CNN регулярно теряет тренировки в конце эпохи
Я тренирую CNN в PyTorch с Адамом, и начальная скорость обучения составляет 1e-5. У меня есть 5039 выборок в мою эпоху, а размер пакета равен 1. Я заметил, что у меня есть регулярный всплеск потерь при обучении в конце эпохи. Вот график потери тренировки:
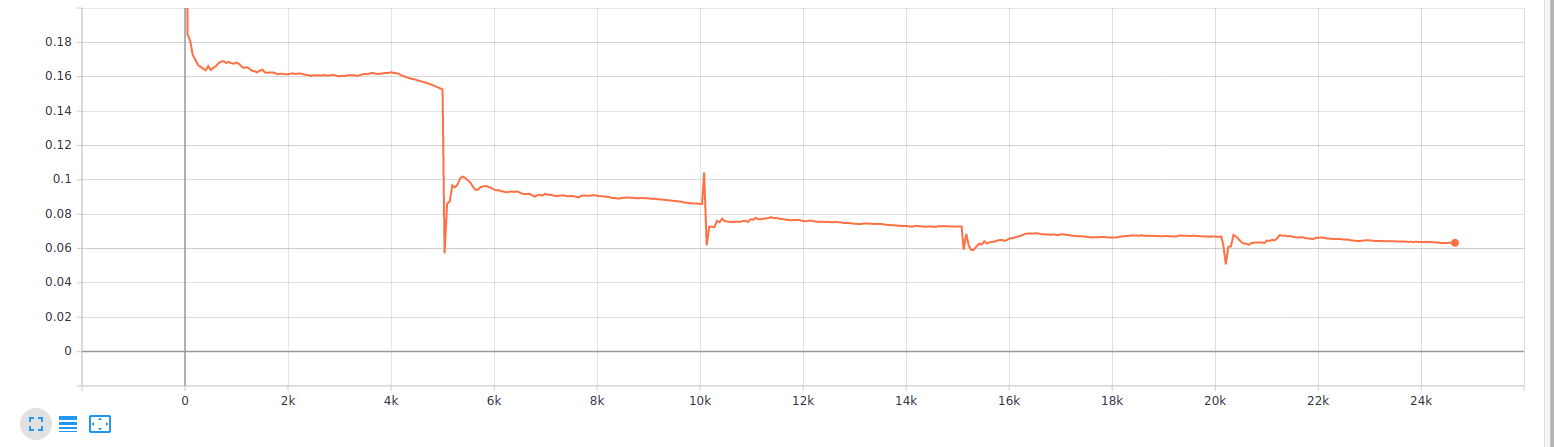
По сюжету отчетливо виден стук всплесков, которые происходят как раз в конце эпохи. Моя эпоха насчитывает 5039 образцов. Что интересно, шипы не только стреляют, но иногда и поднимаются.
Я не думаю, что это:
Эти всплески можно было бы объяснить, если бы не перетасовать набор данных. Однако я перетасовываю свой набор данных каждую эпоху.
Такое поведение, как известно, происходит, когда последняя партия эпохи меньше, чем другие партии, что приводит к разной величине потерь ( почему мои потери в тренировках имеют регулярные пики?) Однако это не мой случай, поскольку размер моей партии равен 1.
Одним из возможных способов взлома может быть применение отсечения градиента перед этапом обновления. Однако это не кажется мне хорошим способом решения этой проблемы.
- Что вы думаете о причинах этой модели всплесков?
- Насколько плохо иметь такой узор?
1 ответ
Две возможности, о которых я могу думать:
- Метод регистрации потерь, который сбрасывает каждую эпоху.
- Небольшой набор данных.
Одна возможность: способ, которым вы регистрируете потери. Если, например, вы накапливаете потери на каждом этапе, регистрируете среднее значение и сбрасываете потери в конце эпохи, то первые партии могут влиять на ваши потери в конце эпохи. Если обнулить счетчик потерь в конце эпохи, то можно было увидеть скачок производительности.
all_losses = []
for e in range(epochs):
epoch_losses = [] # <- jump in performance when you discard earlier losses
for i, batch in enumerate(data_loader):
batch_loss = ...
epoch_losses.append(batch_loss)
all_losses.append(np.mean(epoch_losses))
plot(losses)
Другая возможность заключается в том, что ваш набор данных настолько мал, что в начале каждой эпохи наблюдается заметный скачок производительности, потому что у вас есть целая партия элементов, которые вы теперь видели один дополнительный раз. С большими наборами данных в процессе обучения больше шума (более поздние партии отменяют прогресс, достигнутый в первых партиях), поэтому вы не видите этого скачка.