регрессия с алгоритмом стохастического градиентного спуска
Я изучаю регрессию с помощью книги "Машинное обучение в действии", и я увидел источник, подобный приведенному ниже:
def stocGradAscent0(dataMatrix, classLabels):
m, n = np.shape(dataMatrix)
alpha = 0.01
weights = np.ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
Вы можете догадаться, что означает код. Но я этого не понимал. Я читал книгу несколько раз и искал похожие вещи, такие как wiki или google, где экспоненциальная функция используется для получения весов для минимальных различий. И почему мы получаем правильный вес, используя экспоненциальную функцию с суммой X* весов? Это было бы вроде OLS. В любом случае, мы получаем результат, как показано ниже:
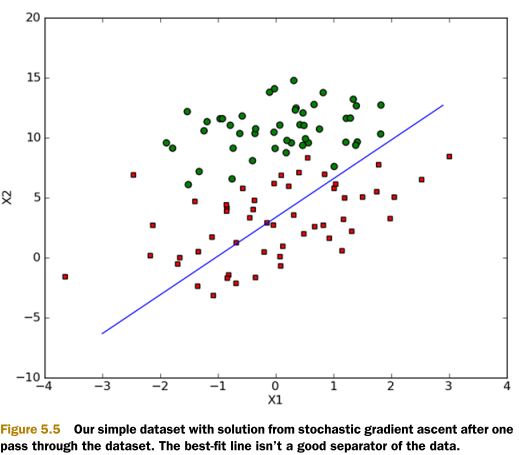
Благодарность!
1 ответ
Это просто основы линейной регрессии. В цикле for он пытается вычислить функцию ошибок
Z = ²â € + ²â ‚X; где ²â ‚AND X - матрицы
hΘ (x) = сигмоид (Z)
т.е. hΘ (x) = 1/(1 + e^-(²â ‚€ + ²â‚ X)
затем обновите веса. обычно лучше дать ему большое число для итераций в цикле for, например 1000, м, я думаю, это будет мало.
Я хочу объяснить больше, но я не могу объяснить лучше, чем этот чувак здесь
Удачного обучения!!