Почему модель keras после компиляции предсказывает медленнее?
Теоретически прогноз должен быть постоянным, так как веса имеют фиксированный размер. Как мне вернуть свою скорость после компиляции (без удаления оптимизатора)?
См. Связанный эксперимент: https://nbviewer.jupyter.org/github/off99555/TensorFlowExperiments/blob/master/test-prediction-speed-after-compile.ipynb?flush_cache=true
2 ответа
ОБНОВЛЕНИЕ - 15.01.2020: текущая передовая практика для небольших партий должна заключаться в непосредственной подаче входных данных в модель, т.е.preds = model(x), и если слои ведут себя по-разному при обучении / выводе, model(x, training=False). Для последней фиксации это теперь задокументировано.
Я не тестировал их, но, согласно обсуждению Git, также стоит попробоватьpredict_on_batch() - особенно с улучшениями в TF 2.1.
КОНЕЧНЫЙ КУЛЬПРИТ:self._experimental_run_tf_function = True. Это экспериментально. Но на самом деле это не так уж плохо.
Всем разработчикам TensorFlow, читающим: очистите свой код. Это беспорядок. И это нарушает важные методы кодирования, например, одна функция выполняет одно действие;_process_inputsделает намного больше, чем просто "вводимые данные", то же самое и для_standardize_user_data. "Я не заплатил достаточно", - но вы делаете оплату, в дополнительное время, потраченного понимание своего собственного материала, а также пользователи, заполняющих страницу Проблемы, связанные с ошибками проще решить с более ясным кодом.
РЕЗЮМЕ: это только немного медленнее сcompile().
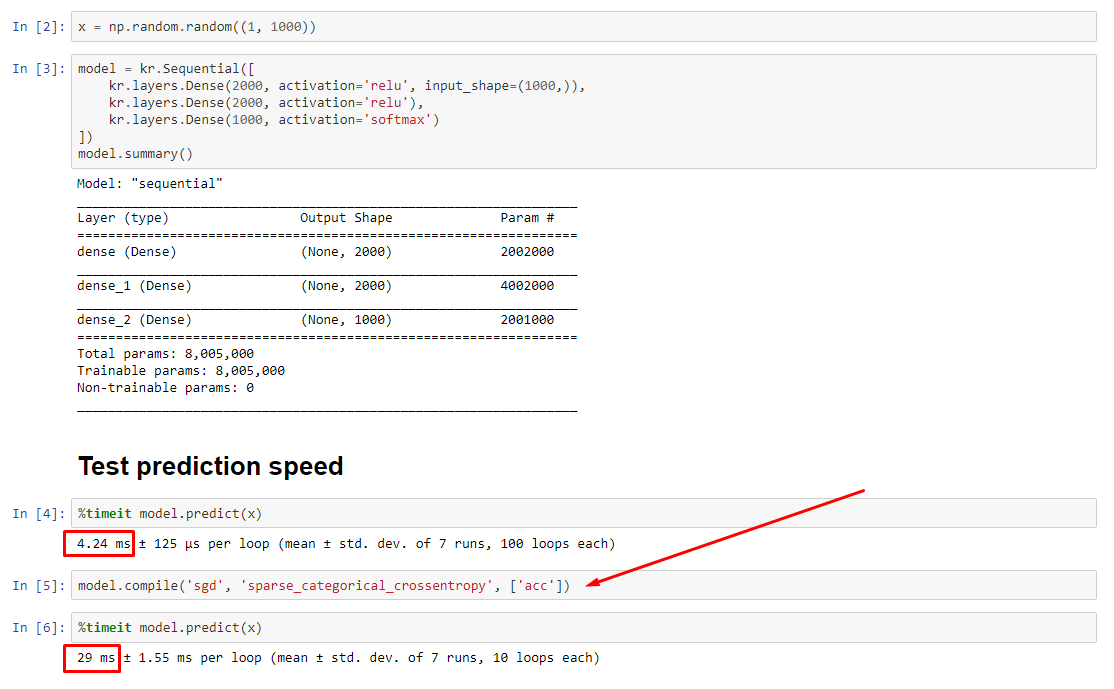
compile() устанавливает внутренний флаг, который назначает другую функцию прогнозирования predict. Эта функция строит новый график при каждом вызове, замедляя его по сравнению с некомпилированным. Однако разница заметна только тогда, когда время поезда намного короче времени обработки данных. Если мы увеличим размер модели хотя бы до среднего, они станут равными. Смотрите код внизу.
