простой начальный блок в pytorch, требующий гораздо больше времени для обучения на GPU?
Я тренирую очень простой начальный блок, за которым следует maxpool и полностью подключенный уровень на графическом процессоре NVIDIA GeForce RTX 2070, и его итерация занимает очень много времени. Только что закончили 10 итераций более чем за 24 часа.
Вот код для определения начальной модели
class Net(nn.Module):
def __init__(self):
super().__init__()
input_channels = 3
conv_block = BasicConv2d(input_channels, 64, kernel_size=1)
self.branch3x3stack = nn.Sequential(
BasicConv2d(input_channels, 64, kernel_size=1),
BasicConv2d(64, 96, kernel_size=3, padding=1),
BasicConv2d(96, 96, kernel_size=3, padding=1),
)
self.branch3x3 = nn.Sequential(
BasicConv2d(input_channels, 64, kernel_size=1),
BasicConv2d(64, 96, kernel_size=3, padding=1),
)
self.branch1x1 = BasicConv2d(input_channels, 96, kernel_size=1)
self.branchpool = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(input_channels, 96, kernel_size=1),
)
self.maxpool = nn.MaxPool2d(kernel_size=8, stride=8)
self.fc_seqn = nn.Sequential(nn.Linear(301056, 1))
def forward(self, x):
x = [
self.branch3x3stack(x),
self.branch3x3(x),
self.branch1x1(x),
self.branchpool(x),
]
x = torch.cat(x, 1)
x = self.maxpool(x)
x = x.view(x.size(0), -1)
x = self.fc_seqn(x)
return x # torch.cat(x, 1)
и тренировочный код, который я использовал
def training_code(self, model):
model = copy.deepcopy(model)
model = model.to(self.device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=self.learning_rate)
for epoch in range(self.epochs):
print("\n epoch :", epoch)
running_loss = 0.0
start_epoch = time.time()
for i, (inputs, labels) in enumerate(self.train_data_loader):
inputs = inputs.to(self.device)
labels = labels.to(self.device)
optimizer.zero_grad()
outputs = (model(inputs)).squeeze()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % log_step == log_step - 1:
avg_loss = running_loss / float(log_step)
print("[epoch:%d, batch:%5d] loss: %.3f" % (epoch + 1, i + 1, avg_loss))
running_loss = 0.0
if epoch % save_model_step == 0:
self.path_saved_model = path_saved_model + "_" + str(epoch)
self.save_model(model)
print("\nFinished Training\n")
