YoloV4 Custom Dataset Train Test Split
Я пытаюсь обучить Yolo Net с помощью своего пользовательского набора данных. У меня есть изображения (*.jpg) и метки / аннотации в формате yolo в виде txt-файла.
Теперь я хочу разделить данные на набор для поезда и проверки. В результате мне нужен поезд и папка проверки, каждая со своими изображениями и аннотациями.
Я пробовал что-то вроде этого:
from sklearn.model_selection import train_test_split
import glob
# Get all paths to your images files and text files
PATH = '../TrainingsData/'
img_paths = glob.glob(PATH+'*.jpg')
txt_paths = glob.glob(PATH+'*.txt')
X_train, X_test, y_train, y_test = train_test_split(img_paths, txt_paths, test_size=0.3, random_state=42)
После сохранения набора в новую папку изображения и аннотации перепутались. Так, например, в папке поезда у некоторых изображений не было аннотаций (они были в папке проверки), и были некоторые аннотации, но изображение отсутствовало.
Можете ли вы помочь мне разделить мой набор данных?
6 ответов
Хорошо !!, ты можешь это сделать
Функция разделения изображений
def split_img_label(data_train,data_test,folder_train,foler_test):
os.mkdir(folder_train)
os.mkdir(folder_test)
train_ind=list(data_train.index)
test_ind=list(data_test.index)
# Train folder
for i in tqdm(range(len(train_ind))):
os.system('cp '+data_train[train_ind[i]]+' ./'+ folder_train + '/' +data_train[train_ind[i]].split('/')[2])
os.system('cp '+data_train[train_ind[i]].split('.jpg')[0]+'.txt'+' ./'+ folder_train + '/' +data_train[train_ind[i]].split('/')[2].split('.jpg')[0]+'.txt')
# Test folder
for j in tqdm(range(len(test_ind))):
os.system('cp '+data_test[test_ind[j]]+' ./'+ folder_test + '/' +data_test[test_ind[j]].split('/')[2])
os.system('cp '+data_test[test_ind[j]].split('.jpg')[0]+'.txt'+' ./'+ folder_test + '/' +data_test[test_ind[j]].split('/')[2].split('.jpg')[0]+'.txt')
КОД
import pandas as pd
import os
PATH = './TrainingsData/'
list_img=[img for img in os.listdir(PATH) if img.endswith('.jpg')==True]
list_txt=[img for img in os.listdir(PATH) if img.endswith('.txt')==True]
path_img=[]
for i in range (len(list_img)):
path_img.append(PATH+list_img[i])
df=pd.DataFrame(path_img)
# split
data_train, data_test, labels_train, labels_test = train_test_split(df[0], df.index, test_size=0.20, random_state=42)
# Function split
split_img_label(data_train,data_test,folder_train_name,folder_test_name)
ВЫХОД
len(list_img)
583
100%|████████████████████████████████████████████████████████████████████████████████| 466/466 [00:26<00:00, 17.42it/s]
100%|████████████████████████████████████████████████████████████████████████████████| 117/117 [00:07<00:00, 16.61it/s]
Наконец, у вас будет 2 папки ( имя_поездки_папки, имя_теста_папки ) с одинаковыми изображениями и метками.
import glob
import random
import os
filelist = glob.glob('train/*.txt')
test = random.sample(filelist, int(len(filelist)*0.15))
output_path = 'test/'
if not os.path.exists(output_path):
os.makedirs(output_path)
for file in test:
txtpath = file
impath = file[:-4] + '.jpg'
out_text = os.path.join(output_path, os.path.basename(txtpath))
out_image = os.path.join(output_path, os.path.basename(impath))
print(txtpath,impath,out_text,out_image)
os.system('powershell mv ' + txtpath + ' ' + out_text)
os.system('powershell mv ' + impath + ' ' + out_image)
Задайте пути к папкам train и test. Установите процент изображений, которые будут отправлены для тестирования.
