Панды лок против илок против икс против у против иат?
Недавно начал переходить из моего безопасного места (R) в Python, и меня немного смущает локализация / выборка ячеек в Pandas, Я прочитал документацию, но изо всех сил пытаюсь понять практические последствия различных вариантов локализации / выбора.
- Есть ли причина, почему я должен когда-либо использовать
.locили же.ilocнад самым общим вариантом.ix? - Я это понимаю
.loc,iloc,at, а такжеiatможет обеспечить некоторую гарантированную правильность.ixне могу предложить, но я также читал, где.ixимеет тенденцию быть самым быстрым решением по всем направлениям. - Пожалуйста, объясните реальную практическую причину использования чего-либо, кроме
.ix?
6 ответов
loc: только работа с индексом
iloc: работа на позиции
ix: вы можете получить данные из фрейма данных, не добавляя их в индекс
at: получить скалярные значения. Это очень быстрый лока
iat: получить скалярные значения. Это очень быстрый iloc
http://pyciencia.blogspot.com/2015/05/obtener-y-filtrar-datos-de-un-dataframe.html
Примечание: по состоянию на pandas 0.20.0, .ix индексатор не рекомендуется в пользу более строгих .iloc а также .loc индексаторах.
Обновлено для pandas0.20 При условии ix устарела. Это демонстрирует не только как использовать loc, iloc, at, iat, set_value, но как это сделать, смешанная позиционная / метка индексации.
loc - на основе этикетки
Позволяет передавать одномерные массивы в качестве индексаторов. Массивы могут быть либо срезами (подмножествами) индекса или столбца, либо они могут быть логическими массивами, длина которых равна индексу или столбцам.
Специальное примечание: когда передается скалярный индексатор, loc Можно назначить новый индекс или значение столбца, которые не существовали ранее.
# label based, but we can use position values
# to get the labels from the index object
df.loc[df.index[2], 'ColName'] = 3
df.loc[df.index[1:3], 'ColName'] = 3
iloc - позиция основана
Похожий на loc кроме как с позициями, а не значениями индекса. Однако вы не можете назначать новые столбцы или индексы.
# position based, but we can get the position
# from the columns object via the `get_loc` method
df.iloc[2, df.columns.get_loc('ColName')] = 3
df.iloc[2, 4] = 3
df.iloc[:3, 2:4] = 3
at - на основе этикетки
Работает очень похоже на loc для скалярных индексаторов. Не может работать с индексаторами массива. Можно! назначить новые индексы и столбцы.
Преимущество над loc в том, что это быстрее
Недостатком является то, что вы не можете использовать массивы для индексаторов.
# label based, but we can use position values
# to get the labels from the index object
df.at[df.index[2], 'ColName'] = 3
df.at['C', 'ColName'] = 3
iat - позиция основана
Работает аналогично iloc, Не может работать в индексаторах массива. Не могу! назначить новые индексы и столбцы.
Преимущество над iloc в том, что это быстрее
Недостатком является то, что вы не можете использовать массивы для индексаторов.
# position based, but we can get the position
# from the columns object via the `get_loc` method
IBM.iat[2, IBM.columns.get_loc('PNL')] = 3
set_value - на основе этикетки
Работает очень похоже на loc для скалярных индексаторов. Не может работать с индексаторами массива. Можно! назначить новые индексы и столбцы
Преимущество Super fast, потому что накладных расходов очень мало!
Недостаток Очень мало накладных расходов, потому что pandas не делает кучу проверок безопасности. Используйте на свой страх и риск. Кроме того, это не предназначено для общественного использования.
# label based, but we can use position values
# to get the labels from the index object
df.set_value(df.index[2], 'ColName', 3)
set_value с takable=True - позиция основана
Работает аналогично iloc, Не может работать в индексаторах массива. Не могу! назначить новые индексы и столбцы.
Преимущество Super fast, потому что накладных расходов очень мало!
Недостаток Очень мало накладных расходов, потому что pandas не делает кучу проверок безопасности. Используйте на свой страх и риск. Кроме того, это не предназначено для общественного использования.
# position based, but we can get the position
# from the columns object via the `get_loc` method
df.set_value(2, df.columns.get_loc('ColName'), 3, takable=True)
Есть два основных способа, которыми pandas делает выбор из DataFrame.
