TFoS (TensorFLowOnSpark)- не удается запустить классификацию изображений на искровом кластере в режиме пряжи с использованием распределения hdp
Я пытался запустить скрипт классификации изображений, опубликованный и управляемый Yahoo по этой ссылке на github. https://github.com/yahoo/TensorFlowOnSpark/tree/master/examples/slim
Я пошёл по этой https://github.com/yahoo/TensorFlowOnSpark/blob/master/examples/slim/README.md шаг за шагом, чтобы обучить модель.
Для обучения начальной модели используется только набор из 25 изображений цветов. И набор данных присутствует на hdfs.
Среда: - все процессорные машины CentOS с 3 узлами, имеющие одинаковую версию: - объем ОЗУ CentOS Linux версии 7.2.1511 (Core) на каждой машине: 16 ГБ число ядер на каждой машине: 6 тензорный поток: 1.4.0 тензорный поток 1.3.0 python:- 2.7.5 Java: 1.8 hadoop:- Распределение Hadoop 2.7.3: hdp cuda: N/A GPU:- N/A spark: 2.2.0
вот команда командной строки spark-submit, с которой я начал сначала, прежде чем поиграть с несколькими другими комбинациями свойств, о которых я расскажу позже в этом посте..
${SPARK_HOME}/bin/spark-submit --master yarn --deploy-mode cluster \
--queue default \
--num-executors 3 \
--executor-memory 4G \
--executor-cores 1 \
--py-files slim.zip \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.yarn.maxAppAttempts=1 \
--conf spark.yarn.executor.memoryOverhead=4096 \
--conf spark.ui.view.acls=* \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=/usr/bin/python \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/hdp/2.6.3.0-235/usr/lib:$JAVA_HOME/jre/lib/amd64/server" \
--conf spark.executorEnv.CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath --glob):${CLASSPATH} \
--conf spark.executorEnv.HADOOP_HDFS_HOME=/usr/hdp/current/hadoop-hdfs-client \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/hdp/2.6.3.0-235/usr/lib/libhdfs.so:/usr/hdp/2.6.3.0-235/usr/lib:${JAVA_HOME}/jre/lib/amd64/server" \
${TFoS_HOME}/examples/slim/train_image_classifier.py \
--dataset_dir hdfs://172.26.32.32:8020/user/mapr/inception/dataset \
--train_dir hdfs://172.26.32.32:8020/user/mapr/slim_train \
--dataset_name flowers \
--dataset_split_name train \
--model_name inception_v3 \
--max_number_of_steps 1000 \
--batch_size 32 \
--num_ps_tasks 1
Вот контейнерные логи (stderr):
18/05/16 00:43:52 INFO RMProxy: Connecting to ResourceManager at impetus-i0057.impetus.co.in/172.26.32.36:8030
18/05/16 00:43:52 INFO YarnRMClient: Registering the ApplicationMaster
18/05/16 00:43:52 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark://YarnAM@172.26.32.37:45684)
18/05/16 00:43:52 INFO YarnAllocator: Will request 3 executor container(s), each with 1 core(s) and 8192 MB memory (including 4096 MB of overhead)
18/05/16 00:43:52 INFO YarnAllocator: Submitted 3 unlocalized container requests.
18/05/16 00:43:52 INFO ApplicationMaster: Started progress reporter thread with (heartbeat : 3000, initial allocation : 200) intervals
18/05/16 00:43:52 INFO AMRMClientImpl: Received new token for : impetus-i0057.impetus.co.in:45454
18/05/16 00:43:52 INFO AMRMClientImpl: Received new token for : impetus-i0053.impetus.co.in:45454
18/05/16 00:43:52 INFO YarnAllocator: Launching container container_1525710710928_0087_01_000002 on host impetus-i0057.impetus.co.in for executor with ID 1
18/05/16 00:43:52 INFO YarnAllocator: Launching container container_1525710710928_0087_01_000003 on host impetus-i0053.impetus.co.in for executor with ID 2
18/05/16 00:43:52 INFO YarnAllocator: Received 2 containers from YARN, launching executors on 2 of them.
