Объяснение панд ильок против икс против лока, чем они отличаются?
Может кто-нибудь объяснить, чем эти три метода нарезки отличаются?
Я видел документы, и я видел эти ответы, но я все еще не могу объяснить, чем они отличаются. Мне они кажутся взаимозаменяемыми в значительной степени, потому что они находятся на более низких уровнях нарезки.
Например, скажем, мы хотим получить первые пять строк DataFrame, Как получается, что все три из них работают?
df.loc[:5]
df.ix[:5]
df.iloc[:5]
Может ли кто-нибудь представить три случая, когда различие в использовании яснее?
8 ответов
Примечание: в версиях панд 0.20.0 и выше, ix устарела и использование loc а также iloc вместо этого рекомендуется. Я оставил части этого ответа, которые описывают ix нетронутым как ссылка для пользователей более ранних версий панд. Ниже были добавлены примеры, показывающие альтернативы ix,
Во-первых, вот резюме трех методов:
locполучает строки (или столбцы) с определенными метками из индекса.ilocполучает строки (или столбцы) в определенных позициях в индексе (поэтому он принимает только целые числа).ixобычно пытается вести себя какlocно возвращается к ведению себя какilocесли метка отсутствует в индексе.
Важно отметить некоторые тонкости, которые могут сделать ix немного сложнее в использовании:
если индекс целочисленного типа,
ixбудет использовать только индексирование на основе меток и не отступать от индексации на основе позиций. Если метка отсутствует в индексе, возникает ошибка.если индекс не содержит только целых чисел, тогда задано целое число,
ixнемедленно использует индексацию на основе позиции, а не индексацию на основе меток. Если однакоixему присваивается другой тип (например, строка), он может использовать индексирование на основе меток.
Чтобы проиллюстрировать различия между тремя методами, рассмотрим следующие серии:
>>> s = pd.Series(np.nan, index=[49,48,47,46,45, 1, 2, 3, 4, 5])
>>> s
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
Мы рассмотрим нарезку с целочисленным значением 3,
В этом случае, s.iloc[:3] возвращает нам первые 3 строки (поскольку он рассматривает 3 как позицию) и s.loc[:3] возвращает нам первые 8 строк (поскольку он рассматривает 3 как метку):
>>> s.iloc[:3] # slice the first three rows
49 NaN
48 NaN
47 NaN
>>> s.loc[:3] # slice up to and including label 3
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
>>> s.ix[:3] # the integer is in the index so s.ix[:3] works like loc
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
уведомление s.ix[:3] возвращает ту же серию, что и s.loc[:3] поскольку он сначала ищет метку, а не работает над позицией (и индексом для s имеет целочисленный тип).
Что если мы попробуем с целочисленной меткой, которой нет в индексе (скажем, 6)?
Вот s.iloc[:6] возвращает первые 6 рядов Серии, как и ожидалось. Тем не мение, s.loc[:6] вызывает KeyError, так как 6 не в индексе.
>>> s.iloc[:6]
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
>>> s.loc[:6]
KeyError: 6
>>> s.ix[:6]
KeyError: 6
В соответствии с тонкостями, указанными выше, s.ix[:6] теперь вызывает KeyError, потому что он пытается работать как loc но не могу найти 6 в указателе. Потому что наш индекс имеет целочисленный тип ix не отступать к ведению себя как iloc,
Если, однако, наш индекс был смешанного типа, учитывая целое число ix будет вести себя как iloc немедленно вместо вызова KeyError:
>>> s2 = pd.Series(np.nan, index=['a','b','c','d','e', 1, 2, 3, 4, 5])
>>> s2.index.is_mixed() # index is mix of different types
True
>>> s2.ix[:6] # now behaves like iloc given integer
a NaN
b NaN
c NaN
d NaN
e NaN
1 NaN
Имейте в виду, что ix все еще может принимать нецелые и вести себя как loc:
>>> s2.ix[:'c'] # behaves like loc given non-integer
a NaN
b NaN
c NaN
Как общий совет, если вы индексируете только по меткам или индексируете только по целочисленным позициям, придерживайтесь loc или же iloc чтобы избежать неожиданных результатов - старайтесь не использовать ix,
Объединение индексации на основе позиции и метки
Иногда, учитывая DataFrame, вы захотите смешать метки и методы позиционной индексации для строк и столбцов.
