Генерация смеси биномиальных распределений
Я хочу создать смесь биномиального распределения. Почему мне это нужно, потому что я хочу иметь нормальную дискретную смесь гауссовых распределений. Есть ли какая-нибудь библиотека scipy для этого или вы можете подсказать мне алгоритм.
В общем, я знаю, что для предопределенных дистрибутивов можно использовать ppf. Но для этой функции я не думаю, что существует какой-либо прямой способ использования ppf.
Выборка из каждого и смешивание их также кажется проблематичным, потому что я не знаю, сколько экземпляров мне нужно выбирать из разных дистрибутивов.
В конце я хочу получить что-то вроде этого: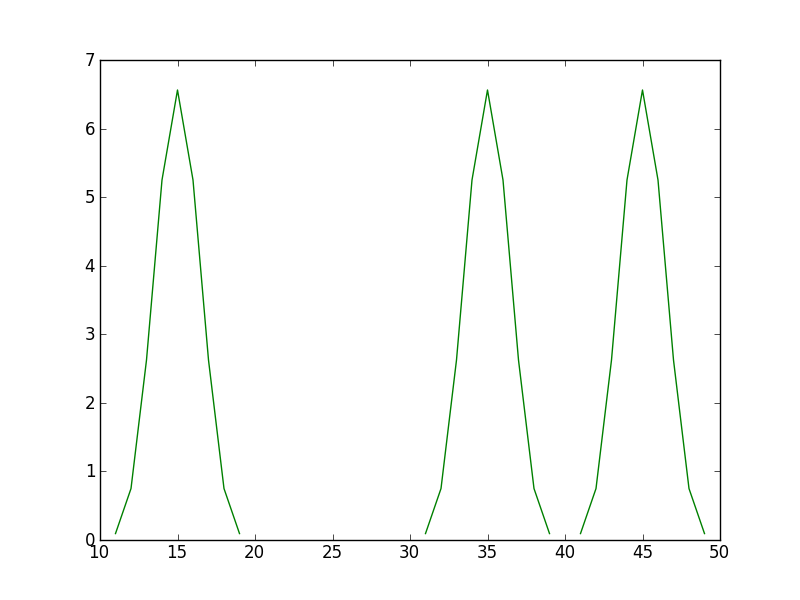
3 ответа
Благодаря @sega_sai,@askewchan и @Zhenya я сделал код сам, и я верю, что благодаря реализации он будет наиболее эффективным. Есть две функции, первая из которых состоит из смесей биномиальных распределений "binoNumber", имеющих одинаковый параметр N= максимум-минимум и одинаковое p=0,5, но смещенных в соответствии со случайными центрами, которые я сгенерировал для них.
global binoInitiated
binoInitiated=False;
def binoMixture(minimum,maximum,sampleSize):
global centers
binoNumber=10;
if (not binoInitiated):
centers=np.random.randint(minimum,maximum+1,binoNumber)
sigma=maximum-minimum-2
sam=np.array([]);
while sam.size<sampleSize:
i=np.random.choice(binoNumber);
temp=np.random.binomial(sigma, 0.5,1)+centers[i]-sigma/2+1
sam=np.append(sam,temp)
return sam
Эта функция предназначена для составления приблизительного PDF-файла для предварительно созданного дистрибутива. Спасибо @EnricoGiampieri, который использовал его код для создания этой части.
def binoMixtureDrawer(minimum,maximum):
global binoInitiated
global centers
sam=binoMixture(minimum,maximum,50000)
# this create the kernel, given an array it will estimate the probability over that values
kde = gaussian_kde( sam )
# these are the values over wich your kernel will be evaluated
dist_space = linspace( min(sam), max(sam), 500 )
# plot the results
fig.plot( dist_space, kde(dist_space),'g')
Вот простой способ генерации произвольных смесей биномиальных (и других) распределений. Он основан на том факте, что если вы хотите получить выборки (Nsamp) из смеси P(x)= сумма (w[i]*P_i(x), i=1..Nmix), то вы можете сделать это путем выборки Nsamp от каждого из P_i (х). Затем получите еще N выборок другой случайной величины, равной i с вероятностью w[i]. Эта случайная величина может использоваться для выбора того, из какого из P_i (x) будет получен данный образец:
import numpy as np,numpy.random, matplotlib.pyplot as plt
#parameters of the binomial distributions: pairs of (n,p)
binomsP = np.array([.5, .5, .5])
binomsCen = np.array([15, 45, 95]) # centers of binomial distributions
binomsN = (binomsCen/binomsP).astype(int)
fractions = [0.2, 0.3, 0.5]
#mixing fractions of the binomials
assert(sum(fractions)==1)
nbinoms = len(binomsN)
npoints = 10000
cumfractions = np.cumsum(fractions)
def mapper(x):
# convert the random number between 0 and 1 to
# the ID of the distribution according to the mixing fractions
return np.digitize(x, cumfractions)
x0 = np.random.binomial(binomsN[None, :],
binomsP[None, :], size=(npoints, nbinoms))
x = x0[:, mapper(np.random.uniform(size=npoints))]
plt.hist(x, bin=150, range=(0, 150))

Если вы не найдете умного способа вычисления обратного cdf (в этом случае сообщите нам!), Выборка отклонения является надежным способом. Запись в Википедии дает общее описание. Что я обнаружил на практике, вы должны быть немного осторожны с "инструментальным" распределением: в частности, оно не должно затухать намного быстрее, чем целевое распределение - если это произойдет, вы, вероятно, потеряете вклад хвостов.,
То, как я это сделал, я бы начал с плоского инструментального распределения: сгенерировал пару однородных случайных чисел. x а также y, где y из [0, 1) и x из [0, L), где L достаточно велик. Тогда сравните y а также cdf(x)Повторите до схождения. Если это работает, у вас все готово. Если этого недостаточно, используйте неплоский инструментальный дистрибутив: если хвост смеси гауссовский, вам, вероятно, лучше использовать гауссовский.
В качестве дополнительного примечания: если вы имеете дело с биномиальным распределением, вам нужно следить за переполнением / перерасходом - в зависимости от параметров, вам, возможно, придется использовать гауссовское приближение.