Прогноз CatBoostRegression на тестовой прямой
CatBoostRegressor в тестовом наборе данных соответствует прямой линии

Первый график - набор данных поезда ( CatBoostRegressor обучен на основе зашумленного греха). Второй график - набор тестовых данных.
Почему это соответствует прямой линии? То же самое для других функций (например, f(x)=x и т. Д.)
x = np.linspace(0, 2*np.pi, 100)
y = func(x) + np.random.normal(0, 3, len(x))
x_test = np.linspace(0*np.pi, 4*np.pi, 200)
y_test = func(x_test)
train_pool = Pool(x.reshape((-1,1)), y)
test_pool = Pool(x_test.reshape((-1,1)))
model = CatBoostRegressor(iterations=100, depth=2, loss_function="RMSE",
verbose=True
)
model.fit(train_pool)
y_pred = model.predict(x.reshape((-1,1)))
y_test_pred = model.predict(test_pool)
poly = Polynomial(4)
p = poly.fit(x,y);
plt.plot(x, y, 'ko')
plt.plot(x, func(x), 'k')
plt.plot(x, y_pred, 'r')
plt.plot(x, poly.evaluate(p, x), 'b')
plt.show()
plt.plot(x_test, y_test, 'k')
plt.plot(x_test, y_test_pred, 'r')
plt.show()
plt.plot(x_test, y_test, 'k')
plt.plot(x_test, poly.evaluate(p, x_test), 'b')
plt.show()
1 ответ
Это потому, что деревья решений являются кусочно-постоянными функциями, а Catboost полностью основан на деревьях решений. Таким образом, catboost всегда экстраполирует с константой.
Таким образом, Catboost (и другие основанные на деревьях алгоритмы, такие как XGBoost или все реализации Random Forest) неэффективны при экстраполяции (если вы не выполняете умную разработку функций, которая фактически сама экстраполирует).
В вашем примере, Catboost экстраполирует синус с константой, которая не круто. Но полиномиальная посадка еще хуже: она быстро уходит в бесконечность!
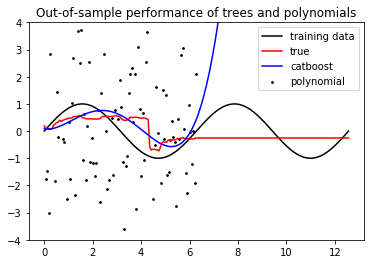
Это полный код, который генерирует картинку:
import numpy as np
func = np.sin
from catboost import Pool, CatBoostRegressor
from numpy.polynomial.polynomial import Polynomial
import matplotlib.pyplot as plt
np.random.seed(1)
x = np.linspace(0, 2*np.pi, 100)
y = func(x) + np.random.normal(0, 3, len(x))
x_test = np.linspace(0*np.pi, 4*np.pi, 200)
y_test = func(x_test)
train_pool = Pool(x.reshape((-1,1)), y)
test_pool = Pool(x_test.reshape((-1,1)))
model = CatBoostRegressor(iterations=100, depth=2, loss_function="RMSE",verbose=False)
model.fit(train_pool, verbose=False)
y_pred = model.predict(x.reshape((-1,1)))
y_test_pred = model.predict(test_pool)
p = np.polyfit(x, y, deg=4)
plt.scatter(x, y, s=3, c='k')
plt.plot(x_test, y_test, 'k')
plt.plot(x_test, y_test_pred, 'r')
plt.plot(x_test, np.polyval(p, x_test), 'b')
plt.title('Out-of-sample performance of trees and polynomials')
plt.legend(['training data', 'true', 'catboost', 'polynomial'])
plt.ylim([-4, 4])
plt.show()