self.save_model(model)
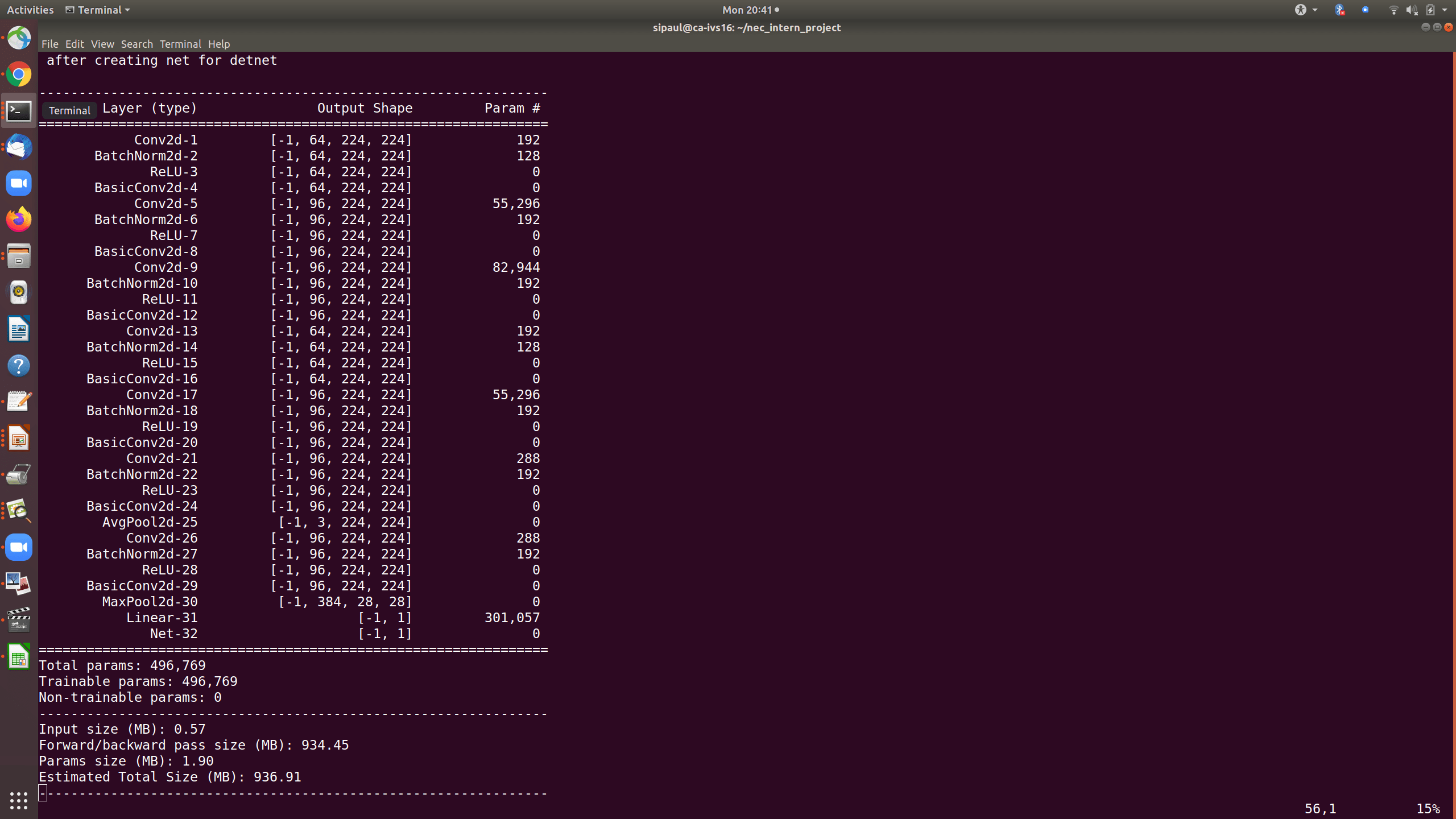
Вот сводка сверточной нейронной сети. Может ли кто-нибудь помочь мне, как ускорить обучение?
Вот сводка сверточной нейронной сети после уменьшения количества входов на полностью подключенный (FC) слой. Но все же время обучения очень велико, как и раньше. Может будет полезен совет, как ускорить тренировку.
1 ответ
Архитектура
Ваш nn.Linear имеет огромный входной сигнал, который направляется только на один нейрон для регрессии.
Вы должны использовать torch.nn.AdaptiveAvgPool2d как это:
class Net(nn.Module):
def __init__(self):
... # your stuff before
self.pool = nn.AdaptiveAvgPool2D(output_size=1)
self.fc_seqn = nn.Sequential(nn.Linear(96 * 4, 1))
def forward(self, x):
x = [
self.branch3x3stack(x),
self.branch3x3(x),
self.branch1x1(x),
self.branchpool(x),
]
x = torch.cat(x, 1)
x = torch.squeeze(self.pool(x))
if len(x.shape) == 1:
x = torch.unsqueeze(x, dim=0)
x = self.fc_seqn(x)
return x
Это также должно помочь в вашей задаче, поскольку она не будет слишком параметризованной.
Данные
В зависимости от размера изображения вы можете обрезать его (или произвольно обрезать), используя torchvision.transforms на меньший размер.
Если вы можете, вы также можете пойти с torch.nn.DistributedDataParallel для распараллеливания на многих графических процессорах, но я полагаю, что это не то, что вам нужно.
Вы также можете cache некоторые данные после загрузки изображения (см. torchdata project (__disclaimer: я автор)).
Также torch.utils.data.DataLoader с участием num_workers аргумент установлен на большее число, чем 1 должен ускорить загрузку изображений (я обычно выбираю количество ядер, которые есть на моей машине, хотя вам понадобятся некоторые эксперименты с этим).
Смешанная точность
Вы должны извлечь большую пользу из этого шага, поскольку ваша графическая карта поддерживает технологию тензорных ядер.
В PyTorch 1.6.0 это довольно просто с torch.cuda.amp пакет. По сути, вам просто нужно использовать один диспетчер контекста и масштабатор градиента ( здесь и здесь, соответственно).
Это позволяет использовать больший размер партии (поскольку в архитектуре некоторый вес преобразован в float16 вместо того float32).