Почему в этом примере keras (SGD) optimizer.minimize() не достигает глобального минимума?
Я заканчиваю руководство по TensorFlow через DataCamp и переписываю / реплицирую примеры кода, над которыми я работаю, в моем собственном блокноте Jupyter.
Вот оригинальные инструкции из проблемы кодирования:
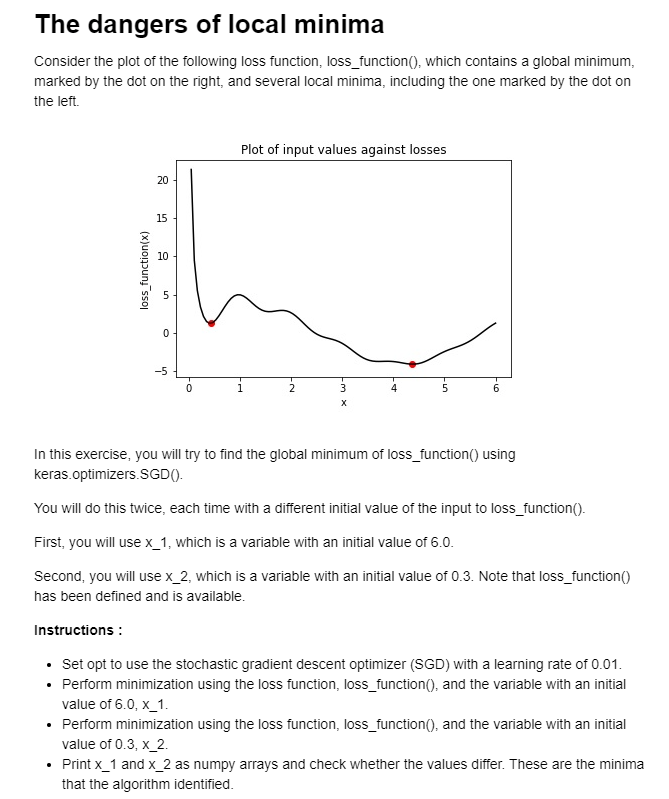
Я запускаю следующий фрагмент кода и не могу получить тот же результат, который я генерирую в учебнике, который, как я подтвердил, являются правильными значениями с помощью подключенной диаграммы рассеяния x vs. loss_function(x), как показано на немного ниже.
# imports
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import Variable, keras
def loss_function(x):
import math
return 4.0*math.cos(x-1)+np.divide(math.cos(2.0*math.pi*x),x)
# Initialize x_1 and x_2
x_1 = Variable(6.0, np.float32)
x_2 = Variable(0.3, np.float32)
# Define the optimization operation
opt = keras.optimizers.SGD(learning_rate=0.01)
for j in range(100):
# Perform minimization using the loss function and x_1
opt.minimize(lambda: loss_function(x_1), var_list=[x_1])
# Perform minimization using the loss function and x_2
opt.minimize(lambda: loss_function(x_2), var_list=[x_2])
# Print x_1 and x_2 as numpy arrays
print(x_1.numpy(), x_2.numpy())
Я рисую быстро подключенную диаграмму рассеяния, чтобы подтвердить (успешно), что функция потерь, которую я использую, возвращает меня к тому же графику, что и в примере (см. Снимок экрана выше)
# Generate loss_function(x) values for given range of x-values
losses = []
for p in np.linspace(0.1, 6.0, 60):
losses.append(loss_function(p))
# Define x,y coordinates
x_coordinates = list(np.linspace(0.1, 6.0, 60))
y_coordinates = losses
# Plot
plt.scatter(x_coordinates, y_coordinates)
plt.plot(x_coordinates, y_coordinates)
plt.title('Plot of Input values (x) vs. Losses')
plt.xlabel('x')
plt.ylabel('loss_function(x)')
plt.show()
Вот результирующие глобальный и локальный минимумы, соответственно, согласно среде DataCamp:
4,38 - правильный глобальный минимум, а 0,42 действительно соответствует первым локальным минимумам на графиках RHS (при запуске с x_2 = 0,3)
И вот результаты моего окружения, оба из которых движутся в противоположном направлении, в котором они должны двигаться, пытаясь минимизировать значение потерь:
Я потратил большую часть последних 90 минут, пытаясь разобраться, почему мои результаты не согласуются с результатами консоли DataCamp / почему оптимизатор не может минимизировать эти потери для этого простого игрушечного примера...?
Я ценю любые предложения, которые могут появиться у вас после запуска предоставленного кода в своих собственных средах, заранее большое спасибо!!!
1 ответ
Как оказалось, разница в выводах возникла из-за точности по умолчанию tf.division () (vs np.division ()) и tf.cos () (vs math.cos ()) - операций, которые были указаны в (мое записанное, "индивидуальное") определение функции loss_function().
Функция loss_function () была предопределена в теле учебника, и когда я "проверил" ее с помощью пакета inspect (используя inspect.getsourcelines (loss_function)), чтобы переопределить ее в моей собственной среде, на выходе этой проверки не было 't ясно указывает, что tf.division & tf.cos использовались вместо их аналогов NumPy (которые использовались моей версией кода).
Фактическая разница довольно мала, но, очевидно, достаточна, чтобы подтолкнуть оптимизатор в противоположном направлении (от двух соответствующих минимумов).
После замены tf.division () и tf.cos (как показано ниже) я смог получить те же результаты, что и на консоли DC.
Вот код функции loss_function, которая вернется к тем же результатам, что и в консоли (снимок экрана):
def loss_function(x):
import math
return 4.0*tf.cos(x-1)+tf.divide(tf.cos(2.0*math.pi*x),x)