как суммировать несколько моделей логистической регрессии в таблице?
У меня есть набор данных с непрерывным возрастом и фактором, полом как фактором и 4 группами.
structure(list(Age = c(9, 12, 16, 57), Age_1 = structure(c(2L,
3L, 3L, 7L), .Label = c("8", "1", "2", "3", "4", "5", "6", "7"
), class = "factor"), Sex = structure(c(2L, 1L, 2L, 1L), .Label = c("M",
"F", "U"), class = "factor"), N = structure(c(2L, 2L, 2L,
2L), .Label = c("0", "1"), class = "factor"), G = structure(c(1L,
1L, 1L, 1L), .Label = c("0", "1"), class = "factor"), L_1 =
structure(c(1L,
1L, 1L, 1L), .Label = c("0", "1"), class = "factor"), C_1 =
structure(c(1L,
1L, 1L, 1L), .Label = c("0", "1"), class = "factor"), G_1 =
structure(c(1L,
1L, 1L, 1L), .Label = c("0", "1"), class = "factor"), m = structure(c(1L,
1L, 1L, 1L), .Label = c("0", "1"), class = "factor"), A = c(1,
1, 1, 1)), row.names = c(NA, 4L), class = "data.frame")
Я хочу выполнить логистическую регрессию для каждой переменной (возраст, возраст_1 и пол) для каждой из групп (N, G, L_1, C_1, G_1, m). например.
mylogit <- glm(N ~ Sex, data = logistic_s, family = "binomial")
mylogit <- glm(N ~ Age, data = logistic_s, family = "binomial")
Я использую gtsummary для объединения переменных в таблице.
library(gtsummary)
tbl_n <-
tbl_uvregression(
logistic_s[c("N", "Age", "sex", "Age_1")],
method = glm,
y = N,
method.args = list(family = binomial),
exponentiate = TRUE
)
tbl_n
Это дает результат для одной группы (например, N) с переменными Age, Age_1, Sex.
Я хочу повторить это с каждой из групп (например, N, G, L_1 и т.д.), а затем объединить таблицы в одну объединенную таблицу.
Я открыт для использования других пакетов, если есть другие варианты, которые лучше подходят для этого. Я хочу сделать таблицу, которую можно будет экспортировать в word.
1 ответ
Я согласен с тем, что некоторый воспроизводимый код будет полезен. Я не уверен на 100%, какой результат вы хотите получить. Вы хотите построить несколько одномерных моделей логистической регрессии отдельно для 2 или более групп?
Если это верно, вот один из способов сделать это: я буду использовать trial набор данных в gtsummaryпакет в качестве примера. Я сделаю групповую обработку переменной (trt).
library(gtsummary)
library(tidyverse)
trial_subset <-
trial %>%
select(trt, response, age, marker, grade)
Мы начнем с построения таблиц одномерной регрессии, стратифицированных по trt с использованием tbl_uvregression() функция от gtsummaryпакет. Они будут сохранены в новом столбце фрейма данных с именемtbl_uv.
df_uv <-
trial_subset %>%
# group by trt, and nest data within group
group_by(trt) %>%
nest() %>%
# build univariate logistic regression models separately within grouping variable
mutate(
tbl_uv = map(
data,
~tbl_uvregression(
data = .x,
y = response,
method = glm,
method.args = list(family = binomial),
exponentiate = TRUE
)
)
)
#> # A tibble: 2 x 3
#> # Groups: trt [2]
#> trt data tbl_uv
#> <chr> <list> <list>
#> 1 Drug A <tibble [98 x 4]> <tbl_vrgr>
#> 2 Drug B <tibble [102 x 4]> <tbl_vrgr>
Теперь мы можем использовать таблицы, сохраненные в df_uv чтобы объединить их в одну таблицу с помощью tbl_merge() функция.
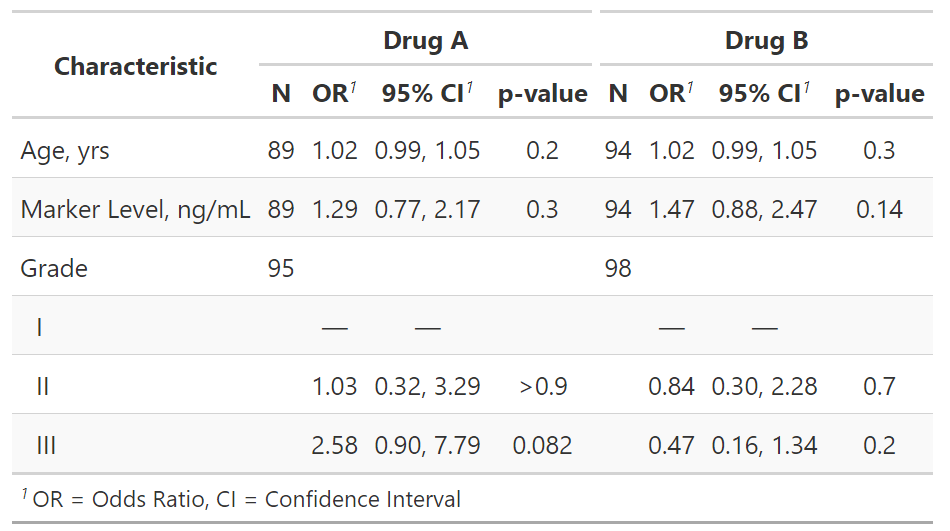
tbl_merge(
tbls = df_uv$tbl_uv, # list of the univariate logistic regression tables
tab_spanner = paste0("**", df_uv$trt, "**") # adding stars to bold the header
)
Это дает таблицу ниже. Надеюсь, это поможет!