- По метке
- По целому расположению
В документации термин " позиция" используется для обозначения целочисленного местоположения. Мне не нравится эта терминология, поскольку я чувствую, что она сбивает с толку. Целочисленное местоположение более наглядно и именно то, что .iloc обозначает. Ключевое слово здесь - INTEGER - вы должны использовать целые числа при выборе по целому расположению.
Прежде чем показывать резюме, давайте убедимся, что...
.ix устарела и неоднозначна и никогда не должна использоваться
Есть три основных индекса для панд. У нас есть сам оператор индексации (скобки []), .loc, а также .iloc, Давайте подведем их итоги:
[]- В первую очередь выбирает подмножества столбцов, но также может выбирать строки. Невозможно одновременно выбрать строки и столбцы..loc- выбирает подмножества строк и столбцов только по меткам.iloc- выбирает подмножества строк и столбцов только целочисленным расположением
Я почти никогда не пользуюсь .at или же .iat поскольку они не добавляют никакой дополнительной функциональности и лишь незначительно увеличивают производительность. Я бы не рекомендовал их использовать, если у вас нет очень чувствительного ко времени приложения. Несмотря на это, у нас есть их резюме:
.atвыбирает одно скалярное значение в DataFrame только по метке.iatвыбирает одно скалярное значение в DataFrame только по целому расположению
В дополнение к выбору по метке и целочисленному местоположению существует логическое выделение, также известное как логическое индексирование.
Примеры, объясняющие .loc, .iloc, логическое выделение и .at а также .iat показаны ниже
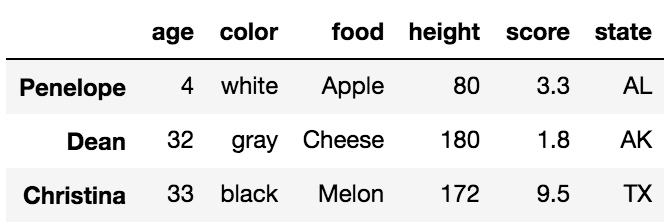
Сначала мы сосредоточимся на различиях между .loc а также .iloc, Прежде чем говорить о различиях, важно понять, что в фреймах данных есть метки, которые помогают идентифицировать каждый столбец и каждую строку. Давайте посмотрим на пример DataFrame:
df = pd.DataFrame({'age':[30, 2, 12, 4, 32, 33, 69],
'color':['blue', 'green', 'red', 'white', 'gray', 'black', 'red'],
'food':['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'height':[165, 70, 120, 80, 180, 172, 150],
'score':[4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'state':['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']
},
index=['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
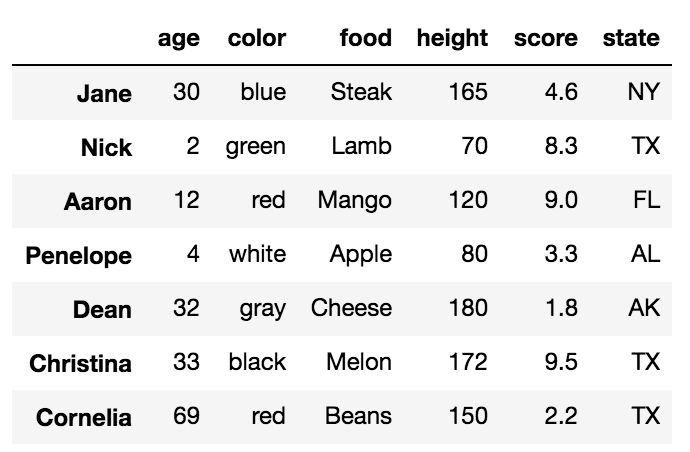
Все слова, выделенные жирным шрифтом, являются метками. Этикетки, age, color, food, height, score а также state используются для столбцов. Другие ярлыки, Jane, Nick, Aaron, Penelope, Dean, Christina, Cornelia используются в качестве меток для строк. В совокупности эти метки строк известны как индекс.
Основными способами выбора отдельных строк в DataFrame являются .loc а также .iloc индексаторах. Каждый из этих индексаторов также можно использовать для одновременного выбора столбцов, но сейчас проще сосредоточиться на строках. Кроме того, каждый из индексаторов использует набор скобок, которые следуют сразу за их именем, чтобы сделать свой выбор.