18/05/16 00:43:52 INFO ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0
18/05/16 00:43:52 INFO ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0
18/05/16 00:43:52 INFO ContainerManagementProtocolProxy: Opening proxy : impetus-i0053.impetus.co.in:45454
18/05/16 00:43:52 INFO ContainerManagementProtocolProxy: Opening proxy : impetus-i0057.impetus.co.in:45454
18/05/16 00:43:53 INFO AMRMClientImpl: Received new token for : impetus-i0058.impetus.co.in:45454
18/05/16 00:43:53 INFO YarnAllocator: Launching container container_1525710710928_0087_01_000004 on host impetus-i0058.impetus.co.in for executor with ID 3
18/05/16 00:43:53 INFO YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
18/05/16 00:43:53 INFO ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0
18/05/16 00:43:53 INFO ContainerManagementProtocolProxy: Opening proxy : impetus-i0058.impetus.co.in:45454
18/05/16 00:43:56 INFO YarnAllocator: Received 1 containers from YARN, launching executors on 0 of them.
18/05/16 00:43:56 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.26.32.36:28535) with ID 1
18/05/16 00:43:56 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.26.32.32:46038) with ID 2
18/05/16 00:43:56 INFO BlockManagerMasterEndpoint: Registering block manager impetus-i0057.impetus.co.in:28782 with 2004.6 MB RAM, BlockManagerId(1, impetus-i0057.impetus.co.in, 28782, None)
18/05/16 00:43:56 INFO BlockManagerMasterEndpoint: Registering block manager impetus-i0053.impetus.co.in:35126 with 2004.6 MB RAM, BlockManagerId(2, impetus-i0053.impetus.co.in, 35126, None)
18/05/16 00:43:57 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.26.32.37:36394) with ID 3
18/05/16 00:43:57 INFO YarnClusterSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
18/05/16 00:43:57 INFO YarnClusterScheduler: YarnClusterScheduler.postStartHook done
18/05/16 00:43:57 INFO BlockManagerMasterEndpoint: Registering block manager impetus-i0058.impetus.co.in:39780 with 2004.6 MB RAM, BlockManagerId(3, impetus-i0058.impetus.co.in, 39780, None)
18/05/16 00:43:57 INFO SparkContext: Starting job: foreachPartition at /usr/lib/python2.7/site-packages/tensorflowonspark/TFCluster.py:293
18/05/16 00:43:57 INFO DAGScheduler: Got job 0 (foreachPartition at /usr/lib/python2.7/site-packages/tensorflowonspark/TFCluster.py:293) with 3 output partitions
18/05/16 00:43:57 INFO DAGScheduler: Final stage: ResultStage 0 (foreachPartition at /usr/lib/python2.7/site-packages/tensorflowonspark/TFCluster.py:293)
18/05/16 00:43:57 INFO DAGScheduler: Parents of final stage: List()
18/05/16 00:43:57 INFO DAGScheduler: Missing parents: List()
18/05/16 00:43:57 INFO DAGScheduler: Submitting ResultStage 0 (PythonRDD[1] at foreachPartition at /usr/lib/python2.7/site-packages/tensorflowonspark/TFCluster.py:293), which has no missing parents
18/05/16 00:43:58 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 54.5 KB, free 366.2 MB)
18/05/16 00:43:58 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 24.4 KB, free 366.2 MB)
18/05/16 00:43:58 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 172.26.32.37:45828 (size: 24.4 KB, free: 366.3 MB)
18/05/16 00:43:58 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006
18/05/16 00:43:58 INFO DAGScheduler: Submitting 3 missing tasks from ResultStage 0 (PythonRDD[1] at foreachPartition at /usr/lib/python2.7/site-packages/tensorflowonspark/TFCluster.py:293) (first 15 tasks are for partitions Vector(0, 1, 2))
18/05/16 00:43:58 INFO YarnClusterScheduler: Adding task set 0.0 with 3 tasks
18/05/16 00:43:58 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, impetus-i0058.impetus.co.in, executor 3, partition 0, PROCESS_LOCAL, 4819 bytes)
18/05/16 00:43:58 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, impetus-i0057.impetus.co.in, executor 1, partition 1, PROCESS_LOCAL, 4819 bytes)
18/05/16 00:43:58 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, impetus-i0053.impetus.co.in, executor 2, partition 2, PROCESS_LOCAL, 4819 bytes)
18/05/16 00:43:58 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on impetus-i0057.impetus.co.in:28782 (size: 24.4 KB, free: 2004.6 MB)
18/05/16 00:43:58 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on impetus-i0058.impetus.co.in:39780 (size: 24.4 KB, free: 2004.6 MB)
18/05/16 00:43:58 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on impetus-i0053.impetus.co.in:35126 (size: 24.4 KB, free: 2004.6 MB)
18/05/16 00:46:24 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 1.