Например, рассмотрим следующий DataFrame. Как лучше всего нарезать строки до 'c' включительно и взять первые четыре столбца?
>>> df = pd.DataFrame(np.nan,
index=list('abcde'),
columns=['x','y','z', 8, 9])
>>> df
x y z 8 9
a NaN NaN NaN NaN NaN
b NaN NaN NaN NaN NaN
c NaN NaN NaN NaN NaN
d NaN NaN NaN NaN NaN
e NaN NaN NaN NaN NaN
В более ранних версиях панд (до 0.20.0) ix позволяет сделать это довольно аккуратно - мы можем разделить строки по меткам и столбцы по позициям (обратите внимание, что для столбцов, ix по умолчанию будет нарезка на основе позиции, так как 4 не является именем столбца):
>>> df.ix[:'c', :4]
x y z 8
a NaN NaN NaN NaN
b NaN NaN NaN NaN
c NaN NaN NaN NaN
В более поздних версиях панд мы можем достичь этого результата, используя iloc и помощь другого метода:
>>> df.iloc[:df.index.get_loc('c') + 1, :4]
x y z 8
a NaN NaN NaN NaN
b NaN NaN NaN NaN
c NaN NaN NaN NaN
get_loc() метод индекса, означающий "получить позицию метки в этом индексе". Обратите внимание, что, так как нарезка с iloc не зависит от его конечной точки, мы должны добавить 1 к этому значению, если мы хотим, чтобы строка 'c' также.
Другие примеры в документации панд здесь.
iloc работает на основе целочисленного позиционирования. Поэтому независимо от того, какие у вас метки строк, вы всегда можете, например, получить первый ряд, выполнив
df.iloc[0]
или последние пять строк, выполнив
df.iloc[-5:]
Вы также можете использовать его на столбцах. Это возвращает 3-й столбец:
df.iloc[:, 2] # the : in the first position indicates all rows
Вы можете объединить их, чтобы получить пересечения строк и столбцов:
df.iloc[:3, :3] # The upper-left 3 X 3 entries (assuming df has 3+ rows and columns)
С другой стороны, .loc использовать именованные индексы. Давайте настроим фрейм данных со строками в виде меток строк и столбцов:
df = pd.DataFrame(index=['a', 'b', 'c'], columns=['time', 'date', 'name'])
Тогда мы можем получить первый ряд
df.loc['a'] # equivalent to df.iloc[0]
а вторые два ряда 'date' столбец
df.loc['b':, 'date'] # equivalent to df.iloc[1:, 1]
и так далее. Теперь, вероятно, стоит указать, что индексы строк и столбцов по умолчанию для DataFrame целые числа от 0, и в этом случае iloc а также loc будет работать таким же образом. Вот почему ваши три примера эквивалентны. Если у вас был нечисловой индекс, такой как строки или даты, df.loc[:5] поднимет ошибку.
Кроме того, вы можете сделать поиск столбцов, просто используя фреймы данных __getitem__:
df['time'] # equivalent to df.loc[:, 'time']
Теперь предположим, что вы хотите смешать индексирование позиций и имен, то есть индексирование с использованием имен в строках и позиций в столбцах (для пояснения я имею в виду выбор из нашего фрейма данных, а не создание фрейма данных со строками в индексе строк и целыми числами индекс столбца). Это где .ix приходит в:
df.ix[:2, 'time'] # the first two rows of the 'time' column
РЕДАКТИРОВАТЬ: Я думаю, что также стоит упомянуть, что вы можете передавать логические векторы в loc метод также. Например:
b = [True, False, True]
df.loc[b]
Вернет 1-й и 3-й ряды df, Это эквивалентно df[b] для выбора, но его также можно использовать для присваивания через логические векторы:
df.loc[b, 'name'] = 'Mary', 'John'
На мой взгляд, принятый ответ сбивает с толку, поскольку он использует DataFrame только с пропущенными значениями. Мне также не нравится термин, основанный на позиции для .iloc и вместо этого, предпочтите целочисленное местоположение, поскольку это намного более наглядно и что именно .iloc обозначает. Ключевое слово INTEGER - .iloc нужны INTEGERS.