Заменить
powershell mv команда только с
mv если не используете Windows.
user10435046 Вы можете использовать тот же код, что и выше, но вам просто нужно добавить и изменить следующие строки
def split_img_label_2(data_train,data_test,folder_train,folder_test):
#os.mkdir(folder_train)
#os.mkdir(folder_test)
train_ind=list(data_train.index)
test_ind=list(data_test.index)
# Train folder
for i in tqdm(range(len(train_ind))):
os.system('cp '+data_train[train_ind[i]]+' ./'+ folder_train + '/' +data_train[train_ind[i]].split('/')[2])
os.system('cp '+data_train[train_ind[i]].split('.jpg')[0]+'.txt'+' ./'+ folder_train + '/' +data_train[train_ind[i]].split('/')[2].split('.jpg')[0]+'.txt')
# Test folder
for j in tqdm(range(len(test_ind))):
os.system('cp '+data_test[test_ind[j]]+' ./'+ folder_test + '/' +data_test[test_ind[j]].split('/')[2])
os.system('cp '+data_test[test_ind[j]].split('.jpg')[0]+'.txt'+' ./'+ folder_test + '/' +data_test[test_ind[j]].split('/')[2].split('.jpg')[0]+'.txt')
os.mkdir(folder_train)
os.mkdir(folder_test)
list_folder = [folder1,folder2,.........folder40]
for folder_name in list_folder :
PATH = 'folder_name' # pass the right path
list_img=[img for img in os.listdir(PATH) if img.endswith('.jpg')==True]
list_txt=[img for img in os.listdir(PATH) if img.endswith('.txt')==True]
path_img=[]
for i in range (len(list_img)):
path_img.append(PATH+list_img[i])
df=pd.DataFrame(path_img)
# split
data_train, data_test, labels_train, labels_test = train_test_split(df[0],
df.index, test_size=0.20, random_state=42)
# Function split
split_img_label_2(data_train,data_test,folder_train_name,folder_test_name)
ПРИМЕЧАНИЕ. Помните, что имя_папки_поезда и имя_папки_теста будут одинаковыми для всех процессов, чтобы получить уникальную конечную папку со всеми изображениями.
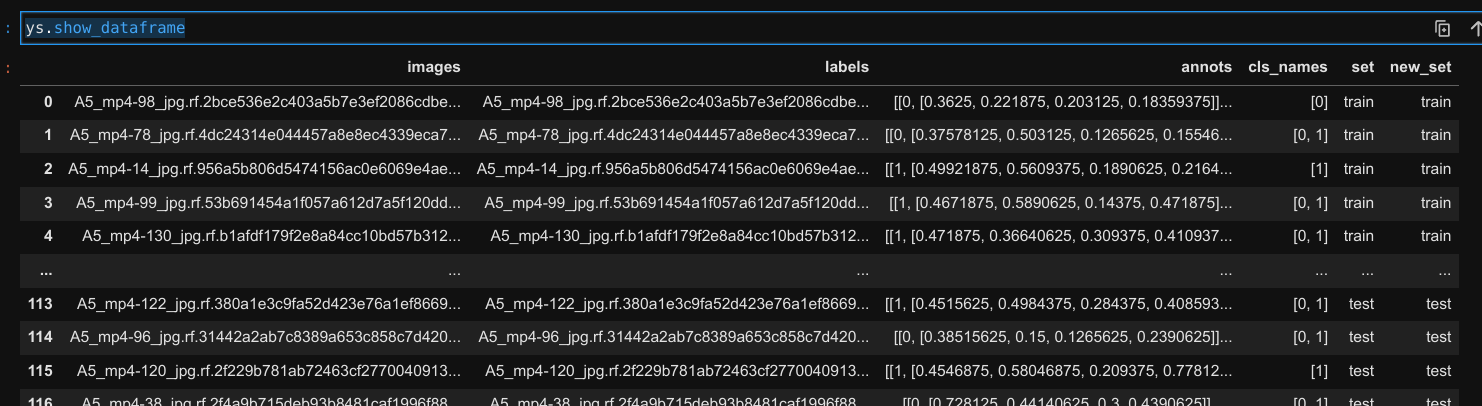
Чтобы разделить набор данных в формат набора данных YOLO, вы можете использовать YoloSplitter. YoloSplitter — это инструмент для создания и изменения наборов данных формата YOLO. Он также отображает всю информацию о проекте в кадре данных. С первого взгляда вы можете увидеть, сколько классов содержится в одном изображении, и можете использовать столбец аннотаций фрейма данных для рисования аннотаций к изображениям. Кроме того, у вас есть возможность разделить новый набор данных в указанном соотношении. Дополнительно также создаетсяdata.yamlфайл.