.loc выбирает данные только по меткам
Сначала поговорим о .loc индексатор, который выбирает данные только по меткам индекса или столбца. В нашем примере DataFrame мы предоставили значимые имена в качестве значений для индекса. Многие DataFrames не будут иметь каких-либо значимых имен, и вместо этого по умолчанию будут просто целые числа от 0 до n-1, где n - длина DataFrame.
Есть три различных входа, которые вы можете использовать для .loc
- Строка
- Список строк
- Запись среза с использованием строк в качестве начального и конечного значений
Выбор одной строки с помощью.loc со строкой
Чтобы выбрать одну строку данных, поместите индексную метку в скобки после .loc,
df.loc['Penelope']
Это возвращает строку данных в виде серии
age 4
color white
food Apple
height 80
score 3.3
state AL
Name: Penelope, dtype: object
Выбор нескольких строк с помощью.loc со списком строк
df.loc[['Cornelia', 'Jane', 'Dean']]
Это возвращает DataFrame со строками в порядке, указанном в списке:
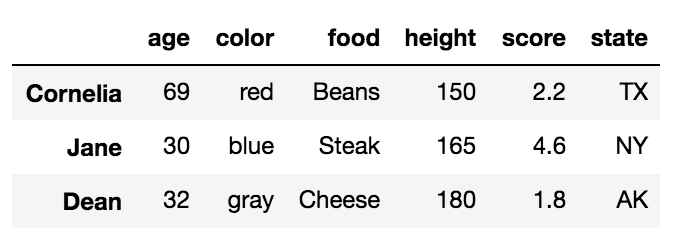
Выбор нескольких строк с помощью.loc с обозначением слайса
Обозначение среза определяется значениями start, stop и step. При нарезке по меткам, pandas включает в себя значение стопа в возврате. Следующие кусочки от Аарона до Дина включительно. Размер шага явно не определен, но по умолчанию равен 1.
df.loc['Aaron':'Dean']
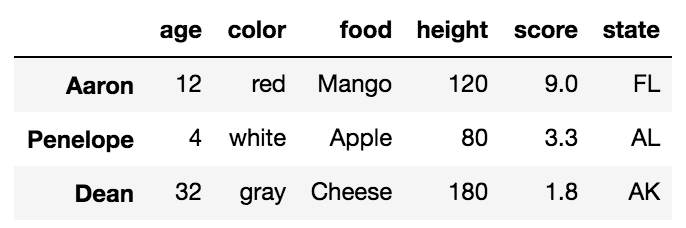
Сложные фрагменты могут быть взяты так же, как списки Python.
.iloc выбирает данные только по целому расположению
Давайте теперь обратимся к .iloc, Каждая строка и столбец данных в DataFrame имеет целочисленное местоположение, которое определяет его. Это в дополнение к метке, которая визуально отображается в выходных данных. Целочисленное местоположение - это просто число строк / столбцов сверху / слева, начиная с 0.
Есть три различных входа, которые вы можете использовать для .iloc
- Целое число
- Список целых чисел
- Запись среза с использованием целых чисел в качестве начального и конечного значений
Выбор одной строки с.iloc с целым числом
df.iloc[4]
Это возвращает 5-ую строку (целочисленное расположение 4) как серию
age 32
color gray
food Cheese
height 180
score 1.8
state AK
Name: Dean, dtype: object
Выбор нескольких строк с.iloc со списком целых чисел
df.iloc[[2, -2]]
Это возвращает DataFrame третьей и второй до последней строки:
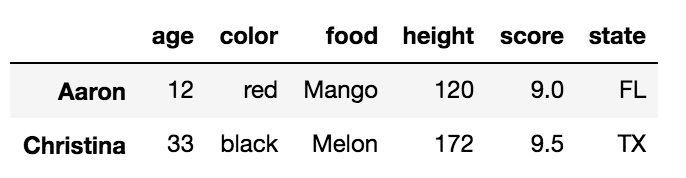
Выбор нескольких строк с помощью.iloc с обозначением среза
df.iloc[:5:3]

Одновременный выбор строк и столбцов с.loc и.iloc
Одна отличная способность обоих .loc/.iloc это их способность выбирать строки и столбцы одновременно. В приведенных выше примерах все столбцы возвращались из каждого выбора. Мы можем выбрать столбцы с теми же типами входов, что и для строк. Нам просто нужно разделить выбор строки и столбца запятой.