Это небольшое увеличение времени обработки данных более чем компенсируется возможностями расширенного графа. Поскольку более эффективно хранить только один граф модели, одна предварительная компиляция отбрасывается. Тем не менее: если ваша модель мала по сравнению с данными, вам лучше безcompile()для вывода модели. См. Мой другой ответ для обходного пути.
ЧТО Я ДОЛЖЕН ДЕЛАТЬ?
Сравните производительность модели в скомпилированной и некомпилированной версиях, как показано в коде внизу.
- Скомпилирован быстрее: запустить
predictна скомпилированной модели. - Скомпилирован медленнее: запустить
predictна некомпилированной модели.
Да, оба варианта возможны, и это будет зависеть от (1) размера данных; (2) размер модели; (3) оборудование. Код внизу показывает, что скомпилированная модель работает быстрее, но 10 итераций - это небольшой пример. См. "Обходные пути" в моем другом ответе "с практическими рекомендациями".
ДЕТАЛИ:
На отладку ушло время, но было весело. Ниже я описываю основных виновников, которые я обнаружил, цитирую некоторую соответствующую документацию и показываю результаты профилировщика, которые привели к окончательному узкому месту.
(FLAG == self.experimental_run_tf_function, для краткости)
Modelпо умолчанию создается с помощьюFLAG=False.compile()устанавливает это вTrue.predict()включает в себя получение функции прогнозирования,func = self._select_training_loop(x)- Без особых кваргов перешли в
predictа такжеcompile, все остальные флаги таковы, что:- (А)
FLAG==True->func = training_v2.Loop() - (В)
FLAG==False->func = training_arrays.ArrayLikeTrainingLoop()
- (А)
- Исходя из строки документации исходного кода, (A) сильно зависит от графа, использует больше стратегии распространения, а операторы склонны создавать и уничтожать элементы графа, что "может" (делать) влиять на производительность.
Истинный виновник:_process_inputs(), что составляет 81% времени выполнения. Его основная составляющая?_create_graph_function(), 72% времени выполнения. Этот метод даже не существует для (B). Однако при использовании модели среднего размера_process_inputsсоставляет менее 1% времени выполнения. Код внизу и результаты профилирования.
ПРОЦЕССОРЫ ДАННЫХ:
(А):<class 'tensorflow.python.keras.engine.data_adapter.TensorLikeDataAdapter'>, используется в _process_inputs(). Соответствующий исходный код
(B):numpy.ndarray, возвращенный convert_eager_tensors_to_numpy. Соответствующий исходный код, а здесь
ФУНКЦИЯ ВЫПОЛНЕНИЯ МОДЕЛИ (например, прогноз)
(A): функция распределения, и здесь
(B): функция распределения (разная), а здесь
ПРОФИЛЕР: результаты для кода в моем другом ответе "крошечная модель" и в этом ответе "средняя модель":
Маленькая модель: 1000 итераций,compile()

Маленькая модель: 1000 итераций, нет compile()

Средняя модель: 10 итераций

ДОКУМЕНТАЦИЯ (косвенно) о воздействииcompile(): источник
В отличие от других операций TensorFlow, мы не преобразуем числовые входные данные Python в тензоры. Более того, для каждого отдельного числового значения Python создается новый график, например, вызов
g(2)а такжеg(3)сгенерирует два новых графика
functionсоздает отдельный график для каждого уникального набора входных форм и типов данных. Например, следующий фрагмент кода приведет к трассировке трех отдельных графиков, так как каждый вход имеет разную форму.Один объект tf.function может потребоваться для сопоставления с несколькими графами вычислений под капотом. Это должно быть видно только как производительность (графики трассировки имеют ненулевые вычислительные затраты и затраты на память), но не должны влиять на правильность программы.