18/05/16 00:46:24 INFO DAGScheduler: Executor lost: 1 (epoch 0)
18/05/16 00:46:24 INFO BlockManagerMasterEndpoint: Trying to remove executor 1 from BlockManagerMaster.
18/05/16 00:46:24 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(1, impetus-i0057.impetus.co.in, 28782, None)
18/05/16 00:46:24 INFO BlockManagerMaster: Removed 1 successfully in removeExecutor
18/05/16 00:46:24 INFO DAGScheduler: Shuffle files lost for executor: 1 (epoch 0)
18/05/16 00:46:24 INFO YarnAllocator: Completed container container_1525710710928_0087_01_000002 on host: impetus-i0057.impetus.co.in (state: COMPLETE, exit status: -104)
18/05/16 00:46:24 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 8.3 GB of 8 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/05/16 00:46:24 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 8.3 GB of 8 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/05/16 00:46:24 ERROR YarnClusterScheduler: Lost executor 1 on impetus-i0057.impetus.co.in: Container killed by YARN for exceeding memory limits. 8.3 GB of 8 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/05/16 00:46:24 WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, impetus-i0057.impetus.co.in, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 8.3 GB of 8 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/05/16 00:46:24 INFO BlockManagerMasterEndpoint: Trying to remove executor 1 from BlockManagerMaster.
18/05/16 00:46:24 INFO BlockManagerMaster: Removal of executor 1 requested
18/05/16 00:46:24 INFO YarnSchedulerBackend$YarnDriverEndpoint: Asked to remove non-existent executor 1
18/05/16 00:46:27 INFO YarnAllocator: Will request 1 executor container(s), each with 1 core(s) and 8192 MB memory (including 4096 MB of overhead)
18/05/16 00:46:27 INFO YarnAllocator: Submitted 1 unlocalized container requests.
18/05/16 00:46:28 INFO YarnAllocator: Launching container container_1525710710928_0087_01_000007 on host impetus-i0057.impetus.co.in for executor with ID 4
18/05/16 00:46:28 INFO YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
18/05/16 00:46:28 INFO ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0
18/05/16 00:46:28 INFO ContainerManagementProtocolProxy: Opening proxy : impetus-i0057.impetus.co.in:45454