Например, мы можем выбрать строки Джейн и Дина только с высотой, счетом и состоянием столбцов следующим образом:
df.loc[['Jane', 'Dean'], 'height':]
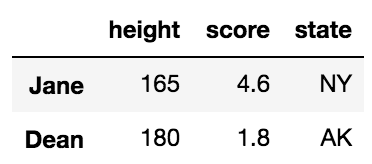
При этом используется список меток для строк и нотации для столбцов
Естественно, мы можем делать подобные операции с .iloc используя только целые числа.
df.iloc[[1,4], 2]
Nick Lamb
Dean Cheese
Name: food, dtype: object
Одновременный выбор с метками и целочисленным расположением
.ix использовался, чтобы делать выборки одновременно с метками и целочисленным местоположением, что было полезно, но иногда сбивало с толку и неоднозначно, и, к счастью, это устарело. В случае, если вам нужно сделать выборку с сочетанием меток и целочисленных местоположений, вы должны будете сделать как метки выбора, так и целочисленные местоположения.
Например, если мы хотим выбрать строки Nick а также Cornelia вместе со столбцами 2 и 4 мы могли бы использовать .loc путем преобразования целых чисел в метки со следующим:
col_names = df.columns[[2, 4]]
df.loc[['Nick', 'Cornelia'], col_names]
Или же, преобразуйте метки индекса в целые числа с помощью get_loc индексный метод.
labels = ['Nick', 'Cornelia']
index_ints = [df.index.get_loc(label) for label in labels]
df.iloc[index_ints, [2, 4]]
Логическое выделение
Индексатор.loc также может выполнять логический выбор. Например, если мы заинтересованы в поиске всех строк, где возраст старше 30 лет, и возвращаем только food а также score По столбцам мы можем сделать следующее:
df.loc[df['age'] > 30, ['food', 'score']]
Вы можете повторить это с .iloc но вы не можете передать это логическое число. Вы должны преобразовать логическую серию в массив numpy следующим образом:
df.iloc[(df['age'] > 30).values, [2, 4]]
Выбор всех строк
Можно использовать .loc/.iloc только для выбора столбца. Вы можете выбрать все строки, используя двоеточие, как это:
df.loc[:, 'color':'score':2]
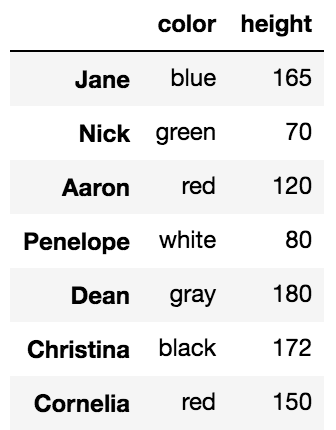
Оператор индексирования, [], может срезать можно выбрать строки и столбцы тоже, но не одновременно.
Большинству людей знакомо основное назначение оператора индексации DataFrame - выбор столбцов. Строка выбирает один столбец в качестве Серии, а список строк выбирает несколько столбцов в качестве DataFrame.
df['food']
Jane Steak
Nick Lamb
Aaron Mango
Penelope Apple
Dean Cheese
Christina Melon
Cornelia Beans
Name: food, dtype: object
Использование списка выбирает несколько столбцов
df[['food', 'score']]
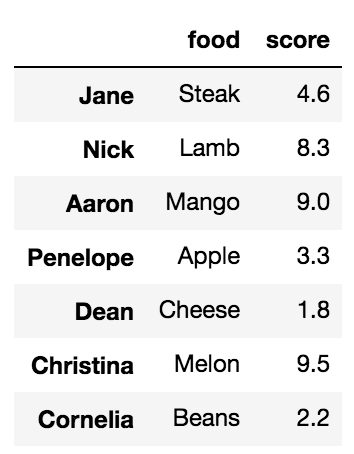
Люди менее знакомы с тем, что при использовании обозначения среза выбор происходит по меткам строк или по целочисленному расположению. Это очень сбивает с толку и то, что я почти никогда не использую, но это работает.
df['Penelope':'Christina'] # slice rows by label
df[2:6:2] # slice rows by integer location

Явность .loc/.iloc для выбора строк весьма предпочтителен. Один оператор индексирования не может одновременно выбирать строки и столбцы.
df[3:5, 'color']
TypeError: unhashable type: 'slice'
Выбор по .at а также .iat
Выбор с .at почти идентичен .loc но он выбирает только одну "ячейку" в вашем DataFrame. Мы обычно называем эту ячейку скалярным значением. Использовать .loc, передайте метку строки и столбца через запятую.