КОНТРОЛЬНЫЙ ПРИМЕР:
from tensorflow.keras.layers import Input, Dense, LSTM, Bidirectional, Conv1D
from tensorflow.keras.layers import Flatten, Dropout
from tensorflow.keras.models import Model
import numpy as np
from time import time
def timeit(func, arg, iterations):
t0 = time()
for _ in range(iterations):
func(arg)
print("%.4f sec" % (time() - t0))
batch_size = 32
batch_shape = (batch_size, 400, 16)
ipt = Input(batch_shape=batch_shape)
x = Bidirectional(LSTM(512, activation='relu', return_sequences=True))(ipt)
x = LSTM(512, activation='relu', return_sequences=True)(ipt)
x = Conv1D(128, 400, 1, padding='same')(x)
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(128, activation='relu')(x)
x = Dense(64, activation='relu')(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(ipt, out)
X = np.random.randn(*batch_shape)
timeit(model.predict, X, 10)
model.compile('adam', loss='binary_crossentropy')
timeit(model.predict, X, 10)
Выходы:
34.8542 sec
34.7435 sec
ОБНОВЛЕНИЕ: см. Фактический ответ, опубликованный как отдельный ответ; этот пост содержит дополнительную информацию
.compile() устанавливает большую часть графика TF/Keras, включая потери, метрики, градиенты и частично оптимизатор и его веса, что гарантирует заметное замедление.
Что является неожиданным является степень замедления - 10 раз на моем собственном опыте, так и дляpredict(), который не обновляет веса. Заглянув в исходный код TF2, элементы графа кажутся тесно переплетенными, при этом ресурсы не обязательно распределяются "справедливо".
Возможный пропуск со стороны разработчиков на predictпроизводительность для некомпилированной модели, поскольку модели обычно используются скомпилированными, но на практике это неприемлемое различие. Также возможно, что это "необходимое зло", поскольку есть простой обходной путь (см. Ниже).
Это не полный ответ, и я надеюсь, что кто-то сможет предоставить его здесь - если нет, я бы предложил открыть проблему Github на TensorFlow. (OP имеет; здесь)
Обходной путь: обучите модель, сохраните ее веса, перестройте модель без компиляции, загрузите веса. Вы не сохранить всю модель (например,model.save()), так как он загрузится скомпилированным - вместо этого используйте model.save_weights() а также model.load_weights().
Обходной путь 2: выше, но используйтеload_model(path, compile=False); Автор предложения: Daniel Möller
ОБНОВЛЕНИЕ: чтобы уточнить, оптимизатор не полностью создан с помощьюcompile, включая его weights а также updates тензоры - это делается при первом вызове подгоночной функции (fit, train_on_batchи т. д.), через model._make_train_function().
Таким образом, наблюдаемое поведение еще более странно. Что еще хуже, сборка оптимизатора не вызывает дальнейшего замедления работы (см. Ниже) - предположение о "размере графика" здесь не является основным объяснением.
РЕДАКТИРОВАТЬ: на некоторых моделях замедление в 30 раз. TensorFlow, что ты наделал. Пример ниже:
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
import numpy as np
from time import time
def timeit(func, arg, iterations):
t0 = time()
for _ in range(iterations):
func(arg)
print("%.4f sec" % (time() - t0))
ipt = Input(shape=(4,))
x = Dense(2, activation='relu')(ipt)
out = Dense(1, activation='sigmoid')(x)
model = Model(ipt, out)
X = np.random.randn(32,4)
timeit(model.predict, X, 1000)
model.compile('adam', loss='binary_crossentropy')
timeit(model.predict, X, 1000)
model._make_train_function() # build optimizer
timeit(model.predict, X, 1000)
Выходы:
0.9891 sec
29.785 sec
29.521 sec