Как получить воспроизводимые результаты (Keras, Tensorflow):
Для воспроизводимости результатов я перерисовал более 20 статей и добавил в свой скрипт максимум функций... но не смог.
В официальном источнике есть 2 вида семян - глобальные и рабочие. Может быть, ключ к решению моей проблемы - это установка рабочего seed, но я не понимаю, где его применить.
Не могли бы вы помочь мне добиться воспроизводимых результатов с помощью tensorflow (версия> 2.0)? Большое спасибо.
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from keras.optimizers import adam
from sklearn.preprocessing import MinMaxScaler
np.random.seed(7)
import tensorflow as tf
tf.random.set_seed(7) #analogue of set_random_seed(seed_value)
import random
random.seed(7)
tf.random.uniform([1], seed=1)
tf.Graph.as_default #analogue of tf.get_default_graph().finalize()
rng = tf.random.experimental.Generator.from_seed(1234)
rng.uniform((), 5, 10, tf.int64) # draw a random scalar (0-D tensor) between 5 and 10
df = pd.read_csv("s54.csv",
delimiter = ';',
decimal=',',
dtype = object).apply(pd.to_numeric).fillna(0)
#data normalization
scaler = MinMaxScaler()
scaled_values = scaler.fit_transform(df)
df.loc[:,:] = scaled_values
X_train, X_test, y_train, y_test = train_test_split(df.iloc[:,1:],
df.iloc[:,:1],
test_size=0.2,
random_state=7,
stratify = df.iloc[:,:1])
model = Sequential()
model.add(Dense(1200, input_dim=len(X_train.columns), activation='relu'))
model.add(Dense(150, activation='relu'))
model.add(Dense(80, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
loss="binary_crossentropy"
optimizer=adam(lr=0.01)
metrics=['accuracy']
epochs = 2
batch_size = 32
verbose = 0
model.compile(loss=loss,
optimizer=optimizer,
metrics=metrics)
model.fit(X_train, y_train, epochs = epochs, batch_size=batch_size, verbose = verbose)
predictions = model.predict(X_test)
tn, fp, fn, tp = confusion_matrix(y_test, predictions>.5).ravel()
4 ответа
В качестве справки из документации
Операции, которые полагаются на случайное начальное число, на самом деле производят его от двух начальных значений: глобальных начальных значений и начальных значений уровня операции. Это устанавливает глобальное семя.
Его взаимодействие с семенами операционного уровня выглядит следующим образом:
- Если не задано ни глобальное начальное число, ни начальное значение операции: для этой операции используется случайно выбранное начальное число.
- Если начальное значение операции не задано, но установлено глобальное начальное число: система выбирает начальное значение операции из потока начальных значений, определяемых глобальным начальным числом.
- Если начальное число операции установлено, но глобальное начальное число не задано: глобальное начальное число по умолчанию и указанное начальное число операции используются для определения случайной последовательности.
- Если заданы и глобальное, и начальное значение операции: оба начальных числа используются вместе для определения случайной последовательности.
1-й сценарий
По умолчанию будет выбрано случайное семя. Это легко заметить по результатам. Он будет иметь разные значения каждый раз, когда вы повторно запускаете программу или вызываете код несколько раз.
x_train = tf.random.normal((10,1), 1, 1, dtype=tf.float32)
print(x_train)
2-й сценарий
Глобальное значение установлено, но операция не установлена. Хотя он сгенерировал другое семя из первого и второго случайных. Если вы повторно запустите или перезапустите код. Семя для обоих по-прежнему будет одинаковым. И то, и другое приводило к одному и тому же результату снова и снова.
tf.random.set_seed(2)
first = tf.random.normal((10,1), 1, 1, dtype=tf.float32)
print(first)
sec = tf.random.normal((10,1), 1, 1, dtype=tf.float32)
print(sec)
3-й сценарий
Для этого сценария, где задано начальное число операции, но не глобальное значение. Если вы повторно запустите код, он даст вам другие результаты, но если вы перезапустите среду выполнения, if даст вам ту же последовательность результатов, что и при предыдущем запуске.
x_train = tf.random.normal((10,1), 1, 1, dtype=tf.float32, seed=2)
print(x_train)
4-й сценарий
Оба начальных числа будут использоваться для определения случайной последовательности. Изменение глобального начального числа и начального числа операции даст разные результаты, но перезапуск среды выполнения с тем же начальным значением все равно даст те же результаты.
tf.random.set_seed(3)
x_train = tf.random.normal((10,1), 1, 1, dtype=tf.float32, seed=1)
print(x_train)
Создал воспроизводимый код для справки.