Посмотрите мою чрезвычайно подробную серию блогов о выборе подмножеств для получения дополнительной информации.
.ix устарела и неоднозначна и никогда не должна использоваться
Так как .ix устарела, мы сосредоточимся только на различиях между .loc а также .iloc,
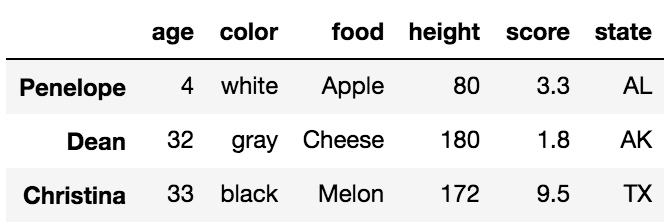
Прежде чем говорить о различиях, важно понять, что в фреймах данных есть метки, которые помогают идентифицировать каждый столбец и каждый индекс. Давайте посмотрим на пример DataFrame:
df = pd.DataFrame({'age':[30, 2, 12, 4, 32, 33, 69],
'color':['blue', 'green', 'red', 'white', 'gray', 'black', 'red'],
'food':['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'height':[165, 70, 120, 80, 180, 172, 150],
'score':[4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'state':['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']
},
index=['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
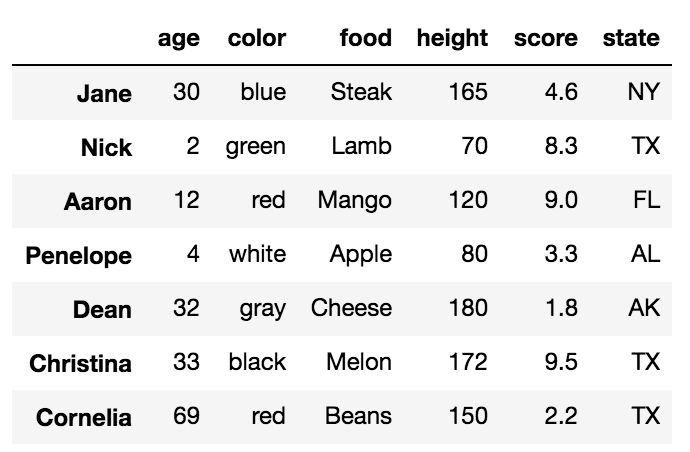
Все слова, выделенные жирным шрифтом, являются метками. Этикетки, age, color, food, height, score а также state используются для столбцов. Другие ярлыки, Jane, Nick, Aaron, Penelope, Dean, Christina, Cornelia используются для индекса.
Основными способами выбора отдельных строк в DataFrame являются .loc а также .iloc индексаторах. Каждый из этих индексаторов также можно использовать для одновременного выбора столбцов, но сейчас проще сосредоточиться на строках. Кроме того, каждый из индексаторов использует набор скобок, которые следуют сразу за их именем, чтобы сделать свой выбор.
.loc выбирает данные только по меткам
Сначала поговорим о .loc индексатор, который выбирает данные только по меткам индекса или столбца. В нашем примере DataFrame мы предоставили значимые имена в качестве значений для индекса. Многие DataFrames не будут иметь каких-либо значимых имен, и вместо этого по умолчанию будут просто целые числа от 0 до n-1, где n - длина DataFrame.
