Настройте плотные слои для изучения одномерных массивов
У меня около 100 тыс. Массивов размером 256, которые я хотел бы ввести в нейронную сеть, состоящую из нескольких плотных слоев, и вывести 100 тыс. Массивов снова размером 256. (я бы хотел, чтобы моя сеть преобразовывала входной массив в выходной массив). Не могу правильно его настроить.
Мой X_train а также y_train иметь форму (98304, 256)мой X_test а также y_test (16384, 256).
Моя сеть на данный момент
model = Sequential()
model.add(Dense(1, input_shape=(256,), activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(256, activation='linear'))
optimizer = Adam()
model.compile(optimizer=optimizer,loss='mean_squared_error',metrics=['accuracy', 'mae'])
Сеть действительно работает, но значимого результата это не дает. Он останавливается через 20 эпох, потому что я даю ему раннюю остановку.
Epoch 00019: val_loss did not improve from -inf
Epoch 20/200
6400/6400 [==============================] - 1s 232us/step - loss: nan - acc: 0.2511 - mean_absolute_error: nan - val_loss: nan - val_acc: 0.2000 - val_mean_absolute_error: nan
И если я попытаюсь использовать его для прогнозирования, я получаю только значения nan (у меня нет nan в моем обучающем наборе).
Надеюсь, кто-нибудь сможет мне с этим помочь. Заранее спасибо.
Изменить Чтобы проверить, есть ли проблема с входами или алгоритмом, я попытался создать свои входы и цели, используя следующий код
X_train=[]
y_train=[]
for it in range(1000):
beginning=random.uniform(0,1)
end=random.uniform(0,1)
X_train.append([beginning+(end-beginning)*jt/256 for jt in range(256)])
y_train.append([end+(beginning-end)*jt/256 for jt in range(256)])
X_train=np.array(X_train)
y_train=np.array(y_train)
И я все еще получаю
Epoch 27/200
1000/1000 [==============================] - 0s 236us/step - loss: nan - acc: 0.4970 - mean_absolute_error: nan
Edit2: Если я увеличиваю сложность своей сети, мне удается получить потери, отличные от nan, с использованием 10k обучающих массивов, созданных с использованием функции выше. Однако результаты все еще довольно плохие, что заставляет меня задуматься, что я неправильно настраиваю сеть.
Новая сеть:
model = Sequential()
model.add(Dense(1, input_shape=(256,), activation='relu'))
model.add(Dense(2048, activation='relu'))
model.add(Dense(2048, activation='relu'))
model.add(Dense(2048, activation='relu'))
model.add(Dense(256, activation='linear'))
optimizer = Adam()
model.compile(optimizer=optimizer,loss='mean_squared_error',metrics=['mae'])
model.summary()
И результат, когда они сходятся
Epoch 33/200
10000/10000 [==============================] - 23s 2ms/step - loss: 0.0561 - mean_absolute_error: 0.2001 - val_loss: 0.0561 - val_mean_absolute_error: 0.2001
Если я проверяю выход сети, я всегда получаю вектор со всеми точками около 0,5 независимо от входа.
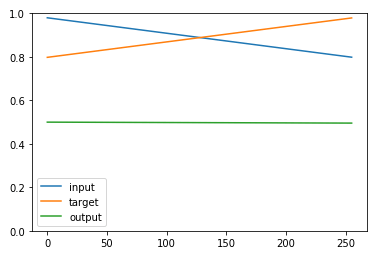
Кроме того, если я попытаюсь предсказать один вектор, используя y_pred=model.predict(Xval[3]) Я получаю ошибку
ValueError: Error when checking : expected dense_27_input to have shape (256,) but got array with shape (1,)
1 ответ
Ваш первый слой имеет только 1выходной нейрон, это кажется неправильным. Это может испортить вашу функцию потерь. Попробуйте заменитьmodel.add(Dense(1, input_shape=(256,), activation='relu')) с model.add(InputLayer(input_shape=(256,))).