Установив глобальное семя, он всегда дает одинаковые результаты.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
## GLOBAL SEED ##
tf.random.set_seed(3)
x_train = tf.random.normal((10,1), 1, 1, dtype=tf.float32)
y_train = tf.math.sin(x_train)
x_test = tf.random.normal((10,1), 2, 3, dtype=tf.float32)
y_test = tf.math.sin(x_test)
model = Sequential()
model.add(Dense(1200, input_shape=(1,), activation='relu'))
model.add(Dense(150, activation='relu'))
model.add(Dense(80, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
loss="binary_crossentropy"
optimizer=tf.keras.optimizers.Adam(lr=0.01)
metrics=['mse']
epochs = 5
batch_size = 32
verbose = 1
model.compile(loss=loss,
optimizer=optimizer,
metrics=metrics)
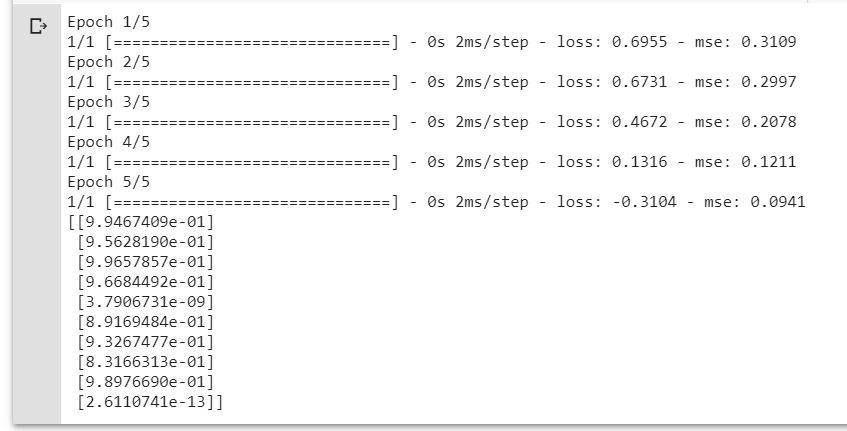
histpry = model.fit(x_train, y_train, epochs = epochs, batch_size=batch_size, verbose = verbose)
predictions = model.predict(x_test)
print(predictions)
Примечание: если вы используете TensorFlow 2 выше, Keras уже есть в API, поэтому вам следует использовать TF.Keras, а не собственный.
Все это смоделировано в Google Colab.
Начиная с TensorFlow 2.8, естьtf.config.experimental.enable_op_determinism().
Вы можете обеспечить воспроизводимость даже на графическом процессоре с помощью
import tensorflow as tf
tf.keras.utils.set_random_seed(42) # sets seeds for base-python, numpy and tf
tf.config.experimental.enable_op_determinism()
вы можете установить начальное число для всех рандомов, следуя
import numpy as np
np.random.seed(0)
import random
random.seed(0)
import tensorflow
tensorflow.random.set_seed(0)
import tensorflow as tf
tf.random.set_seed(0)
tf.keras.utils.set_random_seed(0)
tf.config.experimental.enable_op_determinism()
Когда мы используем слои>= 3 и нейроны>= 100, количество ядер процессора имеет значение. Моя проблема заключалась в том, чтобы запустить сценарий на двух разных серверах:
-с 32 ядрами
-с 16 ядрами
Когда я запускал скрипт на серверах с 32 ядрами (и даже с 32 и 24 ядрами), результаты были идентичными.