df.at['Christina', 'color']
'black'
Выбор с .iat почти идентичен .iloc но он выбирает только одно скалярное значение. Вы должны передать ему целое число как для строк, так и для столбцов
df.iat[2, 5]
'FL'
df = pd.DataFrame({'A':['a', 'b', 'c'], 'B':[54, 67, 89]}, index=[100, 200, 300])
df
A B
100 a 54
200 b 67
300 c 89
In [19]:
df.loc[100]
Out[19]:
A a
B 54
Name: 100, dtype: object
In [20]:
df.iloc[0]
Out[20]:
A a
B 54
Name: 100, dtype: object
In [24]:
df2 = df.set_index([df.index,'A'])
df2
Out[24]:
B
A
100 a 54
200 b 67
300 c 89
In [25]:
df2.ix[100, 'a']
Out[25]:
B 54
Name: (100, a), dtype: int64
Давайте начнем с этого небольшого df:
import pandas as pd
import time as tm
import numpy as np
n=10
a=np.arange(0,n**2)
df=pd.DataFrame(a.reshape(n,n))
У нас так будет
df
Out[25]:
0 1 2 3 4 5 6 7 8 9
0 0 1 2 3 4 5 6 7 8 9
1 10 11 12 13 14 15 16 17 18 19
2 20 21 22 23 24 25 26 27 28 29
3 30 31 32 33 34 35 36 37 38 39
4 40 41 42 43 44 45 46 47 48 49
5 50 51 52 53 54 55 56 57 58 59
6 60 61 62 63 64 65 66 67 68 69
7 70 71 72 73 74 75 76 77 78 79
8 80 81 82 83 84 85 86 87 88 89
9 90 91 92 93 94 95 96 97 98 99
С этим мы имеем:
df.iloc[3,3]
Out[33]: 33
df.iat[3,3]
Out[34]: 33
df.iloc[:3,:3]
Out[35]:
0 1 2 3
0 0 1 2 3
1 10 11 12 13
2 20 21 22 23
3 30 31 32 33
df.iat[:3,:3]
Traceback (most recent call last):
... omissis ...
ValueError: At based indexing on an integer index can only have integer indexers
Таким образом, мы не можем использовать.iat для подмножества, где мы должны использовать только.iloc.
Но давайте попробуем оба выбрать больший df и проверим скорость...
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 7 09:58:39 2018
@author: Fabio Pomi
"""
import pandas as pd
import time as tm
import numpy as np
n=1000
a=np.arange(0,n**2)
df=pd.DataFrame(a.reshape(n,n))
t1=tm.time()
for j in df.index:
for i in df.columns:
a=df.iloc[j,i]
t2=tm.time()
for j in df.index:
for i in df.columns:
a=df.iat[j,i]
t3=tm.time()
loc=t2-t1
at=t3-t2
prc = loc/at *100
print('\nloc:%f at:%f prc:%f' %(loc,at,prc))
loc:10.485600 at:7.395423 prc:141.784987
Таким образом, с помощью.loc мы можем управлять подмножествами, а с помощью.at - только одним скаляром, но.at быстрее, чем.loc.
:-)
Следует отметить, что просто для доступа к столбцу
.loc примерно в 7-10 раз медленнее, чем
[]:
Тестовый сценарий:
import os
import sys
from timeit import timeit
import numpy as np
import pandas as pd
def setup():
arr = np.arange(0, 10 ** 2)
return pd.DataFrame(arr.reshape(10, 10))
if __name__ == "__main__":
print(f"Python: {sys.version}")
print(f"Numpy: {np.__version__}")
print(f"Pandas: {pd.__version__}")
iters = 10000
print(
"[] Method:",
timeit(
"data = df[0]",
setup="from __main__ import setup; df = setup()",
number=iters,
),
)
print(
".loc() Method:",
timeit(
"data = df.loc[:, 0]",
setup="from __main__ import setup; df = setup()",
number=iters,
),
)
Выход:
Python: 3.8.10 (tags/v3.8.10:3d8993a, May 3 2021, 11:48:03) [MSC v.1928 64 bit (AMD64)]
Numpy: 1.21.1
Pandas: 1.3.3
[] Method: 0.0923579000000001
.loc() Method: 0.6762988000000001