Есть три различных входа, которые вы можете использовать для .loc
- Строка
- Список строк
- Запись среза с использованием строк в качестве начального и конечного значений
Выбор одной строки с помощью.loc со строкой
Чтобы выбрать одну строку данных, поместите индексную метку в скобки после .loc,
df.loc['Penelope']
Это возвращает строку данных в виде серии
age 4
color white
food Apple
height 80
score 3.3
state AL
Name: Penelope, dtype: object
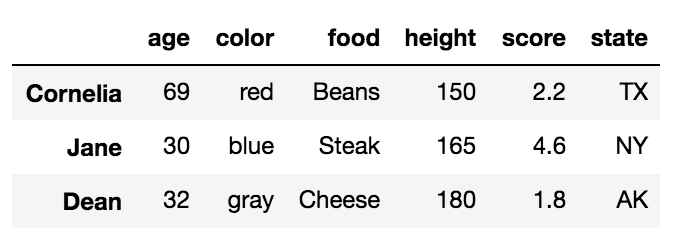
Выбор нескольких строк с помощью.loc со списком строк
df.loc[['Cornelia', 'Jane', 'Dean']]
Это возвращает DataFrame со строками в порядке, указанном в списке:
Выбор нескольких строк с помощью.loc с обозначением слайса
Обозначение среза определяется значениями start, stop и step. При нарезке по меткам, pandas включает в себя значение стопа в возврате. Следующие кусочки от Аарона до Дина включительно. Размер шага явно не определен, но по умолчанию равен 1.
df.loc['Aaron':'Dean']
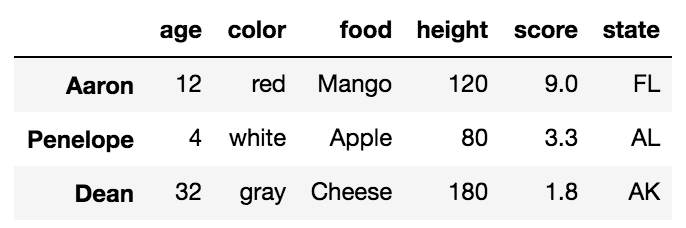
Сложные фрагменты могут быть взяты так же, как списки Python.
.iloc выбирает данные только по целому расположению
Давайте теперь обратимся к .iloc, Каждая строка и столбец данных в DataFrame имеет целочисленное местоположение, которое определяет его. Это в дополнение к метке, которая визуально отображается в выходных данных. Целочисленное местоположение - это просто число строк / столбцов сверху / слева, начиная с 0.
Есть три различных входа, которые вы можете использовать для .iloc
- Целое число
- Список целых чисел
- Запись среза с использованием целых чисел в качестве начального и конечного значений
Выбор одной строки с.iloc с целым числом
df.iloc[4]
Это возвращает 5-ую строку (целочисленное расположение 4) как серию
age 32
color gray
food Cheese
height 180
score 1.8
state AK
Name: Dean, dtype: object
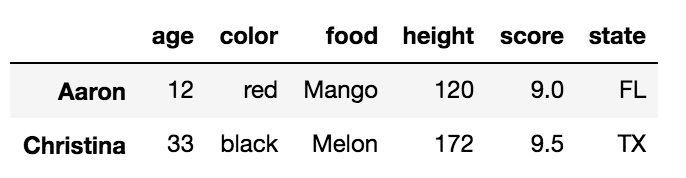
Выбор нескольких строк с.iloc со списком целых чисел
df.iloc[[2, -2]]
Это возвращает DataFrame третьей и второй до последней строки:
Выбор нескольких строк с помощью.iloc с обозначением среза
df.iloc[:5:3]

Одновременный выбор строк и столбцов с.loc и.iloc
Одна отличная способность обоих .loc/.iloc это их способность выбирать строки и столбцы одновременно. В приведенных выше примерах все столбцы возвращались из каждого выбора. Мы можем выбрать столбцы с теми же типами входов, что и для строк. Нам просто нужно разделить выбор строки и столбца запятой.
Например, мы можем выбрать строки Джейн и Дина только с высотой, счетом и состоянием столбцов следующим образом:
df.loc[['Jane', 'Dean'], 'height':]
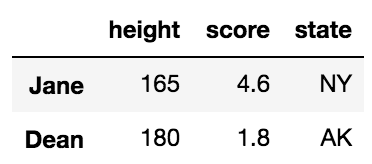
При этом используется список меток для строк и нотации для столбцов
Естественно, мы можем делать подобные операции с .iloc используя только целые числа.
df.iloc[[1,4], 2]
Nick Lamb
Dean Cheese
Name: food, dtype: object
Одновременный выбор с метками и целочисленным расположением
.ix был использован для выбора одновременно с метками и целочисленным местоположением, что было полезно, но иногда сбивало с толку и неоднозначно, и, к счастью, это устарело. В случае, если вам нужно сделать выборку с сочетанием меток и целочисленных местоположений, вы должны будете сделать как ваши метки выбора, так и целочисленные местоположения.
