BERT Multi-class Sentiment Analysis получил низкую точность?
Я работаю над небольшим набором данных, который:
Содержит 1500 новостных статей.
Все эти статьи были оценены людьми с учетом их настроений / степени положительности по 5-балльной шкале.
Чистый с точки зрения орфографических ошибок. Я использовал лист Google для проверки орфографии перед импортом в анализ. Есть еще некоторые символы, которые неправильно закодированы, но их не так много.
Средняя длина превышает 512 слов.
слегка несбалансированный набор данных.
Я рассматриваю это как проблему классификации нескольких классов и хочу настроить BERT с помощью этого набора данных. Для этого я использовалKtrainпакет и в основном следует руководству. Ниже мой код:
(x_train, y_train), (x_test, y_test), preproc = text.texts_from_array(
x_train=x_train,
y_train=y_train,
x_test=x_test,
y_test=y_test,
class_names=categories,
preprocess_mode='bert',
maxlen= 510,
max_features=35000)
model = text.text_classifier('bert', train_data=(x_train, y_train), preproc=preproc)
learner = ktrain.get_learner(model, train_data=(x_train, y_train), batch_size=6)
learner.fit_onecycle(2e-5, 4)
Однако я получаю только точность проверки около 25%, что слишком мало.
precision-recall f1-score support
1 0.33 0.40 0.36 75
2 0.27 0.36 0.31 84
3 0.23 0.24 0.23 58
4 0.18 0.09 0.12 54
5 0.33 0.04 0.07 24
accuracy 0.27 295
macro avg 0.27 0.23 0.22 295
weighted avg 0.26 0.27 0.25 295
Я также пробовал стратегию усечения "голова + хвост", так как некоторые статьи довольно длинные, однако производительность осталась прежней.
Кто-нибудь может дать мне несколько предложений?
Большое спасибо!
Лучший
Сюй
================== Обновление 7.21=================
Следуя совету Картикея, я попробовал find_lr. Вот результат. Кажется, что 2e^-5 - разумная скорость обучения.
simulating training for different learning rates... this may take a few
moments...
Train on 1182 samples
Epoch 1/2
1182/1182 [==============================] - 223s 188ms/sample - loss: 1.6878
- accuracy: 0.2487
Epoch 2/2
432/1182 [=========>....................] - ETA: 2:12 - loss: 3.4780 -
accuracy: 0.2639
done.
Visually inspect loss plot and select learning rate associated with falling
loss
И я просто попытался запустить его с некоторым весом:
{0: 0,
1: 0.8294736842105264,
2: 0.6715909090909091,
3: 1.0844036697247708,
4: 1.1311004784688996,
5: 2.0033898305084747}
Вот результат. Немногое изменилось.
precision recall f1-score support
1 0.43 0.27 0.33 88
2 0.22 0.46 0.30 69
3 0.19 0.09 0.13 64
4 0.13 0.13 0.13 47
5 0.16 0.11 0.13 28
accuracy 0.24 296
macro avg 0.23 0.21 0.20 296
weighted avg 0.26 0.24 0.23 296
array([[24, 41, 9, 8, 6],
[13, 32, 6, 12, 6],
[ 9, 33, 6, 14, 2],
[ 4, 25, 10, 6, 2],
[ 6, 14, 0, 5, 3]])
============== обновление 7.22 =============
Чтобы получить некоторые базовые результаты, я сворачиваю задачу классификации по 5-балльной шкале в двоичную, которая предназначена только для прогнозирования положительного или отрицательного. На этот раз точность увеличилась примерно до 55%. Ниже приводится подробное описание моей стратегии:
training data: 956 samples (excluding those classified as neutural)
truncation strategy: use the first 128 and last 128 tokens
(x_train, y_train), (x_test, y_test), preproc_l1 =
text.texts_from_array(x_train=x_train, y_train=y_train,
x_test=x_test, y_test=y_test
class_names=categories_1,
preprocess_mode='bert',
maxlen= 256,
max_features=35000)
Results:
precision recall f1-score support
1 0.65 0.80 0.72 151
2 0.45 0.28 0.35 89
accuracy 0.61 240
macro avg 0.55 0.54 0.53 240
weighted avg 0.58 0.61 0.58 240
array([[121, 30],
[ 64, 25]])
Тем не менее, я думаю, что 55% - это еще не удовлетворительная точность, немного лучше, чем случайное предположение.