18/05/16 00:46:32 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.26.32.36:29852) with ID 4
18/05/16 00:46:32 INFO TaskSetManager: Starting task 1.1 in stage 0.0 (TID 3, impetus-i0057.impetus.co.in, executor 4, partition 1, PROCESS_LOCAL, 4819 bytes)
18/05/16 00:46:33 INFO BlockManagerMasterEndpoint: Registering block manager impetus-i0057.impetus.co.in:65131 with 2004.6 MB RAM, BlockManagerId(4, impetus-i0057.impetus.co.in, 65131, None)
18/05/16 00:46:34 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on impetus-i0057.impetus.co.in:65131 (size: 24.4 KB, free: 2004.6 MB)
18/05/16 00:46:42 WARN TaskSetManager: Lost task 2.0 in stage 0.0 (TID 2, impetus-i0053.impetus.co.in, executor 2): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/hadoop/yarn/local/usercache/mapr/appcache/application_1525710710928_0087/container_1525710710928_0087_01_000003/pyspark.zip/pyspark/worker.py", line 177, in main
process()
File "/hadoop/yarn/local/usercache/mapr/appcache/application_1525710710928_0087/container_1525710710928_0087_01_000003/pyspark.zip/pyspark/worker.py", line 172, in process
serializer.dump_stream(func(split_index, iterator), outfile)
File "/hadoop/yarn/local/usercache/mapr/appcache/application_1525710710928_0087/container_1525710710928_0087_01_000001/pyspark.zip/pyspark/rdd.py", line 2423, in pipeline_func
File "/hadoop/yarn/local/usercache/mapr/appcache/application_1525710710928_0087/container_1525710710928_0087_01_000001/pyspark.zip/pyspark/rdd.py", line 2423, in pipeline_func
File "/hadoop/yarn/local/usercache/mapr/appcache/application_1525710710928_0087/container_1525710710928_0087_01_000001/pyspark.zip/pyspark/rdd.py", line 2423, in pipeline_func
File "/hadoop/yarn/local/usercache/mapr/appcache/application_1525710710928_0087/container_1525710710928_0087_01_000001/pyspark.zip/pyspark/rdd.py", line 346, in func
File "/hadoop/yarn/local/usercache/mapr/appcache/application_1525710710928_0087/container_1525710710928_0087_01_000001/pyspark.zip/pyspark/rdd.py", line 794, in func
File "/usr/lib/python2.7/site-packages/tensorflowonspark/TFSparkNode.py", line 353, in _mapfn
wrapper_fn(tf_args, ctx)
File "/usr/lib/python2.7/site-packages/tensorflowonspark/TFSparkNode.py", line 310, in wrapper_fn