Например, если мы хотим выбрать строки Nick а также Cornelia вместе со столбцами 2 и 4 мы могли бы использовать .loc путем преобразования целых чисел в метки со следующим:
col_names = df.columns[[2, 4]]
df.loc[['Nick', 'Cornelia'], col_names]
Или же, преобразуйте метки индекса в целые числа с помощью get_loc индексный метод.
labels = ['Nick', 'Cornelia']
index_ints = [df.index.get_loc(label) for label in labels]
df.iloc[index_ints, [2, 4]]
Логическое выделение
Индексатор.loc также может выполнять логический выбор. Например, если мы заинтересованы в поиске всех строк, где возраст старше 30 лет, и возвращаем только food а также score По столбцам мы можем сделать следующее:
df.loc[df['age'] > 30, ['food', 'score']]
Вы можете повторить это с .iloc но вы не можете передать это логическое число. Вы должны преобразовать логическую серию в массив numpy следующим образом:
df.iloc[(df['age'] > 30).values, [2, 4]]
Выбор всех строк
Можно использовать .loc/.iloc только для выбора столбца. Вы можете выбрать все строки, используя двоеточие, как это:
df.loc[:, 'color':'score':2]
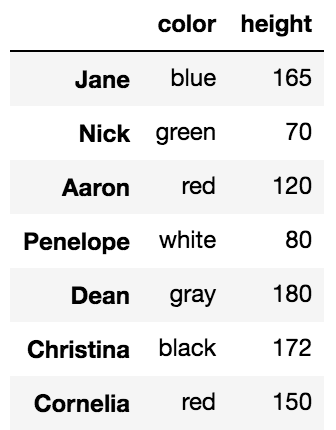
Оператор индексирования, [], можно выбрать строки и столбцы тоже, но не одновременно.
Большинству людей знакомо основное назначение оператора индексации DataFrame - выбор столбцов. Строка выбирает один столбец в качестве Серии, а список строк выбирает несколько столбцов в качестве DataFrame.
df['food']
Jane Steak
Nick Lamb
Aaron Mango
Penelope Apple
Dean Cheese
Christina Melon
Cornelia Beans
Name: food, dtype: object
Использование списка выбирает несколько столбцов
df[['food', 'score']]
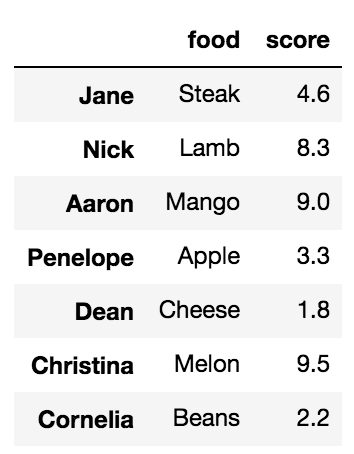
Люди менее знакомы с тем, что при использовании обозначения среза выбор происходит по меткам строк или по целочисленному расположению. Это очень сбивает с толку и то, что я почти никогда не использую, но это работает.
df['Penelope':'Christina'] # slice rows by label
df[2:6:2] # slice rows by integer location

Явность .loc/.iloc для выбора строк весьма предпочтителен. Один оператор индексирования не может одновременно выбирать строки и столбцы.
df[3:5, 'color']
TypeError: unhashable type: 'slice'
Этот пример проиллюстрирует разницу:
df = pd.DataFrame({'col1': [1,2,3,4,5], 'col2': ["foo", "bar", "baz", "foobar", "foobaz"]})
col1 col2
0 1 foo
1 2 bar
2 3 baz
3 4 foobar
4 5 foobaz
df = df.sort_values('col1', ascending = False)
col1 col2
4 5 foobaz
3 4 foobar
2 3 baz
1 2 bar
0 1 foo
Доступ на основе индекса:
df.iloc[0, 0:2]
col1 5
col2 foobaz
Name: 4, dtype: object
Получаем первую строку отсортированного фрейма данных. (Это не строка с индексом 0, а с индексом 4).