============ обновление 7.26 ============
Следуя предложению Маркоса Лимы, я сделал несколько дополнительных шагов в своих процедурах:
удалить все числа, знаки препинания и лишние пробелы перед предварительной обработкой Ktrain pkg. (Я думал, что Ktrain pkg сделает это за меня, но не уверен)
Я использую первые 384 и последние 128 токенов любого текста в моем примере. Это то, что я назвал стратегией "голова + хвост".
Задача по-прежнему бинарная классификация (положительная vs отрицательная)
Это показатель кривой обучения. Он остается таким же, как тот, который я опубликовал ранее. И он по-прежнему выглядит совсем иначе, чем тот, что опубликовал Маркос Лима:
Ниже приведены мои результаты, которые, вероятно, являются лучшим набором результатов, которые я получил.
begin training using onecycle policy with max lr of 1e-05...
Train on 1405 samples
Epoch 1/4
1405/1405 [==============================] - 186s 133ms/sample - loss: 0.7220
- accuracy: 0.5431
Epoch 2/4
1405/1405 [==============================] - 167s 119ms/sample - loss: 0.6866
- accuracy: 0.5843
Epoch 3/4
1405/1405 [==============================] - 166s 118ms/sample - loss: 0.6565
- accuracy: 0.6335
Epoch 4/4
1405/1405 [==============================] - 166s 118ms/sample - loss: 0.5321
- accuracy: 0.7587
precision recall f1-score support
1 0.77 0.69 0.73 241
2 0.46 0.56 0.50 111
accuracy 0.65 352
macro avg 0.61 0.63 0.62 352
weighted avg 0.67 0.65 0.66 352
array([[167, 74],
[ 49, 62]])
Примечание: я думаю, что, возможно, причина, по которой pkg так сложно хорошо справиться с моей задачей, заключается в том, что эта задача похожа на комбинацию классификации и анализа настроений. Классическая задача классификации новостных статей - определить, к какой категории относятся новости, например, биология, экономика, спорт. Слова, используемые в разных категориях, довольно разные. С другой стороны, классическим примером классификации настроений является анализ обзоров Yelp или IMDB. Я предполагаю, что эти тексты довольно просто выражают свои настроения, тогда как тексты в моем примере, экономические новости, отчасти отшлифованы и хорошо организованы перед публикацией, поэтому настроение всегда может проявляться каким-то неявным образом, что BERT, возможно, не сможет обнаружить.
3 ответа
Пробуем оптимизировать гиперпараметры.
Прежде чем делать learner.fit_onecycle(2e-5, 4). Пытаться:learner.lr_find(show_plot=True, max_epochs=2)
Все ли классы имеют вес около 20%? Может, попробуем что-нибудь из этого:
MODEL_NAME = 'bert'
t = text.Transformer(MODEL_NAME, maxlen=500, class_names=train_b.target_names)
.....
.....
# the one we got most wrong
learner.view_top_losses(n=1, preproc=t)
Для вышеуказанного класса увеличьте вес.
Имеет ли набор для валидации стратифицированную выборку или случайную выборку?
Форма вашего обучения не ожидается.
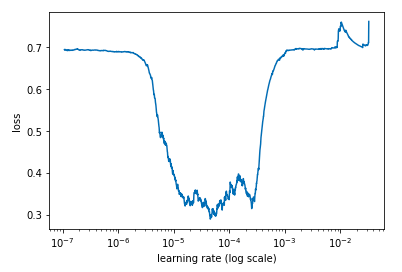 Моя кривая (выше) показывает, что TR должно быть около 1e-5, но у вас ровный.
Моя кривая (выше) показывает, что TR должно быть около 1e-5, но у вас ровный.
Попробуйте предварительно обработать свои данные:
- Удалите числа и смайлики.
- Перепроверьте свои данные на наличие ошибок (обычно в y_train).
- Используйте свою языковую модель или мультиязычность, если это не английский.
Вы сказали, что:
Средняя длина превышает 512 слов.
Попробуйте разбить каждый текст на 512 токенов, потому что вы можете потерять много информации для классификации, когда модель BERT усекает его.
Попробуйте рассматривать проблему как задачу регрессии текста, как эта модель настроений Yelp, которая была обучена с помощью ktrain.