Оценка Atari и награда в реализации rllib DQN
Я пытаюсь воспроизвести оценки DQN для Breakout с помощью RLLib. После 5 миллионов шагов средняя награда составляет 2,0, в то время как известная оценка Breakout с использованием DQN составляет 100+. Мне интересно, связано ли это с отсечением награды и, следовательно, фактическая награда не соответствует количеству очков от Atari. В базовых показателях OpenAI фактическая оценка помещается вinfo['r']значение вознаграждения - это фактически усеченное значение. То же самое и с RLLib? Есть ли способ увидеть фактический средний балл во время тренировки?
1 ответ
Согласно списку параметров трейнера, по умолчанию библиотека будет вырезать награды Atari:
# Whether to clip rewards prior to experience postprocessing. Setting to
# None means clip for Atari only.
"clip_rewards": None,
Тем не менее episode_reward_mean данные, представленные на тензорной доске, должны по-прежнему соответствовать фактическим, не обрезанным баллам.
Хотя средний балл 2 совсем немного по сравнению с тестами для Breakout, 5 миллионов шагов могут быть недостаточно большими для DQN, если вы не используете что-то вроде радуги, чтобы значительно ускорить процесс. Даже в этом случае DQN, как известно, медленно сходится, поэтому вы можете проверить свои результаты, используя вместо этого более длительный прогон, и / или рассмотреть возможность обновления конфигураций DQN.
Я собрал быстрый тест, и похоже, что отсечение награды не оказывает большого влияния на Breakout, по крайней мере, в начале тренировки (отсечено синим, обрезано оранжевым):
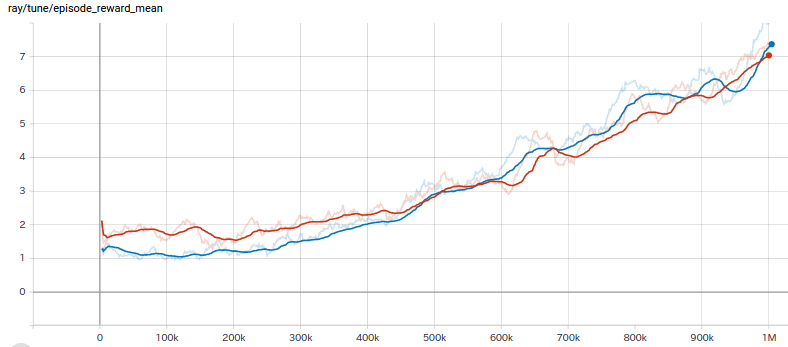
Я не слишком много знаю о Breakout, чтобы комментировать его систему подсчета очков, но если позже станут доступны более высокие награды, когда мы добьемся большей производительности (в отличие от получения того же небольшого вознаграждения, но с большей частотой, скажем, с большей частотой), мы должны начать видеть эти два расходятся. В таких случаях мы все еще можем нормализовать вознаграждения или преобразовать их в логарифмическую шкалу.
Вот конфигурации, которые я использовал:
lr: 0.00025
learning_starts: 50000
timesteps_per_iteration: 4
buffer_size: 1000000
train_batch_size: 32
target_network_update_freq: 10000
# (some) rainbow components
n_step: 10
noisy: True
# work-around to remove epsilon-greedy
schedule_max_timesteps: 1
exploration_final_eps: 0
prioritized_replay: True
prioritized_replay_alpha: 0.6
prioritized_replay_beta: 0.4
num_atoms: 51
double_q: False
dueling: False
Возможно, вас больше заинтересуют их rl-experiments где они опубликовали некоторые результаты из своей собственной библиотеки по сравнению со стандартными тестами вместе с конфигурациями, в которых вы сможете получить еще лучшую производительность.