fn(args, context)
File "train_image_classifier.py", line 606, in main_fun
File "/usr/lib/python2.7/site-packages/tensorflow/contrib/slim/python/slim/learning.py", line 775, in train
sv.stop(threads, close_summary_writer=True)
File "/usr/lib64/python2.7/contextlib.py", line 35, in __exit__
self.gen.throw(type, value, traceback)
File "/usr/lib/python2.7/site-packages/tensorflow/python/training/supervisor.py", line 964, in managed_session
self.stop(close_summary_writer=close_summary_writer)
File "/usr/lib/python2.7/site-packages/tensorflow/python/training/supervisor.py", line 792, in stop
stop_grace_period_secs=self._stop_grace_secs)
File "/usr/lib/python2.7/site-packages/tensorflow/python/training/coordinator.py", line 389, in join
six.reraise(*self._exc_info_to_raise)
File "/usr/lib/python2.7/site-packages/tensorflow/python/training/queue_runner_impl.py", line 238, in _run
enqueue_callable()
File "/usr/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 1231, in _single_operation_run
target_list_as_strings, status, None)
File "/usr/lib/python2.7/site-packages/tensorflow/python/framework/errors_impl.py", line 473, in __exit__
c_api.TF_GetCode(self.status.status))
UnavailableError: Endpoint read failed
at org.apache.spark.api.python.PythonRunner$$anon$1.read(PythonRDD.scala:193)
at org.apache.spark.api.python.PythonRunner$$anon$1.<init>(PythonRDD.scala:234)
at org.apache.spark.api.python.PythonRunner.compute(PythonRDD.scala:152)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:63)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:338)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
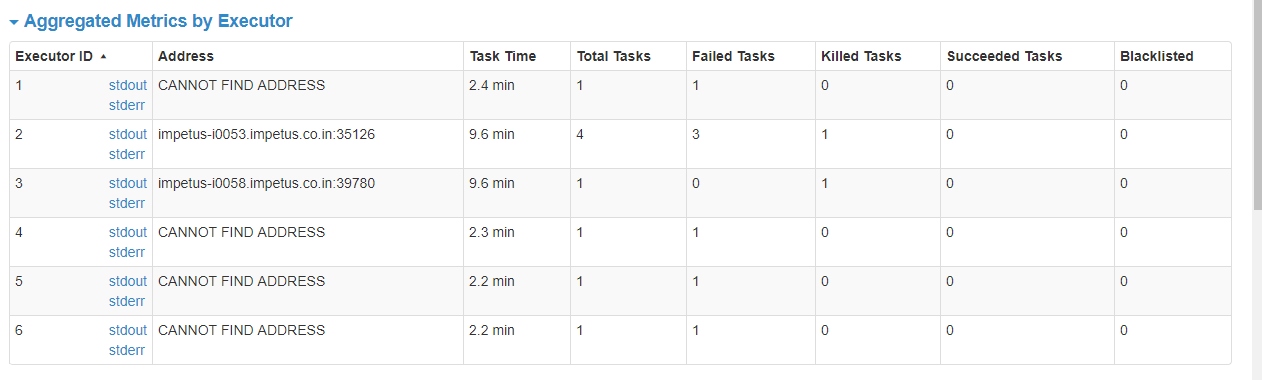
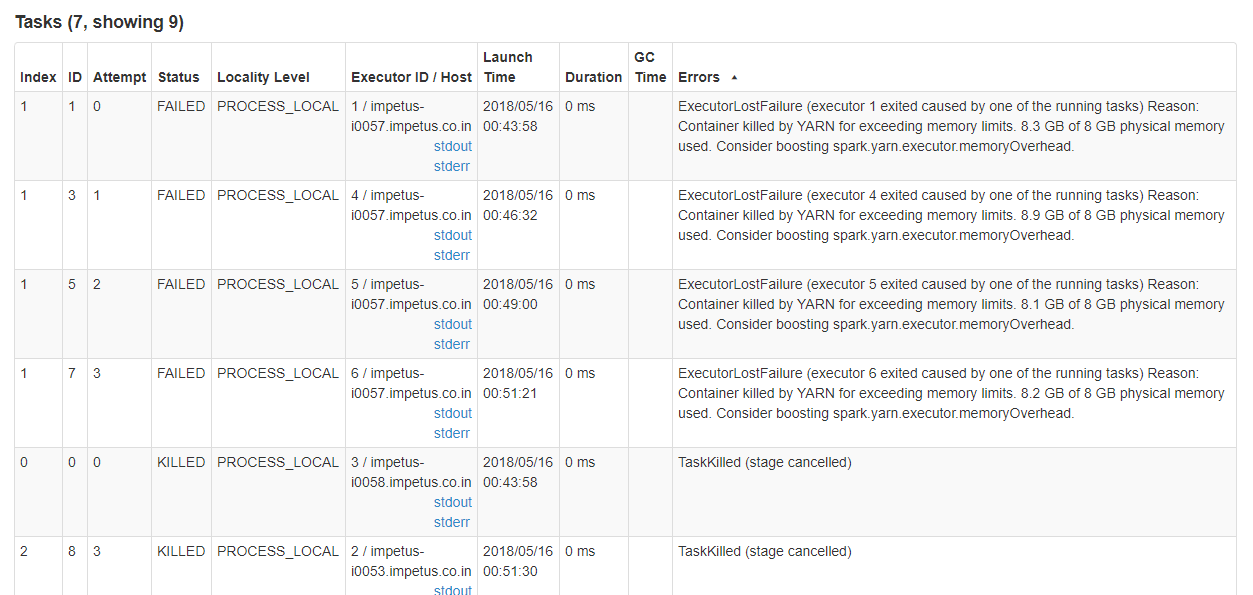
Я пробовал следующие свойства, но ни одно из них не работало до сих пор.. --conf spark.dynamicAllocation.enabled=true --conf spark.shuffle.service.enabled=true \
Я много играл с spark.yarn.executor.memoryOverhead, и я заметил, что чем больше я увеличиваю накладные расходы, тем дольше тренируется, но в конечном итоге он терпит неудачу. --conf spark.memory.fraction=0,8 --conf spark.memory.storageFraction=0,35 \
--conf spark.memory.offHeap.enabled = true --conf spark.memory.offHeap.size = 4096 \
Любое предложение будет заметно. Спасибо.!