pip install yolosplitter
# pip install yolosplitter
from yolosplitter import YoloSplitter
ys = YoloSplitter(imgFormat=['.jpg', '.jpeg', '.png'], labelFormat=['.txt'] )
# If you have yolo-format dataset already on the system
# ratio=(train,val,test)
df = ys.from_yolo_dir(input_dir="yolo_dataset",ratio=(0.7,0.2,0.1))
# If you have mixed Images and Labels in the same directory
# ratio=(train,val,test)
df = ys.from_mixed_dir(input_dir="mydataset",ratio=(0.7,0.2,0.1))
# To save dataset with 'data.yaml' file
ys.save_split(output_dir="potholes")
# show dataframe
ys.show_dataframe
# show files which have error
ys.show_errors
Dataframe
# Saving New dataset
ys.save_split(output_dir="potholes")
Saving New split in 'potholes' dir
100%|██████████| 118/118 [00:00<00:00, 1352.79it/s]
Если вы хотите разделить изображения и метки, чтобы обучить собственную модель, я рекомендую следующие шаги:
- Создать
objпапка с изображениями и этикетками. - Создайте и запустите
generate_train.pyСценарий
#generate_train.py
import os
image_files = []
os.chdir(os.path.join("data", "obj"))
for filename in os.listdir(os.getcwd()):
if filename.endswith(".jpg"):
image_files.append("data/obj/" + filename)
os.chdir("..")
with open("train.txt", "w") as outfile:
for image in image_files:
outfile.write(image)
outfile.write("\n")
outfile.close()
os.chdir("..")
- Наконец, когда у вас есть
train.txtфайл, вы можете запустить приведенный ниже код:
df=pd.read_csv('PATH/data/train.txt',header=None)
# sklearn split 80 train, 20 test
data_train, data_test, labels_train, labels_test = train_test_split(df[0], df.index, test_size=0.20, random_state=42)
# train.txt contain the PATH of images and label to train
data_train=data_train.reset_index()
data_train=data_train.drop(columns='index')
with open("train.txt", "w") as outfile:
for ruta in data_train[0]:
outfile.write(ruta)
outfile.write("\n")
outfile.close()
# test.txt contain the PATH of images and label to test
data_test=data_test.reset_index()
data_test=data_test.drop(columns='index')
with open("test.txt", "w") as outfile:
for ruta in data_test[0]:
outfile.write(ruta)
outfile.write("\n")
outfile.close()
Теперь вы готовы обучать свою модель.
ЙОЛО
!./darknet detector train data/obj.data cfg/yolov4-FENO.cfg yolov4.conv.137 -dont_show -map
КРОШЕЧНЫЙ
!./darknet detector train data/obj.data cfg/yolov4_tiny.cfg yolov4-tiny.conv.29 -dont_show -map
Разделение наборов данных изображений является сложной задачей, потому что, как вы обнаружили, если вы не сделаете это правильно, вы получите аннотации и изображения в отдельных папках.
У меня была такая же проблема при работе с аннотациями Yolo, и в итоге я создал пакет Python под названием PyLabel, чтобы сделать это в качестве школьного проекта.
У меня есть образец блокнота, чтобы продемонстрировать, как разбить набор данных на 2 или 3 группы здесь https://github.com/pylabel-project/samples/blob/main/dataset_splitting.ipynb.
При использовании PyLabel код будет примерно таким:
dataset = importer.ImportYoloV5(path_to_annotations)
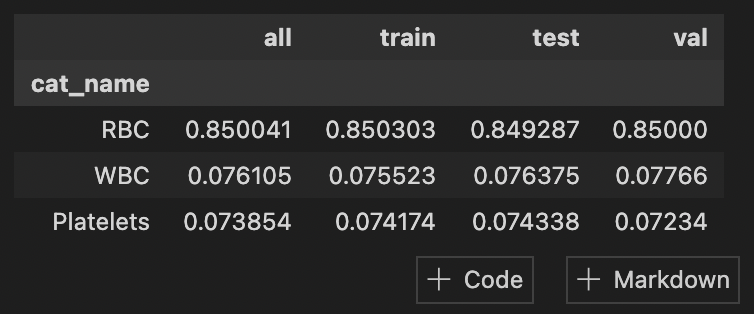
dataset.splitter.StratifiedGroupShuffleSplit(train_pct=.6, val_pct=.2, test_pct=.2, batch_size=1)
dataset.analyze.ShowClassSplits()
ShowClassSplits предоставит следующий вывод, чтобы вы могли проверить, сбалансированы ли разделения.
PyLabel имеет 2 метода разделения данных:
- GroupShuffleSplit , который использует команду GroupShuffleSplit из sklearn.
- StratifiedGroupShuffleSplit , который пытается сбалансировать распределение классов равномерно по разделенным группам.
Надеюсь, это поможет любому, кто читает это. Если у вас возникнут какие-либо проблемы, не стесняйтесь обращаться ко мне, и я могу помочь.