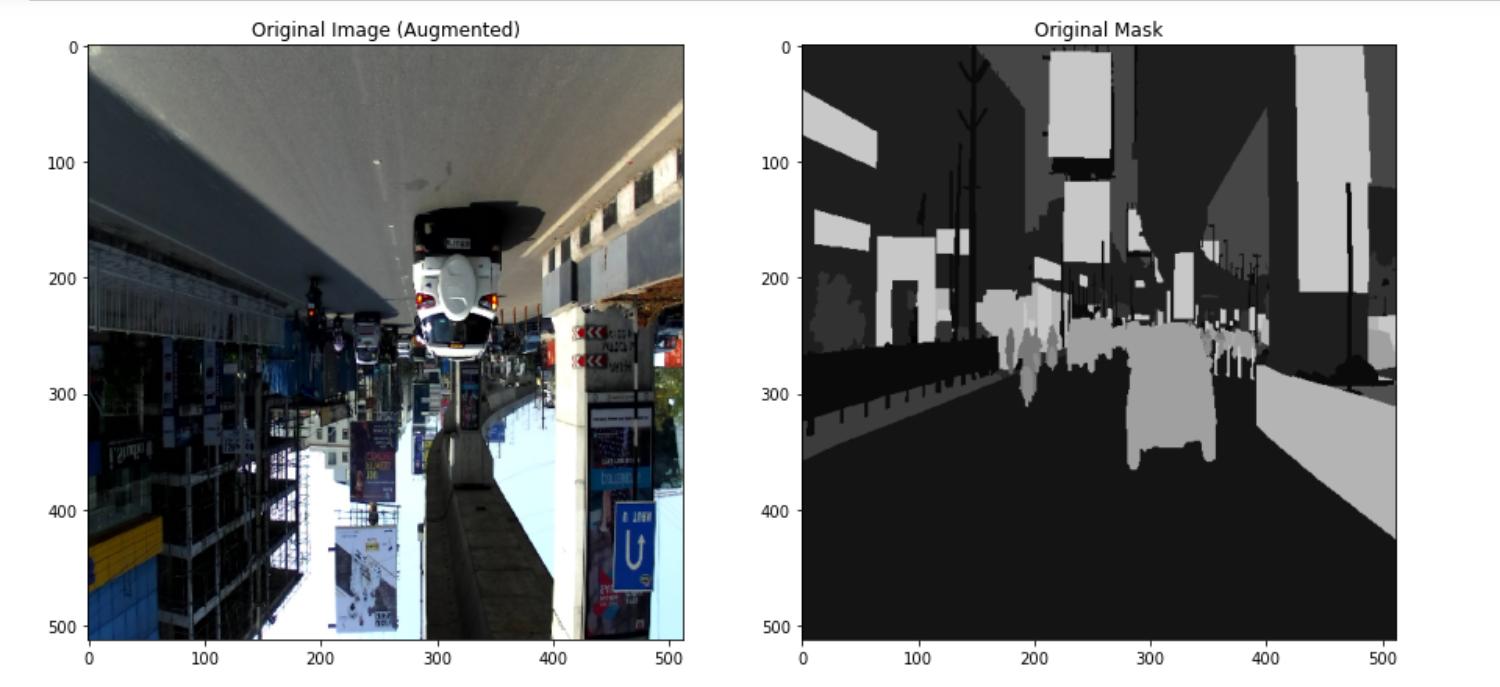
Из того, что я могу понять, дополнения применяются дважды отдельно к изображению и маске, а функция getitem из класса Dataset вызывается дважды, следовательно, результаты такие. Однако я не понимаю, почему это произошло и как решить эту проблему. Любые ответы на этот вопрос очень помогут.
Спасибо.