Входные данные справки по Azure Stream Analytics не могут быть прочитаны из большого двоичного объекта хранилища
Мы пытаемся создать входную ссылку на хранилище для задания Azure Stream Analytics, и вся конфигурация и тест проходят успешно, однако, когда мы пытаемся использовать его в запросе, мы получаем следующие сообщения в пользовательском интерфейсе портала: "Во время выборки данных, данные не были получены от разделов "1" ". и "Не найдены данные для предварительного просмотра от refinput. Убедитесь, что вход недавно получил данные и выбран правильный формат этих событий". Это CSV-файл, который мы загрузили в учетную запись хранения, и это статические данные, которые не меняются. Большой двоичный объект является допустимым CSV-файлом, и его можно без проблем загрузить и открыть в Excel.
Есть идеи по поводу того, в чем может быть проблема?
1 ответ
Во-первых, я должен сказать, что входные данные ссылки на хранилище больших двоичных объектов не могут быть предварительно просмотрены, как указано в пользовательском интерфейсе портала ASA.
Как мы знаем, эталонный ввод должен использоваться в JOIN с Stream Input, его нельзя использовать отдельно. Итак, я полагаю, что ошибка, с которой вы столкнулись, возникает, когда вы тестируете ввод ссылки на соединение потокового ввода. Я воспроизвожу ту же проблему, что и ваша, см.
Насколько мне известно, данные предварительного просмотра предназначены для входного потока в реальном времени, они имитируют реальное выполнение задания ASA. Таким образом, вы должны убедиться, что ввод недавно получил правильный формат (что точно указано в сообщении об ошибке). Конечно, вы можете установить временной диапазон, чтобы масштабировать соответствующий диапазон по своему усмотрению.
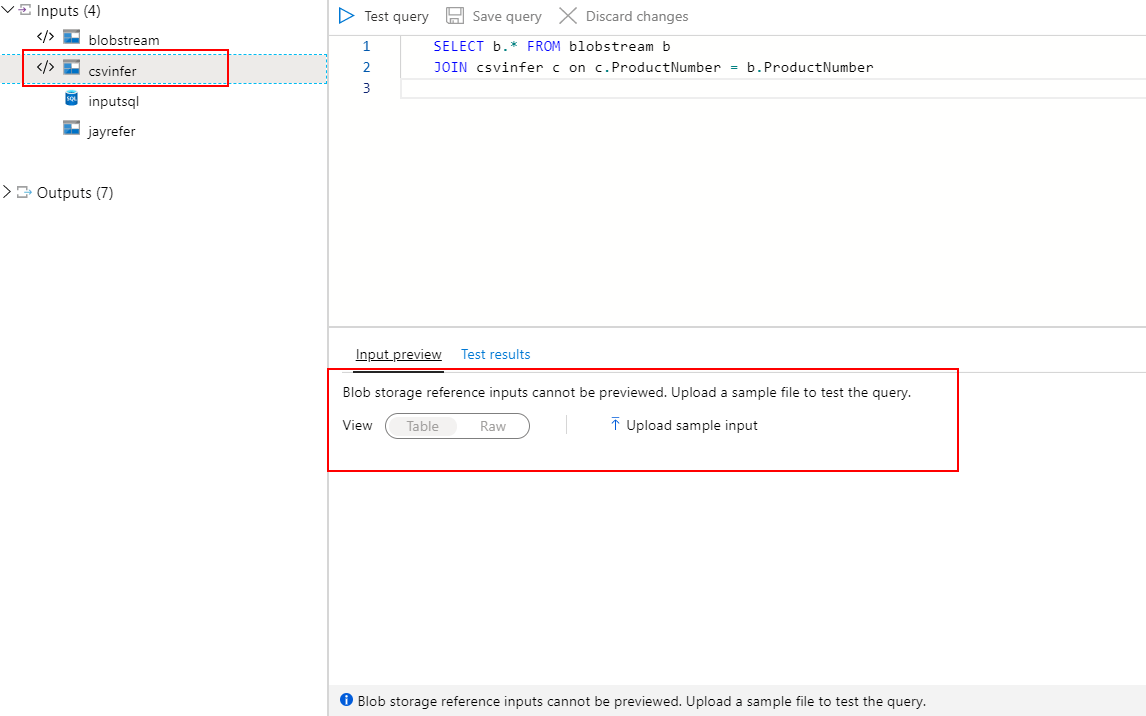
Что касается загрузки образцов данных, это полностью статический образец, на который не влияют никакие настройки времени. Просто статические данные для теста!