Доступ по местоположению:
df.loc[0, 'col1':'col2']
col1 1
col2 foo
Name: 0, dtype: object
Мы получаем строку с индексом 0, даже когда df отсортирован.
и используются для индексации, т. е. для извлечения частей данных. По сути, разница в том, что разрешена индексация на основе меток и возможность индексации на основе позиции.
Если вас смущает и, имейте в виду, что он основан на позиции индекса (начиная с i ), а основан на метке (начиная с l ).
предполагается, что он основан на метках индекса, а не на позициях, поэтому он аналогичен индексированию на основе словаря Python. Однако он может принимать логические массивы, срезы и список меток (ни один из которых не работает со словарем Python).
iloc
выполняет поиск на основе позиции индекса, т. е. ведет себя аналогично списку Python.
pandas поднимет
IndexError если в этом месте нет индекса.
Примеры
Следующие ниже примеры представлены, чтобы проиллюстрировать различия между и. Рассмотрим следующую серию:
>>> s = pd.Series([11, 9], index=["1990", "1993"], name="Magic Numbers")
>>> s
1990 11
1993 9
Name: Magic Numbers , dtype: int64
.iloc Примеры
>>> s.iloc[0]
11
>>> s.iloc[-1]
9
>>> s.iloc[4]
Traceback (most recent call last):
...
IndexError: single positional indexer is out-of-bounds
>>> s.iloc[0:3] # slice
1990 11
1993 9
Name: Magic Numbers , dtype: int64
>>> s.iloc[[0,1]] # list
1990 11
1993 9
Name: Magic Numbers , dtype: int64
Примеры
>>> s.loc['1990']
11
>>> s.loc['1970']
Traceback (most recent call last):
...
KeyError: ’the label [1970] is not in the [index]’
>>> mask = s > 9
>>> s.loc[mask]
1990 11
Name: Magic Numbers , dtype: int64
>>> s.loc['1990':] # slice
1990 11
1993 9
Name: Magic Numbers, dtype: int64
Потому что
s имеет значения индекса строки,
.loc потерпит неудачу при индексировании с целым числом:
>>> s.loc[0]
Traceback (most recent call last):
...
KeyError: 0
- DataFrame.loc(): выбор строк по значению индекса
- DataFrame.iloc(): выбор строк по номеру строк
пример :
- Выберите первые 5 строк таблицы, df1 - ваш фрейм данных
df1.iloc[:5]
- Выберите первые строки A, B таблицы, df1 - ваш фрейм данных
df1.loc['A','B']
Все ответы здесь говорят о разнице между и при запросе кадра данных. Еще одно отличие заключается в том, что серию/кадр данных можно увеличить , но нельзя. Другими словами, когда дело доходит до назначения/изменения значений в фрейме данных, можно присваивать значения совершенно новой строке (а также изменять то, что уже есть), а изменять можно только то, что уже есть в фрейме данных.
В следующем коде сlocмы можем добавить новую строку в кадр данных; мы не можем сделать то же самое сiloc.
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
df.loc[3] = [4, 'd'] # <--- OK (now `df` has 4 rows)
df.iloc[4] = [4, 'd'] # <--- error
Та же логика применима и к родственным методам.atиiatтакже.
df.at[4, 'A'] = 4 # <--- OK
df.iat[5, 0] = 5 # <--- error
Позвольте мне сказать вам, что ix был в предыдущих версиях pandas.and iloc, а loc включена в его последние версии.
- IX-это используется для синтаксического анализа любых конкретных данных из фрейма данных с использованием либо метки, либо индекса строки и столбца за раз. Так что возникла небольшая проблема, как в некотором случае, когда индекс столбца и индекс строки оба были комбинацией числовых и строковых меток.
Пример:-df.ix[:2, 'time']
Теперь приходите в лока.
- Это анализирует данные, используя метки в качестве индекса, будь то столбец или строка.
Пример:-df.loc[:, 'color':'score':2]
Теперь для iloc.
- Что мы делаем, мы предоставляем столбец и строку в качестве индекса (обозначается номером)
Пример:-df.iloc[[1,4], 2]